SPSS学习系列09 缺失值处理Word文档下载推荐.docx
《SPSS学习系列09 缺失值处理Word文档下载推荐.docx》由会员分享,可在线阅读,更多相关《SPSS学习系列09 缺失值处理Word文档下载推荐.docx(21页珍藏版)》请在冰豆网上搜索。
提供了多种方法用于估计含缺失值数据的均值、相关矩阵或协方差矩阵,通过这些方法计算出的统计量更加可靠。
(3)用估计值替换缺失值:
使用EM或回归法,用户可以从未缺失数据的分布情况中推算出缺失数据的估计值,从而能有效地使用所有数据进行分析,来提高统计结果的可信度。
【缺失值分析】实例操作,使用SPSS20自带的实例文件:
telco_missing.sav
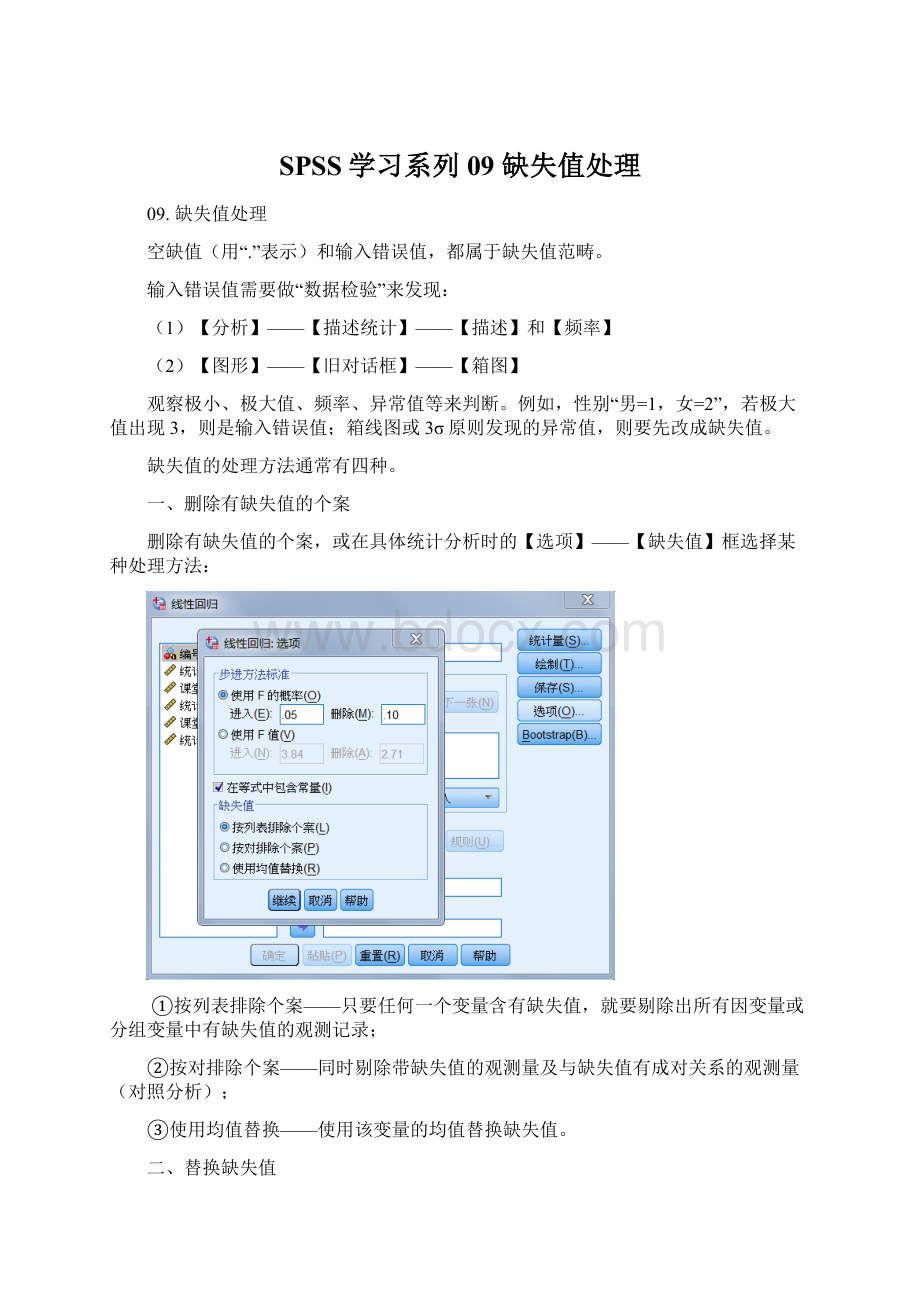
1.【分析】——【缺失值分析】,打开“缺失值分析”窗口,将变量“婚姻状况、教育程度、退休、性别”选入【分类变量】,将变量“服务月数、年龄、现在住址居住年数、家庭收入、现职位工作年数、家庭人数”选入【定量变量】
最大类别(最大分类数)默认为25,超过该数目的分类变量将不引入分析。
2.点【描述】,打开“描述统计”子窗口,用来设置要显示的缺失值描述统计量。
勾选“单变量统计量”,勾选【指示变量统计量】框的“使用有指示变量形成的分组进行的t检验”和“为分类变量和指示变量生成交叉表”,点【继续】
3.点【模式】,打开“模式”子窗口,用来设置显示输出表格中的缺失数据模式和范围。
勾选“按照缺失值模式分组的表格个案”;
因为“教育程度”、“退休”和“性别”中的缺失模式似乎影响数据,“家庭收入”含有大量缺失值,将这些变量选入【附加信息】;
其它保持默认,点【继续】
4.回到原窗口,勾选【估计】框中的“EM”和“回归”,其它默认设置。
点击【EM】或【回归】按钮可以修改其设置
注意:
若要保存替换缺失值之后的数据,需要勾选“保存完成数据”:
创建新数据集并命名,或写入新数据文件。
另外,默认使用所有变量进行分析,若要选择部分变量,可点【变量】按钮修改。
点【确定】,得到输出结果:
单变量统计
N
均值
标准差
缺失
极值数目a
计数
百分比
低
高
tenure
968
35.56
21.268
32
3.2
age
975
41.75
12.573
25
2.5
address
850
11.47
9.965
150
15.0
9
income
821
71.1462
83.14424
179
17.9
71
employ
904
11.00
10.113
96
9.6
15
reside
966
2.32
1.431
34
3.4
33
marital
885
115
11.5
ed
965
35
3.5
retire
916
84
8.4
gender
958
42
4.2
a.超出范围(Q1-1.5*IQR,Q3+1.5*IQR)的案例数。
提供了数据的一般特征,给出了所有分析变量缺失数据的频数、百分比,定量变量的均值、标准差、极值数目。
income(家庭收入)有最多具有缺失值(17.9%),也有最多的极值;
而age(年龄)有最少缺失值(5%)。
估计均值摘要
所有值
EM
36.12
41.91
11.58
77.3941
11.22
2.29
回归
35.77
41.68
11.59
74.3174
10.99
估计标准差摘要
21.468
12.699
10.265
87.54860
10.165
1.416
21.188
12.534
9.935
84.71430
10.242
1.423
使用EM法和回归法进行缺失值的估计和替换后,总体数据的均值和标准差的变化情况,其中“所有值”为原始数据特征,另两行分别是采用EM法、回归法得到的统计参数。
单个方差t检验a
t
.4
.3
.
1.4
1.0
df
202.2
192.5
313.6
191.1
199.5
#存在
819
832
693
766
824
#缺失
149
143
128
138
142
均值(存在)
35.68
41.79
74.0779
11.20
2.34
均值(缺失)
34.91
41.49
55.2734
9.86
2.21
-5.0
-8.3
-3.9
-5.9
3.6
249.5
222.8
203.3
315.2
793
801
741
792
175
174
157
163
33.93
40.01
10.67
9.91
2.39
42.97
49.73
14.97
15.93
2.02
-1.0
-.4
-.7
.5
-.3
110.5
110.2
97.6
114.9
110.9
877
881
874
91
94
80
92
35.34
41.69
11.37
71.4953
2.31
37.70
42.27
12.32
67.9125
2.37
.0
1.8
1.2
-.8
.9
-2.2
148.1
149.5
138.8
121.2
128.3
134.2
856
862
748
728
805
857
112
113
102
93
99
109
42.00
11.61
70.3887
11.10
2.28
35.57
39.85
10.43
77.0753
10.17
2.61
-.6
.2
95.4
94.4
84.0
93.2
99.0
888
893
777
751
82
73
70
81
35.44
41.70
11.42
71.3356
36.89
42.29
11.96
69.1143
2.30
对于每个定量变量,由指示变量(存在,缺失)组成成对的组。
a.不显示少于5%个缺失值的指示变量。
通过单个方差t检验有助于标识缺失值模式可能影响定量变量的变量。
按照相应变量是否缺失将全部记录分为两组,再对所有定量变量在这两组间进行t检验。
判断数据是否完全随机缺失(表示缺失和变量的取值无关)。
例如,似乎年纪较长的响应者更不可能报告收入水平。
当income缺失时,平均age为49.73,与之相比,当income未缺失时为40.01。
实际上,income的缺失似乎影响多个定量(刻度)变量的平均值。
此指示数据可能并未完全随机缺失。
类别变量相对于指示变量的交叉制表
总计
未婚
已婚
SysMis
存在
390
358
85.0
85.5
83.4
88.7
%SysMis
14.5
16.6
11.3
380
348
82.1
83.3
81.1
80.9
16.7
18.9
19.1
418
387
90.4
91.7
90.2
86.1
8.3
9.8
13.9
423
392
101
91.6
92.8
91.4
87.8
7.2
8.6
12.2
不显示少于5%个缺失值的指示变量。
观察marital(婚姻状况)表,指示变量的缺失值数量在marital类别之间似乎变化不大。
一个人结婚与否似乎并不影响任何定量(刻度)变量的数据缺失情况。
例如,85.5%未婚者报告address(当前地址居住年限),83.4%已婚者报告相同变量。
差异很小
 升级会员
升级会员 