spss样本聚类案例分析.docx
《spss样本聚类案例分析.docx》由会员分享,可在线阅读,更多相关《spss样本聚类案例分析.docx(22页珍藏版)》请在冰豆网上搜索。
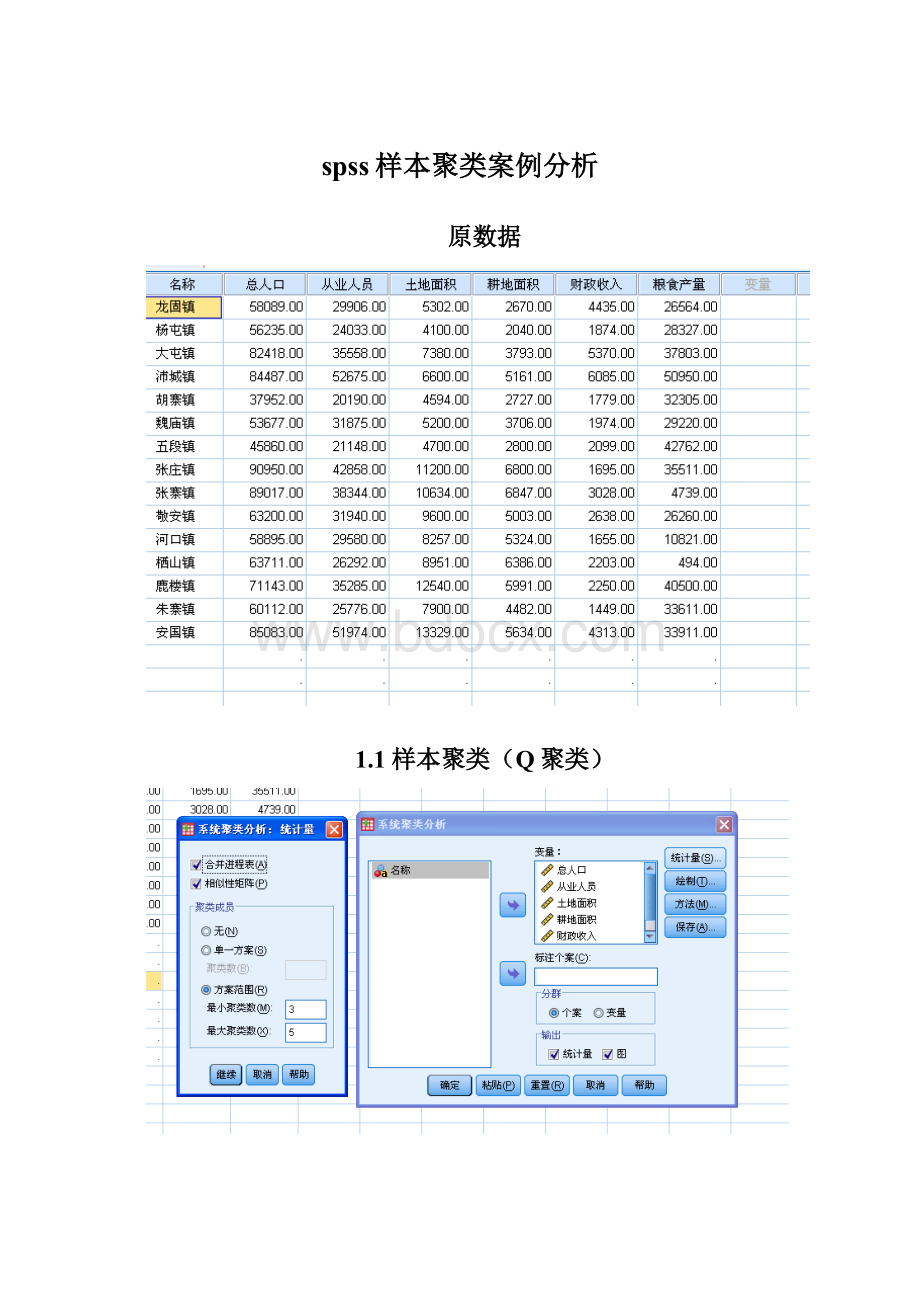
spss样本聚类案例分析
原数据
1.1样本聚类(Q聚类)
聚类表
阶
群集组合
系数
首次出现阶群集
下一阶
群集1
群集2
群集1
群集2
1
5
7
.855
0
0
3
2
11
12
1.379
0
0
7
3
2
5
1.772
0
1
5
4
10
14
1.776
0
0
7
5
2
6
2.451
3
0
8
6
8
13
2.772
0
0
10
7
10
11
4.322
4
2
12
8
1
2
4.557
0
5
12
9
3
4
4.895
0
0
13
10
8
15
5.500
6
0
11
11
8
9
7.740
10
0
13
12
1
10
8.314
8
7
14
13
3
8
12.790
9
11
14
14
1
3
16.650
12
13
0
通过系数做出其散点图
群集成员
案例
5群集
4群集
3群集
1:
Case1
1
1
1
2:
Case2
1
1
1
3:
Case3
2
2
2
4:
Case4
2
2
2
5:
Case5
1
1
1
6:
Case6
1
1
1
7:
Case7
1
1
1
8:
Case8
3
3
3
9:
Case9
4
3
3
10:
Case10
5
4
1
11:
Case11
5
4
1
12:
Case12
5
4
1
13:
Case13
3
3
3
14:
Case14
5
4
1
15:
Case15
3
3
3
1.2变量聚类(R聚类)
近似矩阵
案例
矩阵文件输入
总人口
从业人员
土地面积
耕地面积
财政收入
粮食产量
总人口
1.000
.857
.698
.714
.512
.043
从业人员
.857
1.000
.597
.570
.643
.277
土地面积
.698
.597
1.000
.856
.044
-.147
耕地面积
.714
.570
.856
1.000
-.001
-.335
财政收入
.512
.643
.044
-.001
1.000
.342
粮食产量
.043
.277
-.147
-.335
.342
1.000
聚类表
阶
群集组合
系数
首次出现阶群集
下一阶
群集1
群集2
群集1
群集2
1
1
2
.857
0
0
3
2
3
4
.856
0
0
3
3
1
3
.645
1
2
5
4
5
6
.342
0
0
5
5
1
5
.129
3
4
0
群集成员
案例
5群集
4群集
3群集
总人口
1
1
1
从业人员
1
1
1
土地面积
2
2
1
耕地面积
3
2
1
财政收入
4
3
2
粮食产量
5
4
3
2.K—均值聚类
原数据
描述统计量
N
极小值
极大值
均值
标准差
身高月平均增长率
19
.34
11.03
1.8842
2.56342
体重月平均增长率
19
.49
50.30
5.6363
11.71814
胸围月平均增长率
19
.16
11.81
1.4958
2.79339
坐高月平均增长率
19
.14
11.27
1.7111
2.80709
有效的N(列表状态)
19
输出结果:
初始聚类中心
聚类
1
2
3
4
5
Zscore(身高月平均增长率)
3.56781
1.39883
.66153
.04907
-.60240
Zscore(体重月平均增长率)
3.81150
1.16603
.35959
-.12513
-.43918
Zscore(胸围月平均增长率)
3.69236
1.32606
.58861
-.00923
-.47104
Zscore(坐高月平均增长率)
3.40529
1.94826
.14212
-.04669
-.55255
迭代历史记录a
迭代
聚类中心内的更改
1
2
3
4
5
1
.000
.000
.000
.208
.183
2
.000
.000
.000
.000
.000
a.由于聚类中心内没有改动或改动较小而达到收敛。
任何中心的最大绝对坐标更改为.000。
当前迭代为2。
初始中心间的最小距离为.996。
聚类成员
案例号
月份
聚类
距离
dimension0
1
1
1
.000
2
2
2
.000
3
3
3
.000
4
4
4
.208
5
6
4
.258
6
8
4
.312
7
10
4
.194
8
12
5
.297
9
15
5
.245
10
18
5
.065
11
24
5
.070
12
30
5
.112
13
36
5
.045
14
42
5
.119
15
48
5
.051
16
54
5
.103
17
60
5
.166
18
66
5
.074
19
72
5
.183
20
.
.
.
21
.
.
.
22
.
.
.
23
.
.
.
24
.
.
.
25
.
.
.
最终聚类中心
聚类
1
2
3
4
5
Zscore(身高月平均增长率)
3.56781
1.39883
.66153
.02859
-.47855
Zscore(体重月平均增长率)
3.81150
1.16603
.35959
-.19084
-.38115
Zscore(胸围月平均增长率)
3.69236
1.32606
.58861
-.20255
-.39974
Zscore(坐高月平均增长率)
3.40529
1.94826
.14212
-.01106
-.45429
最终聚类中心间的距离
聚类
1
2
3
4
5
1
4.407
6.375
7.442
8.099
2
4.407
2.236
3.146
3.830
3
6.375
2.236
1.163
1.784
4
7.442
3.146
1.163
.727
5
8.099
3.830
1.784
.727
ANOVA
聚类
误差
F
Sig.
均方
df
均方
df
Zscore(身高月平均增长率)
4.469
4
.009
14
500.431
.000
Zscore(体重月平均增长率)
4.476
4
.007
14
662.430
.000
Zscore(胸围月平均增长率)
4.455
4
.013
14
346.563
.000
Zscore(坐高月平均增长率)
4.472
4
.008
14
563.652
.000
F检验应仅用于描述性目的,因为选中的聚类将被用来最大化不同聚类中的案例间的差别。
观测到的显著性水平并未据此进行更正,因此无法将其解释为是对聚类均值相等这一假设的检验。
每个聚类中的案例数
聚类
1
1.000
2
1.000
3
1.000
4
4.000
5
12.000
有效
19.000
缺失
6.000
3.线性回归
研究变量间的非确定性关系,构造变量间经验公式的数理统计方法称为回归分析。
根据自变量的个数,分为一元线性回归和多元线性回归。
3.1一元线性回归
原数据
输入/移去的变量b
模型
输入的变量
移去的变量
方法
1
咖啡类饮料销售量,固体冲泡饮料销售量,茶饮料销售量,碳酸饮料销售量a
.
输入
a.已输入所有请求的变量。
b.因变量:
果汁销售量
模型汇总
模型
R
R方
调整R方
标准估计的误差
1
.997a
.994
.992
.44012
a.预测变量:
(常量),咖啡类饮料销售量,固体冲泡饮料销售量,茶饮料销售量,碳酸饮料销售量。
Anovab
模型
平方和
df
均方
F
Sig.
1
回归
338.056
4
84.514
436.306
.000a
残差
1.937
10
.194
总计
339.993
14
a.预测变量:
(常量),咖啡类饮料销售量,固体冲泡饮料销售量,茶饮料销售量,碳酸饮料销售量。
b.因变量:
果汁销售量
系数a
模型
非标准化系数
标准系数
t
Sig.
B
标准误差
试用版
1
(常量)
17.296
.470
36.830
.000
碳酸饮料销售量
.043
.018
.170
2.427
.036
茶饮料销售量
.265
.021
.726
12.852
.000
固体冲泡饮料销售量
-.004
.034
-.009
-.117
.909
咖啡类饮料销售量
-.238
.013
-.455
-18.640
.000
a.因变量:
果汁销售量
3.2多元线性回归
原数据
输出结果:
输入/移去的变量b
模型
输入的变量
移去的变量
方法
1
X4,X1,X2,X3a
.
输入
a.已输入所有请求的变量。
b.因变量:
Y
模型汇总b
模型
R
R方
调整R方
标准估计的误差
1
.894a
.799
.726
.619
a.预测变量:
(常量),X4,X1,X2,X3。
b.因变量:
Y
Anovab
模型
平方和
df
均方
F
Sig.
1
回归
16.779
4
4.195
10.930
.001a
残差
4.221
11
.384
总计
21.000
15
a.预测变量:
(常量),X4,X1,X2,X3。
b.因变量:
Y
 升级会员
升级会员 