决策树算法总结Word文件下载.docx
《决策树算法总结Word文件下载.docx》由会员分享,可在线阅读,更多相关《决策树算法总结Word文件下载.docx(14页珍藏版)》请在冰豆网上搜索。
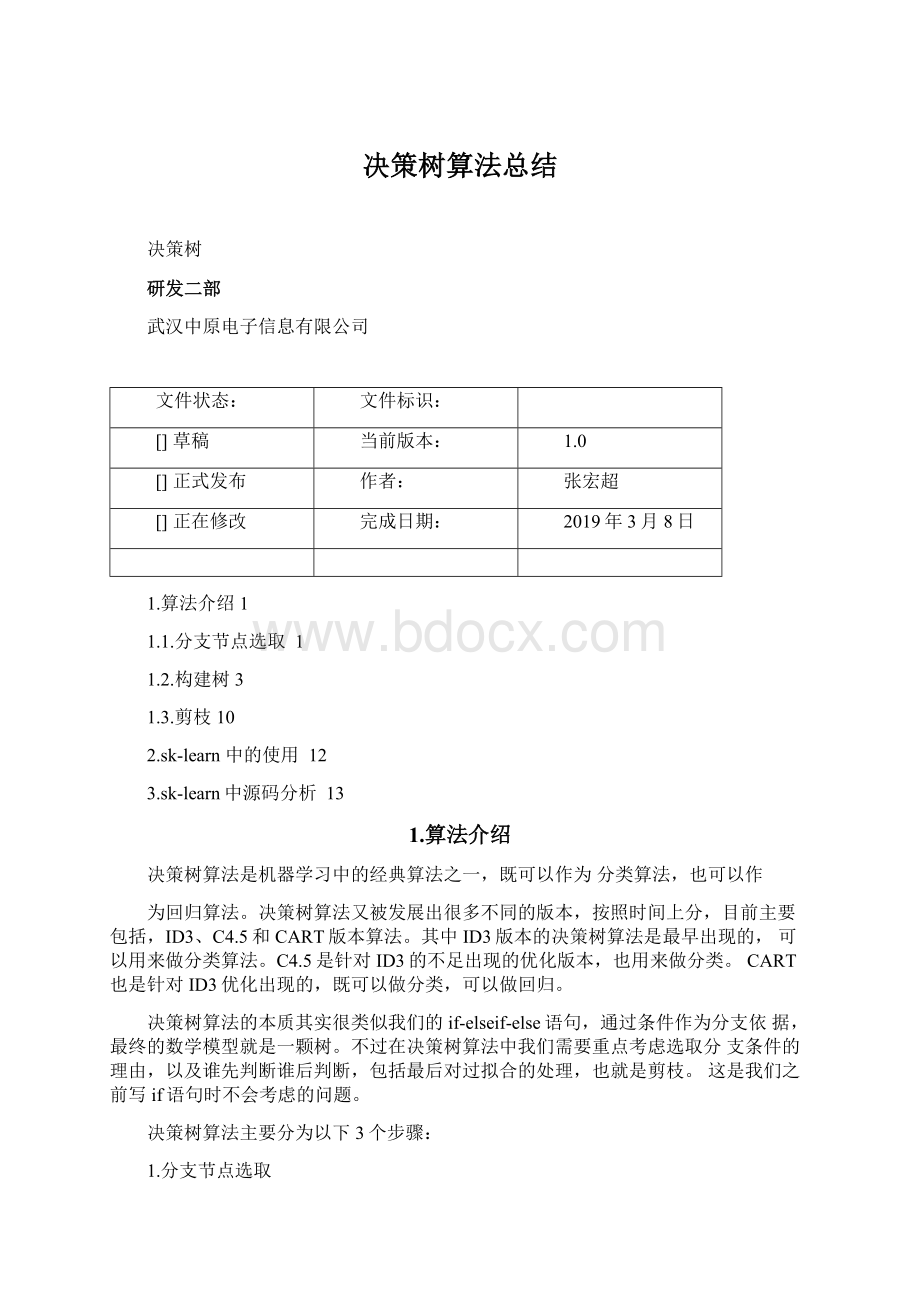
既然要寻找最优,那么必须要有一个衡量标准,也就是需要量化这个优劣性。
常用的衡量指标有熵和基尼系数。
熵:
熵用来表示信息的混乱程度,值越大表示越混乱,包含的信息量也就越多。
比如,A班有10个男生1个女生,B班有5个男生5个女生,那么B班的熵值就比A班大,也就是B班信息越混乱。
Entropy=-Vp”
基尼系数:
同上,也可以作为信息混乱程度的衡量指标。
Gini=1-p:
l-L
有了量化指标后,就可以衡量使用某个分支条件前后,信息混乱程度的收敛效果了。
使用分支前的混乱程度,减去分支后的混乱程度,结果越大,表示效果越好。
#计算熵值
defentropy(dataSet):
tNum=len(dataSet)
print(tNum)
#用来保存标签对应的个数的,比如,男:
6,女:
5
labels={}
fornodeindataSet:
curL=node[-1]#获取标签
ifcurLnotinlabels.keys():
labels[curL]=0#如果没有记录过该种标签,就记录并初始化为0
labels[curL]+=1#将标签记录个数加1
#此时labels中保存了所有标签和对应的个数
res=0
#计算公式为-p*logp,p为标签出现概率
fornodeinlabels:
p=float(labels[node])/tNum
res-=p*log(p,2)
returnres
#计算基尼系数
defgini(dataSet):
curL=node[-1]#获取标签
#此时labels中保存了所有标签和对应的个数
res=1
#计算公式为-p*logp,p为标签出现概率
p=float(labels[node])/tNum
res-=p*p
1.2.构建树
ID3算法:
利用信息熵增益,决定选取哪个特征作为分支节点。
分支前的总样本熵值-分支后的熵值总和=信息熵增益。
T1的信息熵增益:
1-13/20*0.961-7/20*0.863=0.073
T2的信息熵增益:
1-12/20*0.812-8/20*0.544=0.295
所以使用T2作为分支特征更优
ID3算法建树:
依据前面的逻辑,递归寻找最优分支节点,直到下面情况结束
1.叶节点已经属于同一标签
2.虽然叶节点不属于同一标签,但是特征已经用完了
3.熵小于预先设置的阈值
4.树的深度达到了预先设置的阈值
ID3算法的不足:
1.取值多的特征比取值少的特征更容易被选取。
2.不包含剪枝操作,过拟合严重
3.特征取值必须是离散的,或者有限的区间的。
于是有了改进算法C4.5
C4.5算法:
基于ID3算法进行了改进,首先,针对ID3的不足1,采用信息增益率取代ID3中使用信息增益而造成的偏向于选取取值较多的特征作为分裂点的问题。
针对ID3的不足2,采用剪枝操作,缓解过拟合问题。
针对ID3的不足3,采用将连续值先排列,然后逐个尝试分裂,找到连续值中的最佳分裂点。
信息增益率的计算:
先计算信息增益,然后除以splitelnfo。
spliteInfo为分裂后的子集合的函数,假设分裂后的子集合个数为subl和sub2,total为分裂前的个数。
spliteInfo=-sub1/total*Iog(sub1/total)-sub2/total*Iog(sub2/total)
#index:
特征序号
#value:
特征值
#该方法表示将index对应特征的值为value的集合返回,返回集合中不包含index对应的特征
defspliteDataSet(dataSet,index,value):
newDataSet=[]
ifnode[index]==value:
#[0,index)列的数据
newData=node[:
index]
#[index+1,最后]列的数据
newData.extend(node[index+1:
])
newDataSet.append(newData)
returnnewDataSet;
#选择最优分裂项
defchooseBestFeature(dataSet):
#特征个数
featureNum=len(dataSet[0])-1
#计算整体样本的熵值
baseEntropy=entropy(dataSet)
4
print("
baseEntropy=%f"
%(baseEntropy))
#保存最大的信息增益率
maxinfoGainRatio=0.0
bestFeatureld=-1
foriinrange(featureNum):
#获取特征所有可能的值
featureValues=[]
featureValues.append(node[i])
print(featureValues)
#将特征值去除重复
uniqueFeatureValues=set(featureValues)
print(uniqueFeatureValues)
#按照i特征分裂之后的熵值
newEntropy=0.0
#分裂信息
spliteinfo=0.0
#按照i所表示的特征,开始分裂数据集
forvalueinuniqueFeatureValues:
#当i属性等于value时的分裂结果
subDataSet=spliteDataSet(dataSet,i,value)
print(subDataSet)
#计算占比
p=float(len(subDataSet))/float(len(dataSet))
newEntropy+=p*entropy(subDataSet)
spliteinfo+=-p*log(p,2)
#计算信息增益
infoGain=baseEntropy-newEntropy
#计算信息增益率
ifspliteInfo==0:
continue
infoGainRatio=infoGain/spliteinfo
ifinfoGainRatio>
maxlnfoGainRatio:
maxlnfoGainRatio=infoGainRatio
bestFeatureld=i
returnbestFeatureld
C4.5算法的不足:
1.如果存在连续值的特征需要做排序等处理,计算比较耗时
2.只能用于分类使用
于是有了CART算法
CART算法:
也是基于ID3算法优化而来,支持分类和回归,使用基尼系数(分类树)或者均方差(回归树)替代熵的作用,减少运算难度。
使用二叉树代替多叉树建模,降低复杂度。
基尼系数的计算:
EC/
均方差的计算:
计算举例,假设有如下数据源
看电视
时间
婚姻情
况
职业
年龄
3
未婚
学生
12
18
2
已婚
老师
26
上班族
47
2.5
36
3.5
29
21
如果将婚否作为标签,该问题是一个分类问题,所以使用基尼系数
假设使用职业作为特征分支,对于看电视和年龄,都是连续数据,需要按照C4.5
的算法排序后处理,这里先分析简单的按照职业开始划分。
又因为,CART算法的建模是二叉树,所以,针对职业来说,有以下组合,学生|
非学生,老师|非老师,上班族|非上班族,到底怎么划分,就要通过基尼系数来判断了。
—3/4*3/4-1/4*1/4)=0.4
(1-2/5*2/5-3/5*3/5)=0.49
5*2/5)=0.34
所以,如果选择职业来划分,那么首先应该按照上班族|非上班族划分
如果将年龄作为标签,该问题是一个回归问题,所以使用均方差
同样,先考虑使用职业来划分
mean=开方(12*12+18*18+21*21-3*17*17)+开方(26*26+47*47+36*36+29*29-5*32.5*32.5)=34.71
其他情况略。
可以看到选择分裂属性这一步骤会比较麻烦,首先要遍历所有特征,找到每一个特征的最优分裂方法,然后在选择最优的分裂特征。
功能
树结构
特征选取
连续值处
理
缺失值处
剪枝
ID3分类
多叉
信息增益
不支持
C4.5分类
信息增益率
支持
CART分类/回归二叉基尼系数(分支持支持支持
类)
,均方差(回
归)
1.3.剪枝
CCP(CostComplexityPruning代价复杂性剪枝法(CART常用)
REP(ReducedErrorPruning错误降低剪枝法
PEP(PessimisticErrorPruning悲观错误剪枝法(C4.5使用)
MEP(MinimumErrorPruning)最小错误剪枝法
这里以CCP为例讲解其原理
CCP选择节点表面误差率增益值最小的非叶子节点,删除该节点的子节点。
若多个非叶子节点的表面误差率增益值相同,则选择子节点最多的非叶子节点进行裁剪。
表面误差率增益值计算:
R(t)表示非叶子节点的错误率,比如,总样本20,在A节点上a类5个,b类2
个,所以可以认为A节点代表的是a类,那么错误率就是2/7*7/20
R(T表示叶子节点的错误率累积和
N(T表示叶子节点的个数剪枝步骤:
1.构建子树序列
2.找到最优子树,作为我们的决策树(交叉验证等)
举例:
t1是根节点
t2,t3,t4,t5是非叶子节点
t6,t7,t8,t9,t10,t11是叶子节点
首先我们计算所有非叶子节点误差率增益值
t4:
(4/50*50/80T/45*45/80-2/5*5/80)/(2T)=0.0125
t5:
(4/10*10/80-0-0)/(2-1)=0.05
t2:
(10/60*60/80-1/45*45/80-2/5*5/80-0-0)/(4-1)=0.0292
t3:
0.0375
因此得到第1颗子树:
T0=t4(0.0125),t5(0.05),t2(0.0292),t3(0.0375)
比较发现可以将t4裁剪掉
得到第2颗子树
0.05
0.0375
(10/60*60/80-4/50*50/80-0-0)/(3-1)=0.0375
此时t2与t3相同,那么裁剪叶子节点较多的,因此t2被裁剪
得到第3颗树
然后对上面3颗子树进行验证,找到效果最后的作为剪枝之后的决策树
2.sk-learn中的使用
fromsklearn.datasetsimportload_iris
fromsklearnimporttree
importpydotplus
importgraphviziris=load_iris()
clf=tree.DecisionTreeClassifier()
clf.fit(iris.data,iris.target)
dot_data=tree.export_graphviz(clf,out_file=None)
graph=pydotplus.graphfromdotdata(dotdata)graph.write_pdf("
iris.pdf"
)
3.sk-learn中源码分析
主要分析tree的相关函数代码,使用pycharm下载sklearn包中tree文件,引用了_tree.pxd,pxd相当于头文件,其实现在_tree.pyd中,pyd是加密文件,无法查看。
从github上下载源码中有_tree.pyx相当于c文件,因此可以查看。
.pxd:
相当于.h
.pyx:
相当于.c
.pyd:
相当于dll
tree.DecisionTreeClassifier()创建分类决策树对象
DecisionTreeClassifie继承BaseDecisionTree
clf.fit(iris.data,iris.target)建树
DecisionTreeClassifier直接使用了父类BaseDecisionTree的方法
super().fit(
X,y,
sample_weight=sample_weight,
check_input=check_input,
X_idx_sorted=X_idx_sorted)
查看DecisionTreeClassifier的fit,学习建树过程
代码前面是对参数的校验之类的工作
#Buildtreecriterion=self・cui匸EEionifnotisinstance(criterion,Criterion):
if:
—
皿:
--ciitexJ-Qn=CKITER1A_REG[self,criterion](s^lf,n_out^uts,n_saniple3)
■■^criterion=CRITERIA'
^LFt^elf,criterionJ(self.r_outp^ts*self*rclasses>
=mt■且mm刁L?
t_2'
rifims匸wr■三三(x)else二巴Km5p_.lt
splitter=self,splitter
ifnotisinatancat_splitter,£
p丄ititer)
^jpTrEter=SPLITTERS[seIf,sp1iTtwJ;
£
criterion,—se1f.ma
minsamplssleaffmir_weight_leaf;
random^statetself.presort)
criterion:
表示选择分裂节点的准则,CLF表示分类使用gini系数、
熵等,REG表示回归使用均方差等。
他们的定义在
criteria_clf■I"
rfir;
11:
_crirerion.Ginit'
rtrr.fy"
:
_criterion.Entropy}
3CRITERlA_REG■{"
mse"
:
_ariterion.MSEFiLdmajQ_mj=c1h:
criterion*FriedmanMSE,
"
m"
:
elite上ictrl.MAE)
对于这些准则的计算,在_criterion.Gini或者其他文件中实现,使
用Cpython实现的。
以Gini的计算为例
cdefdaublenoti**_impErity(self)nogi1:
w"
Evaluatetheimpurityofthecurrentnede,i.m*theimpurityoffdcimples[std£
t;
«
nd]kifiinqttwjGinicriterian,"
^1'
udef
SIZE_t*
elclasses
=self・nclasses
■zdef
dcuble*
sumrotal
=self.sunntotal
dcutle
ffinl=0+0
cdef
double
sqcount
countk
SIZE_C
k
3ISE_t
c
forkJinr^rige<
5el£
.n_outpci七s):
—0.□
forcxr匸口口(n_clas5e5fk]);
crount_k=3Ljm七otal[c]
sq^count+-countk*countk
qini卜・1T03q_count/[self.weighted_n_nodcsamples
del£
.r;
yijhLe<
l_ii_fli>
de_tidunples)
suirtotaJ+=self,sum_s,ctLcle
retEirTLcpdrii/5If.nantpu七汙
同理,分裂的规则定义在splitter中,具体实现也是在Cpython中
最后是构造器,这也是面向对象设计模式中的一种设计模式,构造器模式。
思想是,构造器中根据加入的原料,产出不同的东西。
builder=DepthFirstTreeBuilder(优先深度)
builder=BestFirstTreeBuilder(优先最优)他们的代码实现在_tree.pyx中
 升级会员
升级会员 