算法设计B10040101Word文档下载推荐.docx
《算法设计B10040101Word文档下载推荐.docx》由会员分享,可在线阅读,更多相关《算法设计B10040101Word文档下载推荐.docx(21页珍藏版)》请在冰豆网上搜索。
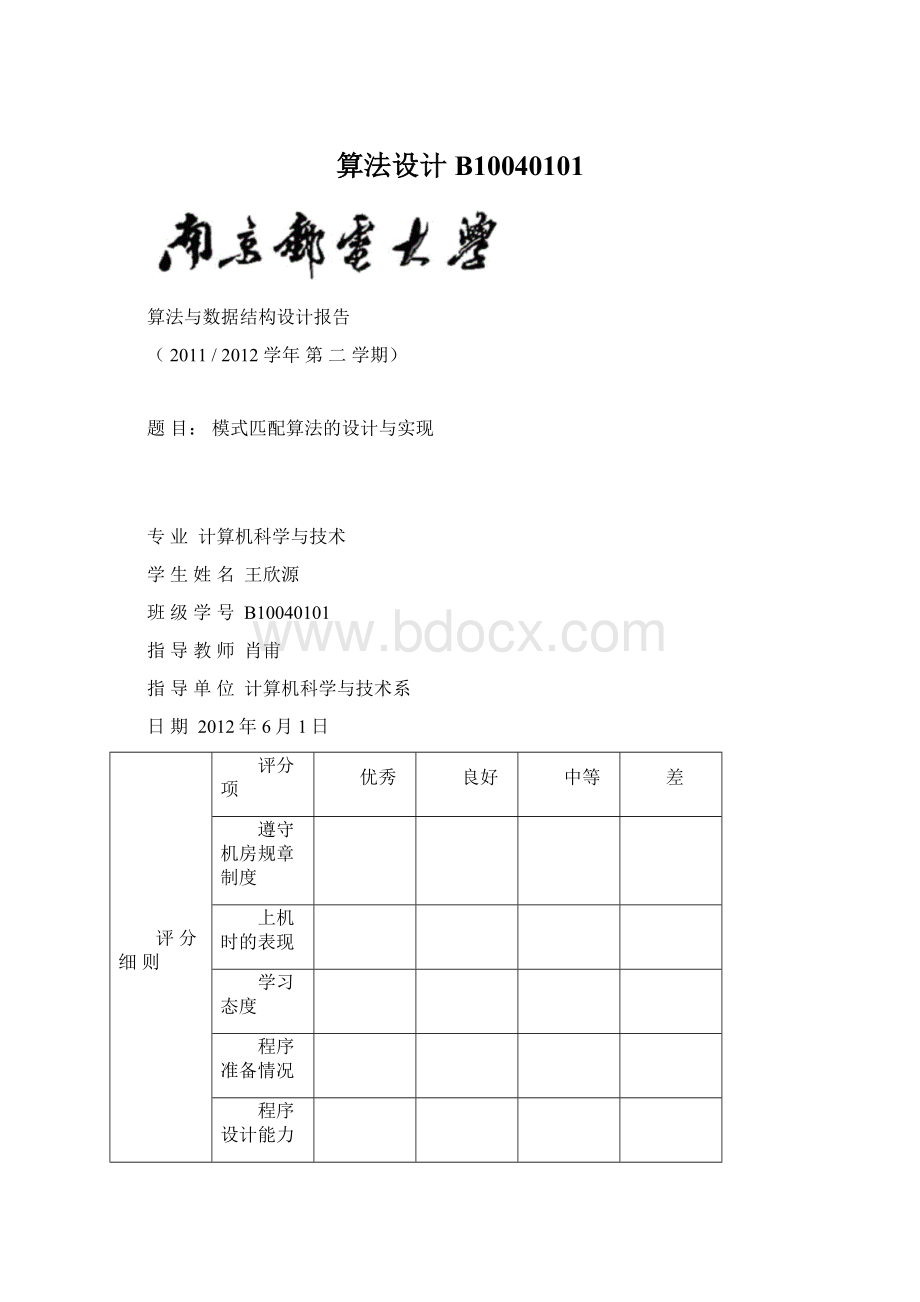
理解模式匹配的含义,掌握简单匹配算法及模式匹配KMP算法的思想,实现以下任务:
(1)编程动态实现简单模式匹配算法及模式匹配KMP算法;
(2)根据给定的主串与模式串,给出根据两种匹配算法进行匹配的各趟匹配结果;
(3)测试用例:
主串:
ThrougharetrospectivelookatthemathematicsteachingatUSTC,thisarticlesummarizesuniversity’steachingachievementsinpast45years.
匹配子串:
teaching
输出结果:
匹配子串teaching出现在主串中的次数为2
2次的匹配的位置分别是:
48104;
(4)一个应用实例如下:
●要求编写建立一个文本文件,每个单词不包括空格且不跨行,单词由字符序列构成,且区分大小写;
●统计给定单词在文本中出现的总次数;
检索出某个单词在文本中的行号、在该行中出现的次数及位置。
二.课题内容和要求
本题主要是要掌握模式匹配的含义,以及KMP模式匹配算法相比简单模式匹配算法优越性。
模式匹配是指有两个串S和P,在串S中找P的过程。
其中S是主串,P是模式串。
简单匹配算法是从主串S中下标i的字符与模式串P的第1个字符开始逐个比较,遇到不相等时,即达到失配点,该趟匹配失败,S回到原来的i+1的位置,P回到第1个字符位置,继续下一趟匹配,直到匹配成功。
简单模式匹配算法效率不高,原因在于匹配过程中有回溯。
而KMP算法中,i只进不退,对串S来说就消除了回退。
本课题要求用简单模式匹配和KMP模式匹配分别来测试用例:
ThrougharetrospectivelookatthemathematicsteachingatUSTC,thisarticlesummarizesuniversity’steachingachievementsinpast45years.其中模式串是:
teaching,经过测试后都应该得到的结果是:
匹配子串teaching出现在主串中的次数为2,2次的匹配的位置分别是:
46102;
如果加入一个能计算时间的函数后,应该得到的结果是用简单模式匹配的时间比KMP模式匹配运行的时间长。
由此,就可以得到在测试样例较多的情况下选用算法会节省时间,这对一些项目来说是很重要的,就突出了KMP算法的优越性。
在课题要求中的应用实例中,要求1.建立一个文本文件,要求编写建立一个文本文件,每个单词不包括空格且不跨行,单词由字符序列构成,且区分大小写;
2.编写程序能够读入文本文件中的内容,运用已经写好的程序统计给定单词在文本中出现的总次数;
3.能够检索出某个单词在文本中的行号、在该行中出现的次数及位置。
KMP算法也有优化的地方。
在此,我又将改进的KMP算法也写进去了,三种方法可以放在一起比较,找出最优化的算法。
三.需求分析
1.实现简单模式匹配的函数,其中公有函数Find(String&
p)调用私有函数Find(int
i,String&
p),私有函数每次在主串中找出一个模式串,而公有函数可以计算出所有的模式串的个数和位置。
intString:
:
Find(inti,String&
P)//代码具体见详细设计
Find(String&
P)//代码具体见详细设计
2.实现KMP模式匹配的函数,其中公有函数KMPFind(String&
p)调用私有函数KMPFind(inti,String&
KMPFind(inti,String&
KMPFind(String&
3.实现改进的KMP模式匹配的函数,其中公有函数KMPFindImprove(String&
p)调用私有函数KMPFindImprove(inti,String&
KMPFindImprove(inti,String&
KMPFindImprove(String&
4.经过比较后改进的KMP算法是最优化的,所以在读取文件、测试文件时采用该进的KMP算法来做。
其中取文件的函数Read()要自己设计
voidString:
Read(char*file)//代码具体见详细设计
5.main()函数中做了一个菜单,可以根据不同的选择测试不同的功能。
四.设计概要
1.程序的算法设计说明,采用流程图形式
2.每个程序中使用的存储结构设计说明
因为采用的是面向对象C++的方法,定义了一个String类,其String类中成员变量和成员函数原型声明如下:
classString
{
Private:
intn;
char*str;
int*count;
//记录子串在主串中出现的位置
intFind(inti,String&
P);
//简单匹配算法找到最近的匹配串后立即停止,而不向下继续且缺乏一个数组记录位置
intfail();
//记录失败函数
voidFail();
intKMPFind(inti,String&
voidImproveFail();
//改进的失败函数
intKMPFindImprove(inti,String&
public:
String();
//建立一个空串
String(constchar*p);
String(constString&
p);
//拷贝函数
~String();
intLength(){returnn;
};
//返回当前串对象长度
voidOutput(){cout<
<
str;
//输出字符串
intFind(String&
//简单匹配算法
intKMPFind(String&
//KMP匹配算法
intKMPFindImprove(String&
//改进的KMP匹配算法
voidOutput2();
//输出子串在主串中出现的位置
voidOutput3();
//输出子串所在行数,位置及总个数
voidRead(char*);
各个功能段均采用数组的存储结构。
五.详细设计
#include<
iostream>
string>
fstream>
cstdlib>
time.h>
usingnamespacestd;
#defineMAX100000
#defineM69
private:
int*f();
//建立一个空串
String:
String()//无参数的构造函数进行初始化
n=0;
str=NULL;
count=NULL;
f=NULL;
}
String(constchar*p)//有参数的构造函数
n=strlen(p);
str=newchar[n+1];
strcpy(str,p);
count=newint[n];
for(inti=0;
i<
n;
i++)
count[i]=0;
f=newint[n];
for(intj=0;
j<
j++)
f[j]=-1;
p)//拷贝构造函数
n=p.n;
if(str==NULL)exit
(1);
str[i]=p.str[i];
str[n]='
\0'
;
//结束标识符'
,否则会出现乱码
count=newint[n];
count[j]=p.count[j];
for(intk=0;
k<
k++)
f[k]=p.count[k];
~String()
delete[]str;
P)//简单匹配算法i为主串P的位置,开始置0
if(i<
0||i>
n-1)//越界检查
cout<
"
Outofbounds!
endl;
return-1;
char*pp=P.str;
//模式串指针pp指向第一个字符
char*t=str+i;
//主串指针t指向下标i的字符
while(*pp!
='
\x0'
&
&
i<
=n-P.n)//子串pp未到串尾且剩余字符超过模式串长,则循环
if(*pp++!
=*t++)
pp=P.str;
//模式串回到第一个字符
t=str+(++i);
//主串回到i+1的位置
if(*pp=='
)
returni;
//若pp已到串尾,则匹配成功
P)
intsum=0;
intj=Find(0,P);
//共有find函数调用私有函数find
while(j!
=-1)
count[sum]=j;
sum++;
//count记录位置,sum记录次数
if(j<
=n-P.n)
j=Find(j+P.n,P);
}
returnsum;
Fail()//失败函数
{
intj=0,k=-1;
f[0]=-1;
while(j<
n)
if((k==-1)||(str[j]==str[k]))
j++;
k++;
//k==-1或str[j]==str[k]时,j,k各扩展1位,j无回溯
f[j]=k;
//求得的k存入f[j]
elsek=f[k];
//str[j]不等于str[k]时,k回溯到f[k]
if(i<
this->
Fail();
intj=0,m=P.n;
while(i<
n&
j<
m)
if(j==-1||str[i]==P.str[j])//相等或j=-1时,i、j均后移1个位置
i++;
else
j=P.f[j];
//到达失配点,j回溯到f[j]
return((j==m)?
i-m:
-1);
P)
intj=KMPFind(0,P);
j=KMPFind(j+P.n,P);
returnsum;
ImproveFail()//改进的失败函数
if((k==-1)||(str[j]==str[k]))//当k=-1或str[j]=str[k]时,j,k各扩展1位
k++;
if(str[j]==str[k])//将字符pk与pj比较,若相等则将f[k]存入f[j]
f[j]=f[k];
//否则将k存入f[j]
else
k=f[k];
//str[j]不等于str[k]时,k回溯到f[k],j无回溯
n-1)
ImproveFail();
if(j==-1||str[i]==P.str[j])
}
intj=KMPFindImprove(0,P);
{
count[sum++]=j;
=n-P.n)j=KMPFindImprove(j+P.n,P);
Read(char*file)//通过文件读取
charch;
char*temp=newchar[MAX];
inti=0;
ifstreaminfile(file);
if(!
file)//判断能否打开
Cannotopenthefile!
return;
while(infile.get(ch)!
="
#"
)
temp[i++]=ch;
if(ch=='
#'
)//以#为结束标志
break;
temp[i]='
n=i;
str=newchar[n];
//由于定义一个空子串时n=0,count,f等都为NULL,所以此处要重新定义
for(intz=0;
z<
z++)
str[z]=temp[z];
count[k]=0;
for(intj=0;
infile.close();
delete[]temp;
Output2()//输出子串在主串中的位置
while(count[i]!
=count[i+1]&
MAX-1)//若不再有新的子串匹配,则count[i]与count[i+1]均为0
count[i]<
"
Output3()//输出子串在文件中的行数、位置、及次数
intt=0;
int*line=newint[MAX];
//记录字符串在该行出现的次数
int*ram=newint[M];
//记录字符串在该行出现的位置
for(intm=1;
m<
=MAX;
m++)
line[m]=0;
for(intn=1;
n<
=M;
n++)
ram[n]=0;
MAX-1)
intl1=count[i]/M+1;
intl2=count[i+1]/M+1;
//记录相邻两个字符串行数(要考虑到只有一行的情况)
intr=count[i]%M;
//记录该字符串位置
line[l1]++;
ram[t++]=r;
if((l1!
=l2&
count[i+1]>
0)||(l1==l2&
count[i+1]==0))//换行
该单词在第"
l1<
行出现"
line[l1]<
次,"
分别在位置:
for(ints=0;
s<
t;
s++)
ram[s]<
//每行中出现的位置
t=0;
//到下一行找
voidmain()
intchoise=0;
cout<
******************************************************"
##1.简单模式匹配做测试样例##"
##2.KMP模式匹配做测试样例##"
##3.改进的KMP模式匹配做测试样例##"
##4.从文本测试函数##"
##5.返回##"
while(choise!
=5){
cin>
>
choise;
if(choise==1){//简单模式匹配算法测试
clock_tstart,finish;
start=clock();
Strings1("
ThrougharetrospectivelookatthemathematicsteachingatUSTC,thisarticlesummarizesuniversity’steachingachievementsinpast45years."
);
s1.Output();
Strings2("
teaching"
intm=s1.Find(s2);
用简单模式匹配测匹配子串"
s2.Output();
出现在主串中的次数为:
if(m!
=0)
{
次的匹配的位置分别是:
s1.Output2();
finish=clock();
endl<
timeis:
(double)(finish-start)/CLK_TCK<
if(choise==2)//KMP模式匹配算法测试
{
clock_tstart,finish;
ThrougharetrospectivelookatthemathematicsteachingatUSTC,thisarticlesummarizesuniversity’steachingachievementsinpast45years."
用kmp模式匹配测匹配子串:
intn=s1.KMPFind(s2);
if(n!
s1.Output2();
if(choise==3)//改进的KMP模式匹配算法测试
start=clock
 升级会员
升级会员 