Oracle事务的完整流程的分析精Word文档格式.docx
《Oracle事务的完整流程的分析精Word文档格式.docx》由会员分享,可在线阅读,更多相关《Oracle事务的完整流程的分析精Word文档格式.docx(8页珍藏版)》请在冰豆网上搜索。
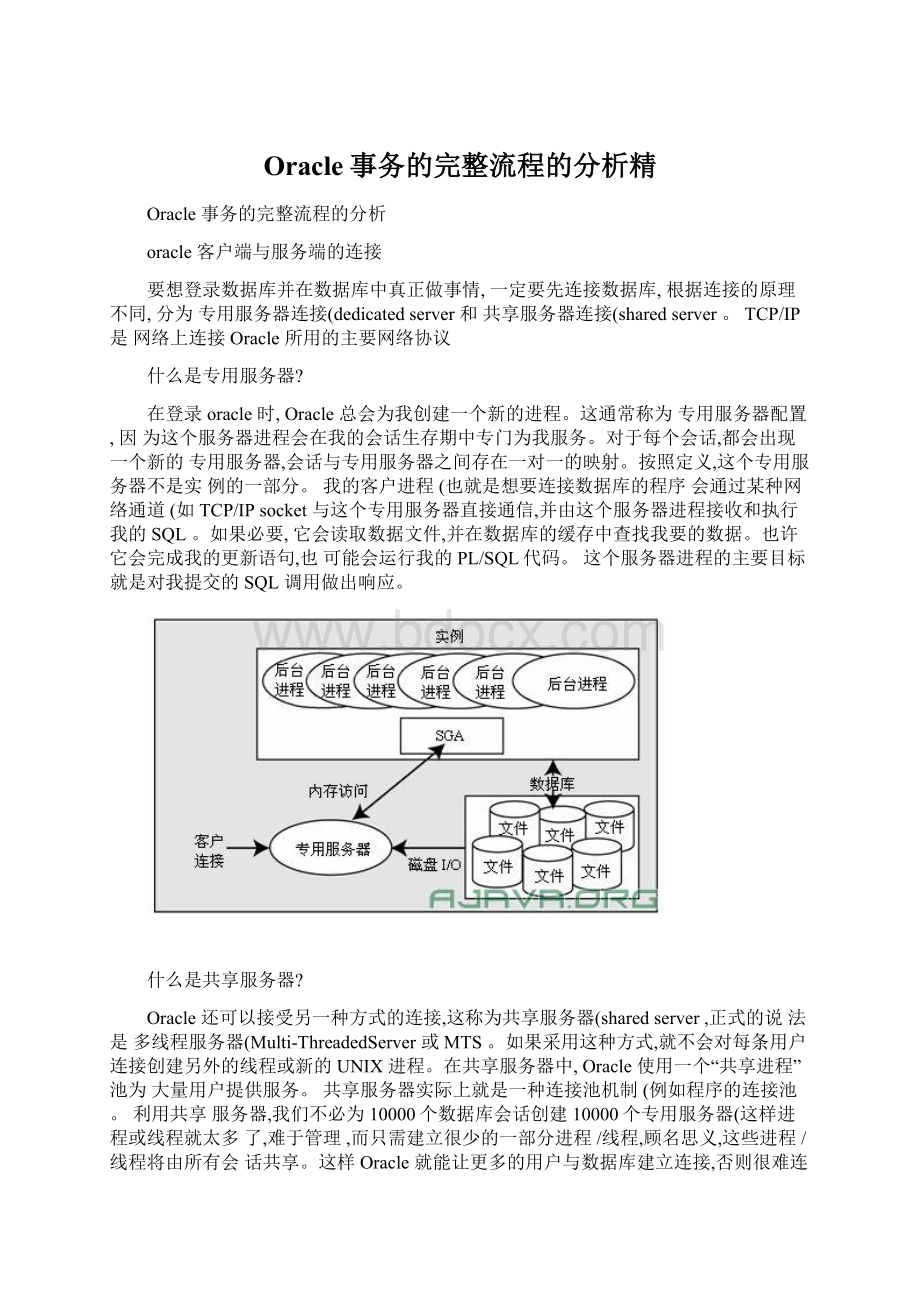
什么是共享服务器?
Oracle还可以接受另一种方式的连接,这称为共享服务器(sharedserver,正式的说法是多线程服务器(Multi-ThreadedServer或MTS。
如果采用这种方式,就不会对每条用户连接创建另外的线程或新的UNIX进程。
在共享服务器中,Oracle使用一个“共享进程”池为大量用户提供服务。
共享服务器实际上就是一种连接池机制(例如程序的连接池。
利用共享服务器,我们不必为10000个数据库会话创建10000个专用服务器(这样进程或线程就太多了,难于管理,而只需建立很少的一部分进程/线程,顾名思义,这些进程/线程将由所有会话共享。
这样Oracle就能让更多的用户与数据库建立连接,否则很难连接更多用户。
如果让我的机器管理10000个进程,这个负载肯定会把它压垮,但是管理100个或者1000个进程还是可以的。
采用共享服务器模式,共享进程通常与数据库一同启动,使用ps命令可以看到这个进程。
共享服务器连接和专用服务器连接之间有一个重大区别,与数据库连接的客户进程不会与共享服务器直接通信,但专用服务器则不然,客户进程会与专用服务器直接通信。
之所以不能与共享服务器直接对话,原因就在于这个服务器进程是共享的。
为了共享这些进程,还需要另外一种机制,通过这种机制才能与共享服务器进程“对话”。
为此,Oracle使用了一个或一组称为调度器(dispatcher,也称分派器的进程。
客户进程通过网络与一个调度器进程通信。
这个调度器进程将客户的请求放入SGA中UGA中的请求队列(这也是SGA的用途之一。
第一个空闲的共享服务器会得到这个请求,并进行处理(例如,请求可能是UPDATETSETX=X+5WHEREY=2。
完成这个命令后,共享服务器会把响应放在原调度器(即接收请求的调度器的响应队列中。
调度器进程一直在监听这个队列,发现有结果后,就会把结果传给客户。
一.oracle客户端与服务端的连接
首先一个用户进程发出一个连接请求,如果使用的是主机命名或者是本地服务命中的主机名使用的是机器名(非IP地址,那么这个请求都会通过DNS服务器或HOST文件的服务名解析然后传送到ORACLE监听进程,监听进程接收到用户请求后会采取两种方式来处理这个用户请求。
C:
/DocumentsandSettings/Administrator>
sqlplussys/aibo@testassysdba
SQL*Plus:
Release10.2.0.4.0-Productionon星期一8月1610:
51:
152010
Copyright(c1982,2007,Oracle.AllRightsReserved.
连接到:
OracleDatabase10gEnterpriseEditionRelease10.2.0.4.0-Production
WiththePartitioning,OLAP,DataMiningandRealApplicationTestingoptions
SQL>
sys/aibo是用户名密码,test是TNS服务名,TNS代表透明网络底层(TransparentNetworkSubstrate,这是Oracle客户端处理远程连接的“基础”软件,有了它才有可能建立对等通信。
TNS连接串告诉Oracle软件如何与远程数据库连接。
一般地,你的机器上运行的客户软件会读取一个tnsnames.ora文件。
这是一个纯文本的配置文件,内容例如:
TEST=
(DESCRIPTION=
(ADDRESS=(PROTOCOL=TCP(HOST=192.168.2.10(PORT=1521
(CONNECT_DATA=
(SERVER=DEDICATED
(SERVICE_NAME=test
Oracle客户端软件可以从tns连接串TEST得到有用的信息,也就是主机名,主机监听的端口号,主机所连接的数据库服务名,服务名表示具有公共属性、服务级阈值和优先级的应用组。
提供服务的实例数量对应用是透明的,每个数据库实例可以向监听器注册,表示要提供多个服务。
所以,服务就映射到物理的数据库实例,并允许DBA为之关联阈值和优先级。
现在oracle客户端通过tns连接串可以知道要连接到哪里,他会与主机(HOST=192.168.2.10在端口,打开一条tcp/ipsocket连接;
如果服务端恰好配置了oraclenet,并且有一个监听进程在1521端口监听连接请求,就会受到这个连接请求。
在网络环境中,我们会一个tns监听进程,就是这个监听进程可以让我们客户端与服务器物理连接。
当他接受到这个请求后,会根据自己的配置文件处理这个请求连接,可能会拒绝请求(例如,因为没有这样的数据库,或者可能我们的IP地址受到限制,不允许连接这个主机,也可能会接受请求,并真正建立连接。
专用服务器模式下:
监听进程接收到用户进程请求后,产生一个新的专用服务器进程,(在UNIX上,这是通过fork(和exec(系统调用做到的(在UNIX中,要在初始化之后创建新进程,惟一的办法就是通过fork(;
在Windows上,监听器进程请求数据库进程为连接创建一个新线程。
一旦创建了这个线程,客户就会“重定向”到该线程,相应地就能建立物理连接。
并且将对用户进程的所有控制信息传给此服务器进程,也就是说新建的服务器进程继承了监听进程的信息,然后服务器进程给用户进程发一个RESEND包,通知用户进程可以开始给它发信息了,用户进程给这个新建的服务器进程发一个CONNECT包,服务器进程再以
ACCEPT包回应用户进程,致此,用户进程正式与服务器进程确定连接,我们把这种连接叫做HAND-OFF连接,也叫转换连接.
另一种方式是监听进程接收到用户进程的请求后产生一个新的专用服务器进程,这个服务器进程选用一个TCP/IP端口来控制与用户进程的交互,然后将此信息回传给监听进程,监听进程再将此信息传给用户进程,用户进程使用这个端口给服务器进程发送一个CONNECT包,服务器进程再给用户进程发送一个ACCEPT包,致此,用户进程可以正式向服务器进程发送信息了。
这种方式我们叫做重定向连接。
HAND-OFF连接需要系统平台具有进程继承的能力,为了使WINDOWSNT/2000支持HAND-OFF必须在
HKEY_LOCAL_MACHINE>
SOFTWARE>
ORACLE>
HOMEX中设置USE_SHARED_SOCKET。
共享服务器模式下:
只有重定向连接的方式,工作方式是监听进程接收到用户进程的请求后产生一个新的调度进程,这个调度进程选用一个TCP/IP端口来控制与用户进程的交互,然后将此信息回传给监听进程,监听进程再将此信息传给用户进程,用户进程使用这个端口给调度进程发送一个CONNECT包,调度进程再给用户进程发送一个ACCEPT包,致此,用户进程可以正式向调度进程发送信息了。
可以通过设置MAX_DISPIATCHERS这个参数来确定调度进程的最大数目,如果调度进程的个数已经达到了最大,或者已有的调度进程不是满负荷,监听进程将不再创建新的调度进程,而是让其中一个调度进程选用一个TCP/IP端口来与此用户进程交互。
调度进程每接收一个用户进程请求都会在监听进程处作一个登记,以便监听进程能够均衡每个调度进程的负荷,所有的用户进程请求将分别在有限的调度进程中排队,所有调度进程再顺序的把各自队列中的部分用户进程请求放入同一个请求队列,等候多个ORACLE的共享服务器进程进行处理(可以通过SHARED_SERVERS参数设置共享服务器进程的个数,也就是说所有的调度进程共享同一个请求队列,共享服务器模式下一个实例只有一个请求队列,共享服务器进程处理完用户
进程的请求后将根据用户进程请求取自不同的调度进程将返回结果放入不同的响应队列,也就是说有多少调度进程就有多少响应队列,然后各个调度进程从各自的响应队列中将结果取出再返回给用户进程。
到目前为止,用户进程已经把需要执行的sql提交到oracle的服务进程,那oracle是如何处理这个进程的呢?
oracle服务进程如何处理用户进程的请求
服务器进程在完成用户进程的请求过程中,主要完成如下7个任务:
0.sql语句的解析
1.数据块的读入dbbuffer
2.记日志
3.为事务建立回滚段
4.本事务修改数据块
5.放入dirtylist
6.用户commit或rollback
下面要讲oracle服务器进程如可处理用户进程的请求,当一用户进程提交一个sql时:
updatetempseta=a*2;
首先oracle服务器进程从用户进程把信息接收到后,在PGA中就要此进程分配所需内存,存储相关的信息,如在会话内存存储相关的登录信息等;
服务器进程把这个sql语句的字符转化为ASCII等效数字码,接着这个ASCII码被传递给一个HASH函数,并返回一个hash值,然后服务器进程将到sharedpool中的librarycache中去查找是否存在相同的hash值,如果存在,服务器进程将使用这条语句已高速缓存在SHAREDPOOL的librarycache中的已分析过的版本来执行,如果不存在,服务器进程将在CGA中,配合
UGA内容对sql,进行语法分析,首先检查语法的正确性,接着对语句中涉及的表,索引,视图等对象进行解析,并对照数据字典检查这些对象的名称以及相关结构,并根据ORACLE选用的优化模式以及数据字典中是否存在相应对象的统计数据和是否使用了存储大纲来生成一个执行计划或从存储大纲中选用一个执行计划,然后再用数据字典核对此用户对相应对象的执行权限,最后生成一个编译代码。
ORACLE将这条sql语句的本身实际文本、HASH值、编译代码、与此语名相关联的任何统计数据和该语句的执行计划缓存在SHAREDPOOL的librarycache中。
服务器进程通过SHAREDPOOL锁存器(sharedpoollatch来申请可以向哪些共享PL/SQL区中缓存这此内容,也就是说被SHAREDPOOL锁存器锁定的PL/SQL区中的块不可被覆盖,因为这些块可能被其它进程所使用。
在SQL分析阶段将用到LIBRARYCACHE,从数据字典中核对表、视图等结构的时候,需要将数据字典从磁盘读入LIBRARYCACHE,因此,在读入之前也要使用LIBRARYCACHE锁存器(librarycachepin,librarycachelock来申请用于缓存数据字典。
到现在为止,这个sql语句已经被编译成可执行的代码了,但还不知道要操作哪些数据,所以服务器进程还要为这个sql准备预处理数据。
Oracle处理数据,都需要把数据读取到内存中(即dbbuffer中,首先服务器进程要判断所需数据是否在dbbuffer存在,如果存在且可用,则直接获取该数据,同时根据LRU算法增加其访问计数;
如果buffer不存在所需数据,则要从数据文件上读取。
首先服务器进程将在表头部请求TM锁(保证此事务执行过程其他用户不能修改表的结构,如果成功加TM锁,再请求一些行级锁(TX锁,如果TM、TX锁都成功加锁,那么才开始从数据文件读数据,在读数据之前,要先为读取的文件准备好buffer空间。
服务器进程需要扫面LRUlist寻找
freedbbuffer,扫描的过程中,服务器进程会把发现的所有已经被修改过的dbbuffer注册到dirtylist中,
这些dirtybuffer会通过dbwr的触发条件,随后会被写出到数据文件,找到了足够的空闲buffer,就可以把请求的数据行所在的数据块放入到dbbuffer的空闲区域或者覆盖已经被挤出LRUlist的非脏数据块缓冲区,并排列在LRUlist的头部,也就是在数据块放入DBBUFFER之前也是要先申请dbbuffer中的锁存器,成功加锁后,才能读数据到dbbuffer。
2.记日志
现在数据已经被读入到dbbuffer了,现在服务器进程将该语句所影响的并被读入dbbuffer中的这些行数据的rowid及要更新的原值和新值及scn等信息从PGA逐条的写入redologbuffer中。
在写入redologbuffer之前也要事先请求redologbuffer的锁存器,成功加锁后才开始写入,当写入达到redologbuffer大小的三分之一或写入量达到1M或超过三秒后或发生检查点时或者dbwr之前发生,都会触发lgwr进程把redologbuffer的数据写入磁盘上的redofile文件中(这个时候会产生logfilesync等待事件,已经被写入redofile的redologbuffer所持有的锁存器会被释放,并可被后来的写入信息覆盖,redologbuffer是循环使用的。
Redofile也是循环使用的,当一个redofile写满后,lgwr进程会自动切换到下一redofile(这个时候可能出现logfileswitch(checkpointcomplete等待事件。
如果是归档模式,归档进程还要将前一个写满的redofile文件的内容写到归档日志文件中(这个时候可能出现logfileswitch(archivingneeded。
3.为事务建立回滚段
在完成本事务所有相关的redologbuffer之后,服务器进程开始改写这个dbbuffer
的块头部事务列表并写入scn,然后copy包含这个块的头部事务列表及scn信息的数据副本放入回滚段中,将这时回滚段中的信息称为数据块的“前映像“,这个”前映像“用于以后的回滚、恢复和一致性读。
(回滚段可以存储在专门的回滚表空间中,这个表空间由一个或多个物理文件组成,并专用于回滚表空间,回滚段也可在其它表空间中的数据文件中开辟。
4.本事务修改数据块
准备工作都已经做好了,现在可以改写dbbuffer块的数据内容了,并在块的头部写入回滚段的地址。
如果一个行数据多次update而未commit,则在回滚段中将会有多个“前映像“,除了第一个”前映像“含有scn信息外,其他每个“前映像“的头部都有scn信息和“前前映像”回滚段地址。
一个update只对应一个scn,然后服务器进程将在dirtylist中建立一条指向此dbbuffer块的指针(方便dbwr进程可以找到dirtylist的dbbuffer数据块并写入数据文件中。
接着服务器进程会从数据文件中继续读入第二个数据块,重复前一数据块的动作,数据块的读入、记日志、建立回滚段、修改数据块、放入dirtylist。
当dirtyqueue的长度达到阀值(一般是25%,服务器进程将通知dbwr把脏数据写出,就是释放dbbuffer上的锁存器,腾出更多的freedbbuffer。
前面一直都是在说明oracle一次读一个数据块,其实oracle可以一次读入多个数据块(db_file_multiblock_read_count来设置一次读入块的个数
说明:
在预处理的数据已经缓存在dbbuffer或刚刚被从数据文件读入到dbbuffer中,就要根据sql语句的类型来决定接下来如何操作。
1>
.如果是select语句,则要查看dbbuffer块的头部是否有事务,如果有事务,则从回滚段中读取数据;
如果没有事务,则比较select的scn和dbbuffer块头部的scn,如果前者小于后者,仍然要从回滚段中读取数据;
如果前者大于后者,说明这是一非脏缓存,可以直接读取这个dbbuffer块的中内容。
2>
.如果是DML操作,则即使在dbbuffer中找到一个没有事务,而且SCN比自己小的非脏缓存数据块,服务器进程仍然要到表的头部对这条记录申请加锁,加锁成功才能进行后续动作,如果不成功,则要等待前面的进程解锁后才能进行动作(这个时候阻塞是tx锁阻塞。
6.用户commit或rollback
到现在为止,数据已经在dbbuffer或数据文件中修改完成,但是否要永久写到数文件中,要由用户来决定commit(保存更改到数据文件和rollback(撤销数据的更改,下面来看看在commit和rollback时,oracle都在做什么。
用户执行commit命令
只有当sql语句所影响的所有行所在的最后一个块被读入dbbuffer并且重做信息被写入redologbuffer(仅指日志缓冲区,而不包括日志文件之后,用户才可以发去commit命令,commit触发lgwr进程,但不强制立即dbwr来释放所有相应dbbuffer块的锁(也就是no-force-at-commit,即提交不强制写,也就是说有可能虽然已经commit了,但在随后的一段时间内dbwr还在写这条sql语句所涉及的数据块。
表头部的行锁并不在commit之后立即释放,而是要等dbwr进程完成之后才释放,这就可能会出现一个用户请求另一用户已经commit的资源不成功的现象。
A.从Commit和dbwr进程结束之间的时间很短,如果恰巧在commit之后,dbwr未结束之前断电,因为commit之后的数据已经属于数据文件的内容,但这部分文件没有完全写入到数据文件中。
所以需要前滚。
由于commit已经触发lgwr,这些所有未来得及写入数据文件的更改会在实例重启后,由smon进程根据重做日志文件来前滚,完成之前commit未完成的工作(即把更改写入数据文件)。
B.如果未commit就断电了,因为数据已经在dbbuffer更改了,没有commit,说明这部分数据不属于数据文件,由于dbwr之前触发lgwr(也就是只要数据更改,肯定要先有log),所有DBWR在数据文件上的修改都会被先一步记入重做日志文件,实例重启后,SMON进程再根据重做日志文件来回滚。
其实smon的前滚回滚是根据检查点来完成的,当一个全部检查点发生的时候,首先让LGWR进程将redologbuffer中的所有缓冲(包含未提交的重做信息)写入重做日志文件,然后让dbwr进程将dbbuffer已提交的缓冲写入数据文件(不强制写未提交的)。
然后更新控制文件和数据文件头部的SCN,表明当前数据库是一致的,在相邻的两个检查点之间有很多事务,有提交和未提交的。
像前面的前滚回滚比较完整的说法是如下的说明:
A.发生检查点之前断电,并且当时有一个未提交的改变正在进行,实例重启之后,SMON进程将从上一个检查点开始核对这个检查点之后记录在重做日志文件中已提交的和未提交改变,因为dbwr之前会触发lgwr,所以dbwr对数据文件的修改一定会被先记录在重做日志文件中。
因此,断电前被DBWN写进数据文件的改变将通过重做日志文件中的记录进行还原,叫做回滚,
B.如果断电时有一个已提交,但dbwr动作还没有完全完成的改变存在,因为已经提交,提交会触发lgwr进程,所以不管dbwr动作是否已完成,该语句将要影响的行及其产生的结果一定已经记录在重做日志文件中了,则实例重启后,SMON进程根据重做日志文件进行前滚实例失败后用于恢复的时间由两个检查点之间的间隔大小来决定,可以通个四个参数设置检查点执行的频率:
Log_checkpoint_interval:
决定两个检查点之间写入重做日志文件的系统物理块(redoblocks的大小,默认值是0,无限制log_checkpoint_timeout:
决定了两个检查点之间的时间长度(秒),默认值是1800sfast_start_io_target:
决定了用于恢复时需要处理的块的多少,默认值是0,无限制fast_start_mttr_target:
直接决定了用于恢复的时间的长短,默认值是0,无限制(SMON进程执行的前滚和回滚与用户的回滚是不同的,SMON是根据重做日志文件进行前滚或回滚,而用户的回滚一定是根据回滚段的内容进行回滚的。
在这里要说一下回滚段存储的数据,假如是delete操作,则回滚段将会记录整个行的数据,假如是update,则回滚段只记录被修改了的字段的变化前的数据(前映像),也就是没有被修改的字段是不会被记录的,假如是insert,则回滚段只记录插入记录的rowid。
这样假如事务提交,那回滚段中简单标记该事务已经提交;
假如是回退,则如果操作是delete,回退的时候把回滚段中数据重新写回数据块,操作如果是update,则把变化前数据修改回去,操作如果是insert,则根据记录的rowid把该记录删除。
)用户执行rollback如果用户rollback,则服务器进程会根据数据文件块和DBBUFFER中块的头部的事务列表和SCN以及回滚段地址找到回滚段中相应的修改前的副本,并且用这些原值来还原当前
数据文件中已修改
 升级会员
升级会员 