统计学第四版贾俊平等第七章参数估计PPT文件格式下载.ppt
《统计学第四版贾俊平等第七章参数估计PPT文件格式下载.ppt》由会员分享,可在线阅读,更多相关《统计学第四版贾俊平等第七章参数估计PPT文件格式下载.ppt(122页珍藏版)》请在冰豆网上搜索。
或者有些总体的个体较多,不可能也没必要进行一一测定。
因此,有必要用样本提供的信息来推断总体的特征。
1.提出参数估计的原因:
(1).参数估计(parameterestimation)就是用样本统计量去估计总体的参数。
7.1.1估计量与估计值,2.参数估计、估计量、估计值:
(2).估计量(estimator)就是用来估计总体的统计量,(3).估计值(estimatedvalue)就是根据一个具体的,
(1).点估计(pointestimate)就是用样本统计量,7.1.2点估计与区间估计,参数估计的方法:
点估计和区间估计。
1.点估计,(3).在重复抽样条件下,点估计的均值可望等于,(4).用点估计值代替总体参数值时,必须给出点估计值的可靠性,即区间估计。
(2).求点估计的方法有最小二乘法、极大似然法、矩法估计和顺序统计量法等。
(1).区间估计(intervalestimate)就是在点估计的基础上,给出总体参数估计的一个区间范围,该区间通常由样本统计量加减抽样误差得到。
7.1.2点估计与区间估计,2.区间估计,
(2).与点估计不同,进行区间估计时,根据样本统计量的抽样分布可以对样本统计量与总体参数的接近程度给出一个概率度量。
(3).区间估计的基本原理:
7.1.2点估计与区间估计,7.1.2点估计与区间估计,因此,约有95的样本均值会落在m的两个标准误差的范围之内,也就是所,约有95的样本均值所构造的两个标准误差的区间会包括m。
通俗地说,如果我们抽取100个样本来估计总体的均值,由100个样本所构造的100区间中,约有95个区间包含总体均值,而另外5个区间则不包含总体均值。
7.1.2点估计与区间估计,图形表示:
(4).置信区间(confidenceinterval)是指由样本统计量所构造的总体参数的估计区间,区间的最小值称为置信下限,最大值称为置信上限。
7.1.2点估计与区间估计,由于统计学家在某种程度上确信这个区间会包含真正的总体参数,所以取名为置信区间。
比如:
抽取100个样本,由这100个样本构造的总体参数的100个置信区间中,有95的区间包含总体参数的真值,5的区间不包含总体参数的真值,那么,95就称为置信水平,用该方法构造的区间就称为置信水平为95的置信区间。
7.1.2点估计与区间估计,(5).置信水平(confidencelevel)也称为置信度或置信系数(confidencecoefficient),是指如果将构造置信区间的步骤重复多次,置信区间中包含总体真值的次数所占的比例。
7.1.2点估计与区间估计,(4).样本量给定时,置信区间的宽度随置信水平的增大而增大;
置信水平固定时,置信区间的宽度随样本量的增大而减小。
换言之,较大的样本量所提供的总体信息要比较小的样本多。
7.1.2点估计与区间估计,(5).对置信区间的理解,注意以下几点:
.如果用某种方法构造的所有区间中有95的区间包含总体参数的真值,5的区间不包含总体参数的真值,那么,用该方法构造的区间称为置信水平为95的置信区间。
.总体参数的真值是固定的、未知的,而用样本构造的区间则是不固定的。
若抽取不同的样本,用该方法可以得到不同的区间,从这种意义上说,置信区间是一个随机区间。
7.1.2点估计与区间估计,.实际应用中,进行估计时往往只抽取一个样本,此时所构造的是与该样本相联系的一定置信水平下的置信区间。
由于用该样本所构造的区间是特定的区间,而不再是随机区间,所以无法知道这个样本所产生的区间是否包含总体的真值。
7.1.2点估计与区间估计,比如:
用95的置信水平得到某班学生考试成绩的置信区间为6080分。
1我们不能说6080这个区间以95的概率包含全班学生平均考试成绩的真值,或者表述为全班学生的平均考试成绩以95的概率落在6080分之间,这类表述是错误的,因为总体均值m是个常数,不是随机变量。
我们只是知道在多次抽样中有95的样本得到的区间包含全班学生平均考试成绩的真值。
2这个概率的真正意义是如果做了100次抽样,大概有95次找到的区间包含真值,有5次找到的区间不包含真值。
7.1.2点估计与区间估计,这个概率不是用来描述某个特定的区间包含总体参数真值可能性的,因为一个特定的区间“总是包含”或“绝对不包含”参数的真值,不存在“可能包含”或“可能不包含”的问题。
用概率可以知道在多次抽样得到的区间中大概有多少个区间包含了参数的真值。
(1).无偏性(unbiasedness)是指估计量抽样分布的数学期望等于被估计的总体参数。
7.1.3评价估计量的标准,1.无偏性,7.1.3评价估计量的标准,
(2).常用的无偏估计量,7.1.3评价估计量的标准,有效性(efficiency)是指对同一总体参数的两个无偏估计量,有更小标准差的估计量更有效。
7.1.3评价估计量的标准,2.有效性,一致性(consistency)是指随着样本量的增大,点估计量的值越来越接近被估总体的参数。
换言之,一个大样本给出的估计量要比一个小样本给出的估计量更接近总体的参数。
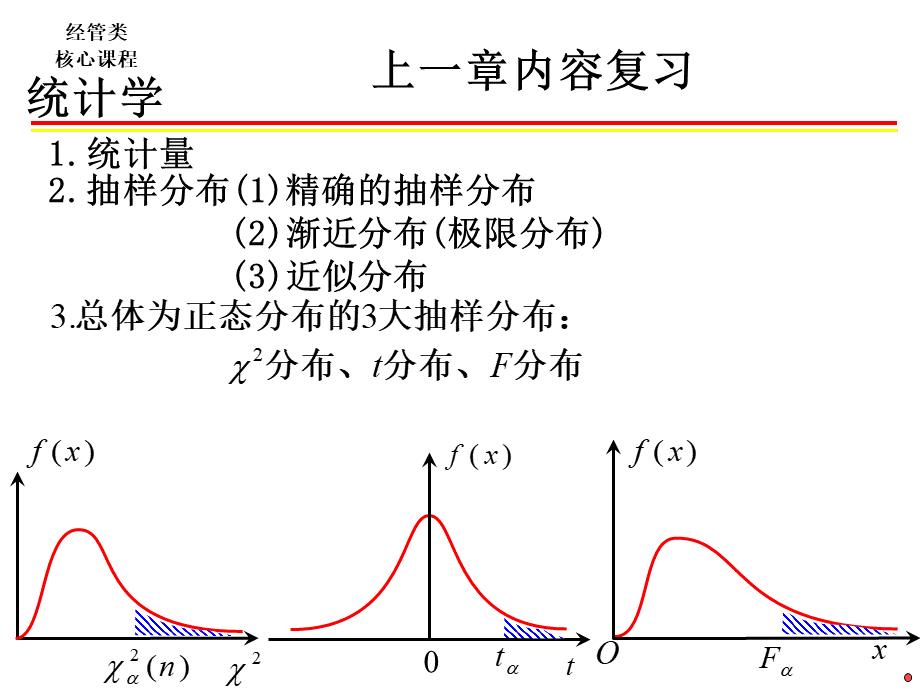
7.1.3评价估计量的标准,3.一致性,7.2一个总体参数的区间估计,7.2.1总体均值的区间估计7.2.2总体比例的区间估计7.2.3总体方差的区间估计,一个总体参数的区间估计,7.2.1总体均值的区间估计,在对总体均值进行区间估计时,需要考虑总体是否为正态分布、总体方差是否已知、由于构造估计量的样本是大样本(n30)还是小样本(n30)等几种情况。
1.正态总体、方差已知,或非正态总体、大样本,a称为风险值,是事先给定的概率值。
是估计,总体均值时的边际误差,也称估计误差或误差范围。
7.2.1总体均值的区间估计,总体均值的区间估计(例题),【例7.1】一家食品生产企业以生产袋装食品为主,为对产量质量进行监测,企业质检部门经常要进行抽检,以分析每袋重量是否符合要求。
现从某天生产的一批食品中随机抽取了25袋,测得每袋重量如下表所示。
已知产品重量的分布服从正态分布,且总体标准差为10克。
试估计该批产品平均重量的置信区间,置信水平为95%,总体均值的区间估计(例题),解:
总体均值的区间估计(例题分析),【例7.2】一家保险公司收集到由36投保个人组成的随机样本,得到每个投保人的年龄(周岁)数据如下表。
试建立投保人平均年龄的90%的置信区间。
总体均值的区间估计(例题),解:
7.2.1总体均值的区间估计,2.正态总体、方差未知、小样本,总体均值的区间估计(例题),【例7.3】已知某种灯泡的寿命服从正态分布,现从一批灯泡中随机抽取16只,测得其使用寿命(小时)如下。
建立该批灯泡平均使用寿命95%的置信区间,总体均值的区间估计(例题),解:
7.2.2总体比例的区间估计,本节只讨论大样本情况下总体比例的估计问题,总体比例的置信区间(例题),【例7.4】某城市想要估计下岗职工中女性所占的比例,随机抽取了100名下岗职工,其中65人为女性职工。
试以95的置信水平估计该城市下岗职工中女性比例的置信区间。
解:
7.2.3总体方差的区间估计,我们只讨论正态总体方差的估计问题,总体方差的区间估计(例题),【例7.5】一家食品生产企业以生产袋装食品为主,现从某天生产的一批食品中随机抽取了25袋,测得每袋重量如下表所示。
已知产品重量的分布服从正态分布。
以95%的置信水平建立该种食品重量方差的置信区间,总体均值的区间估计(例题),解:
一个总体参数的估计及所使用的分布,待估参数,均值,比例,方差,大样本,小样本,大样本,Z分布,正态总体s2已知,正态总体s2未知,Z分布,c2分布,Z分布,t分布,习题选讲,【习题7.4】从总体中抽取一个n=100的简单随机样本,得到=81,s=12。
要求:
(1)构建总体均值m的90的置信区间;
(2)构建总体均值m的95的置信区间;
(3)构建总体均值m的99的置信区间。
习题选讲,【习题7.6】利用下面的信息,构建总体均值的置信区间。
习题选讲,习题选讲,【习题7.11】某企业生产的袋装食品采用自动打包机包装,每袋标准重量为100g。
现从某天生产的一批产品中按重复抽样随机抽取50包进行检查,测得每包重量(单位:
g)见Book7.11。
已知食品重量服从正态分布,要求:
(1)确定该种食品平均重量的95%的置信区间。
(2)如果规定食品重量低于100g属于不合格,确定该批食品合格率的95%的置信区间。
【习题7.20】顾客到银行办理业务时往往需要等待一些时间,而等待时间的长短与许多因素有关,比如,银行的业务员办理业务的速度,顾客等待排队的方式等等。
为此,某银行准备采取两种排队方式进行试验,第一种排队方式是所有顾客都进入一个等待队列;
第二种排队方式是:
顾客在三个业务窗口处列队三排等待。
为比较哪种排队方式使顾客等待的时间更短,银行各随机抽取了10名顾客,他们在办理业务时所等待的时间(单位:
min)见Book7.20。
习题选讲,习题选讲,
(1)构建第一种排队方式等待时间标准差的95的置信区间。
(2)构建第一种排队方式等待时间标准差的95的置信区间。
根据
(1)和
(2)的结果,你认为哪种排队方式更好?
上一节内容复习,1.参数估计:
2.置信区间(区间估计):
上一节内容复习,3.一个总体参数的置信区间(均值):
上一节内容复习,4.一个总体参数的置信区间(比例,大样本):
5.一个总体参数的置信区间(方差,正态总体):
上一节内容复习,6.两个总体均值之差的置信区间:
(1).独立大样本,上一节内容复习,
(2).独立小样本,上一节内容复习,
(2).独立小样本,上一节内容复习,(3).匹配样本:
小样本:
大样本:
7.3两个总体参数的区间估计,7.3.1两个总体均值之差的区间估计7.3.2两个总体比例之差的区间估计7.3.3两个总体方差比的区间估计,7.3.1两个总体均值之差的区间估计,1.两个总体均值之差的估计:
独立样本,
(1).大样本的估计:
如果两个样本是从两个总体中独立抽取的,即一个样本中的元素与另一个样本中的元素相互独立,则称为独立样本(independentsample)。
如果两个总体都为正态分布,或两个总体不服从正态分布但两个样本都为大样本时,由两个均值之差的抽样分布可知:
7.3.1两个总体均值之差的区间估计,两个总体均值之差的估计(例题),【例7.6】某地区教育管理部门想估计两所中学的学生高考时的英语平均分数之差,为此在两所中学独立地抽取两个随机样本,有关数据如右表所示。
试建立两所中学高考英语平均分数之差95%的置信区间。
两个总体均值之差的估计(例题),解:
两个总体均值之差在1-置信水平下的置信区间为,两所中学高考英语平均分数之差的置信区间为5.03分10.97分,7.3.1两个总体均值之差的区间估计,
(2).小样本的估计:
如果两个样本都为小样本时,为估计两个总体的均值之差,需作以下假定:
1).两个总体服从正态分
 升级会员
升级会员 