数据库基础篇.docx
《数据库基础篇.docx》由会员分享,可在线阅读,更多相关《数据库基础篇.docx(42页珍藏版)》请在冰豆网上搜索。
数据库基础篇
数据库基础篇
第一章绪论
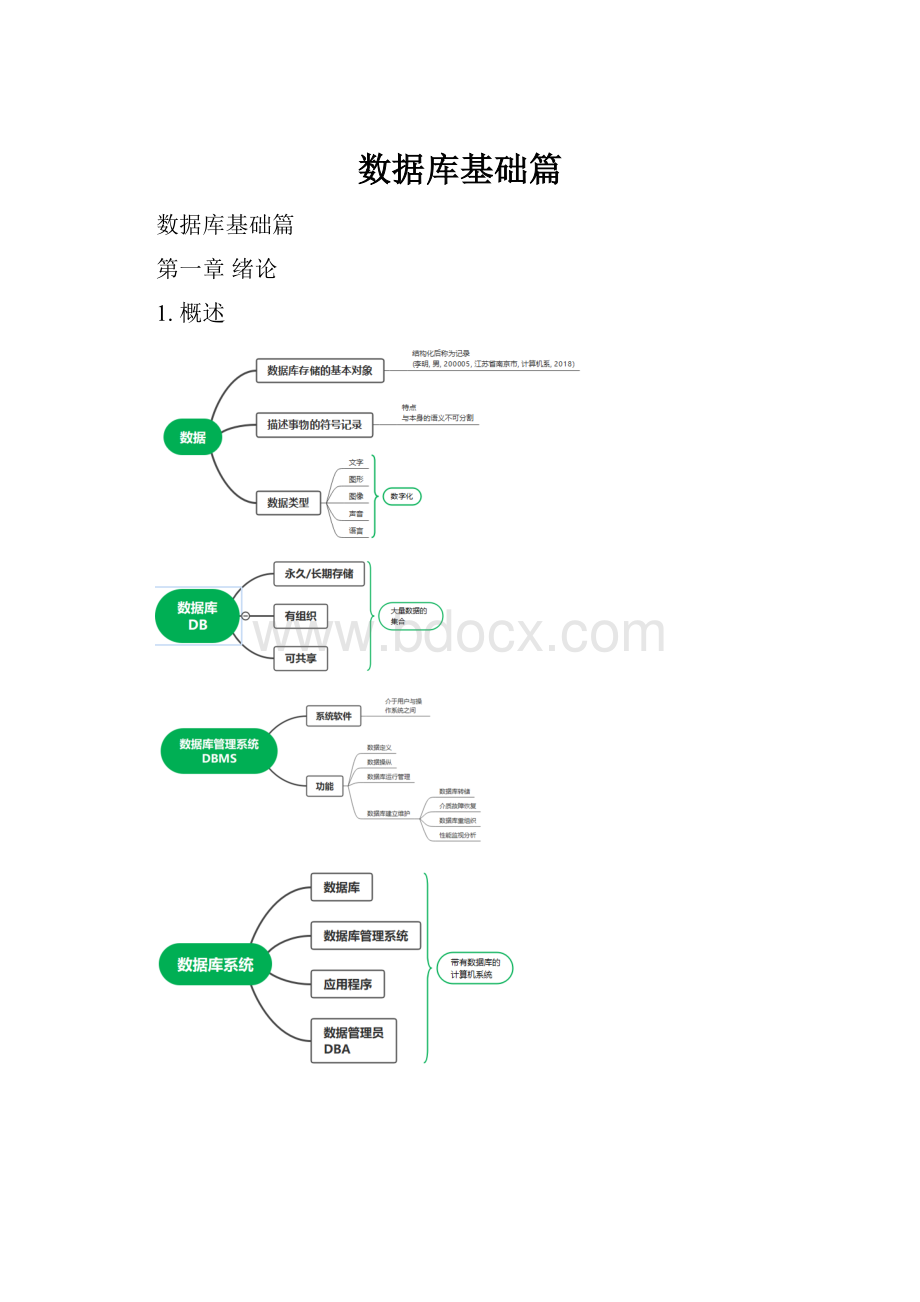
1.概述
2.数据模型
信息世界的一些基本概念
●实体客观存在并可相互区别的事物称为实体。
注意:
不仅可以是具体的人、事、物,还可以是抽象的概念和联系。
●属性实体由若干属性刻画
例:
(李明,男,197205,江苏省南京市,计算机系,1990)
●码唯一标识实体的属性集称为码。
注意可以不唯一。
反映语义范畴。
●域属性的取值范围。
●实体型具有相同属性的实体具有共性。
用实体名及其属性名集合来刻画同类实体,称为实体型。
如:
学生(学号、姓名、性别、…、入学时间)
●实体集同一实体型实体的集合。
●联系主要研究不同实体集之间的联系。
注意:
联系的基数约束选取与现实问题密切相关,如考虑只借阅者借阅图书,则模型为1对N,考虑一段时间读者借阅的书籍,则需要模型M:
N。
3.数据库系统结构
相关定义:
●型:
对某一类数据的结构和属性的说明
●值:
型的一个具体赋值
●模式(Schema)静态稳定
数据库中全体数据的逻辑结构和特征的描述
是型的描述
反映的是数据的结构及其联系
模式是相对稳定的
●实例(Instance)动态相对变动
模式的一个具体值
反映数据库某一时刻的状态
同一个模式可以有很多实例
实例随数据库中的数据的更新而变动
三层模式关系:
●数据库模式是数据库的核心和关键
●外模式通常是模式的子集
●数据按外模式的描述提供用户,按内模式的描述存储在硬盘上
●模式介于外、内模式之间,既不涉及外部的访问,也不涉及内部的存储,从而起到隔离作用,有利于保持数据的独立性
第二章关系数据库
1.从集合论角度定义关系模型
域:
域是具有相同数据类型的值的集合。
如自然数,全班同学的名字等。
笛卡儿积(卡氏积):
给定一组域D1,D2,…,Dn,这些域中可以有相同的域。
D1,D2,…,Dn的笛卡儿积为:
D1×D2×…×Dn={(d1,d2,…,dn)|di∈Di,i=1,2,…,n},其中每一个元素(d1,d2,…,dn)称为一个n元组。
元素中的每个值di称为一个分量。
基数的概念:
若Di(i=1,2,…,n)为有限集,其基数为|Di|,则D1×D2×…×Dn的基数为:
|D1|×|D2|×…×|Dn|
关系:
D1×D2×…×Dn的任意子集叫做在域D1,D2,…,Dn上的关系,可记做:
R(D1,D2,…,Dn),R为关系名,n是关系的目或度(degree)。
注意:
●这里的“子集”是“任意子集”,包括空集。
●笛卡儿积不满足交换率,即笛卡儿积的元组有序。
而关系通过给关系的列附加属性名的方式取消笛卡儿积元组的有序性。
●按定义,关系可以是无限集。
通常我们在关系数据模型中限定关系为有限关系。
候选码:
●若关系中的某一属性组的值能唯一地标识一个元组,而其子集不能,则称该属性组为该关系的一个候选码(CandidateKey)。
●一个关系可能有多个候选码,则选定其中一个作为主码(PrimaryKey)。
●包含在任何候选码中的属性称为主属性,不包含在任何候选码中的属性称为非主属性。
●全码(All-key)--关系模式的所有属性组构成此关系模式的唯一候选码。
2.关系
2.1概述一次一集合!
2.2关系
2.3关系模式
关系模式是对关系的描述(是型的描述)可表述为:
R(U,D,dom,F)R为关系名
●属性构成U
●属性来自的域D
●属性与域之间的映象关系dom
●属性间的数据依赖关系集合F
●元组语义以及完整性约束条件
关系模式通常可以简记为:
R(U)或R(A1,A2,…,An)R为关系名,A1,A2,…,An为属性名。
而域名及属性向域的映象常常直接说明为属性的类型、长度。
关系模式是静态的、稳定的,而关系是动态的、随时间变化的,两者是型与值的关系。
3.关系完整性
(1)实体完整性规则每一关系必有一主码,构成主码的各属性值均不能取空值。
主码也不能取重复值。
即现实世界中的实体是可区分的,它们具有某种唯一性标识。
(2)参照完整性规则若属性(或属性组)F是基本关系R的外码,它与基本关系S的主码Ks相对应(基本关系R和S不一定是不同的关系),则对于R中每个元组在F上的值必须为:
●或者取空值(F的每个属性值均为空值)
●或者等于S中某个元组的主码值即引用的时候,必须取基本表中已经存在的唯一标识
(3)用户定义的完整性就是针对某一具体关系数据库的约束条件,它反映某一具体应用所涉及的数据必须满足的语义要求。
设计的模型应该自身提供检验该完整性的机制
4.关系代数
4.1概述
关系代数的四类运算符:
集合运算符、专门的关系运算符、算术比较符和逻辑运算符。
双目运算符的优先级低于单目运算符四种二目运算:
三种运算要求参与运算的两个关系R,S具有相同的目n,且相应属性取自同一个域。
5种基本运算并、差、广义笛卡尔积、选择、投影
3种附加运算交、连接、除(都可用基本运算替代)
4.2集合运算
并交差运算属性个数必须要一致属性名可以不相同
连接如果没有共同属性,则会退化为笛卡尔积
4.3专门的关系运算
(1)选择:
(2)投影:
注意:
投影基本思想是从关系中消除某些属性,投影也可能消除掉某些行。
因为取消了某些属性列后,就可能出现重复行,应取消这些完全相同的行。
(3)连接:
等值连接
自然连接取消重复列,同时从行和列的角度进行运算。
(4)除
设关系R除以关系S的结果为关系T,则T包含所有在R中但不在S中的属性及其值
且T的元组与S的元组的所有组合都在R中
第三章关系数据库标准语言SQL
1.概述
SQL功能:
数据查询、数据操纵、数据定义和数据控制
SQL特点:
●SQL进行数据操作,只要提出“Whattodo”,无需告诉系统“Howtodo”
充分体现关系系统的特点和优势,有利于提高数据的独立性
●面向集合的操作方式关系运算“一次一集合”方式的体现。
●一种语法结构、两种使用方式既是自含式语言,又是嵌入式语言
2.SQL语句
2.1模式的定义与删除
(1)定义模式方法:
●CREATESCHEMAAUTHORIZATION
●CREATESCHEMAAUTHORIZATION(<模式名>隐含为用户名)
在这个空间中可以定义该模式包含的数据库对象,例如基本表、视图、索引等。
在CREATESCHEMA中可以接受CREATETABLE,CREATEVIEW和GRANT子句。
(2)删除模式方法:
●DROPSCHEMA
CASCADE(级联)
删除模式的同时把该模式中所有的数据库对象全部删除
RESTRICT(限制)
如该模式中定义了下属的数据库对象(如表、视图等),则拒绝该删除语句的执行。
当该模式中没有任何下属的对象时才能执行。
2.2基本表的定义,修改与删除
(1)定义基本表:
CREATETABLE<表名>
(<列名1><数据类型>[列级完整性约束条件]
[,<列名2><数据类型>[列级完整性约束条件]]
...
[,表级完整性约束条件]);
注:
如果完整性约束条件涉及到该表的多个属性列,则必须定义在表级上,否则既可以定义在列级也可以定义在表级。
定义基本表所属模式:
●在创建模式语句中同时创建表
●在表名中明显地给出模式名:
Createtable“S-T”.Student(......);/*模式名为S-T*/
●设置所属的模式,在创建表时表名中不必给出模式名
(2)修改基本表
ALTERTABLE<表名>
ADD<新列名><数据类型>[完整性约束](增加新列)
ADDtable_constraint(增加表级完整性约束)
ALTERCOLUMN<列名><数据类型>(修改列的数据类型)
ALTERTABLEname
RENAME[COLUMN]columnTOnew_column(列更名)
DROP[COLUMN]column[RESTRICT|CASCADE](删除列)
DROP<完整性约束名>(删除列上的完整性约束)
DROPTABLE<表名>[RESTRICT|CASCADE](删除基本表)
[例]向Student表增加“入学时间”列,其数据类型为日期型。
ALTERTABLEStudentADDS_entranceDATE;
不论基本表中原来是否已有数据,新增加的列一律为空值。
[例]将年龄的数据类型由字符型(假设原来的数据类型是字符型)改为整数。
ALTERTABLEStudentALTERCOLUMNSageINT;
[例]增加课程名称必须取唯一值的约束条件。
ALTERTABLECourseADDUNIQUE(Cname);
Alter可用于解决互相引用问题
2.3建立和删除索引
(1)建立索引
作用:
提高查询速度
CREATE[UNIQUE][CLUSTERED|NONCLUSTERED]INDEX<索引名>ON<表名>(<列名>[<次序>],[<列名>[<次序>]…]]);
UNIQUE(单一索引):
唯一索引,不允许存在索引值相同的两行
CLUSTERED(聚集索引):
索引项的顺序与表中记录的物理顺序一致。
表中如果有多个记录在索引字段上相同,这些记录构成一簇,只有一个索引值。
优点:
查询速度快。
缺点:
维护成本高,且一个表只能建一个聚簇索引。
NONCLUSTERED(非聚集索引)
作为非聚集索引,行的物理排序独立于索引排序
非聚集索引的叶级包含索引行(B+树)
例如:
CREATEUNIQUEINDEXStusnoONStudent(Sno)(默认升序)
CREATEUNIQUEINDEXSCnoONSC(SnoASC,CnoDESC)(ASC升序DESC降序)
(2)删除索引DROPINDEX<索引名>
例删除Student表的Stusno索引DROPINDEXStusno
3.SQL查询
一个SELECT-FROM-WHERE语句称为一个查询块SFW。
格式如下:
SELECT[ALL|DISTINCT]<目标列表达式>[,目标列表达式]…
FROM<表名或视图名>[,<表名或视图名>]…
[WHERE<条件表达式>]
[GROUPBY<列名1>[HAVING<条件表达式>]]
[ORDERBY<列名2>[ASC|DESC]]
3.1列查询
例1查询全体学生的学号与姓名。
SELECTSno,Sname
FROMStudent;
例2查询全体学生的详细记录
SELECT*
FROMStudent;
例3查全体学生的姓名、出生年份和所有系,要求用小写字母表示所有系名
SELECTSname,'YearofBirth:
',2020-Sage,LOWER(Sdept)
FROMStudent;
例4改变列标题(SQL标准用AS关键字)
SELECTSnameASName,'YearofBirth:
'ASBirth,2020-SageASBirthYear,LOWER(Sdept)ASDepartment
FROMStudent;
例5DISTINCT用于消除重复
SELECTDISTINCTSno
FROMSC;
3.2单表查询
查询满足指定条件的元组可以通过WHERE子句实现
●比较常用=,>,<,>=,<=,!
=
●确定范围BETWEENAND,NOTBETWEENAND
●确定集合IN,NOTIN
●空值ISNULL,ISNOTNULL
●多重条件(逻辑运算)AND,OR,NOT
(1)简单逻辑查询
例确定范围
查询年龄在20~23岁(包括)之间的学生的姓名、系别和年龄。
SELECTSname,Sdept,Sage
FROMStudent
WHERESageBETWEEN20AND23;
当然也可表示为:
SELECTSname,Sdept,Sage
FROMStudent
WHERESage>=20ANDSage<=23;
BETWEENAND与NOTBETWEENAND通常可以表示为用逻辑与连接的两个比较。
例确定集合
查询年龄在20~23岁(包括)之间的学生的姓名、系别和年龄。
SELECTSname,Sdept,Sage
FROMStudent
WHERESageIN(20,21,22,23);
查询既不是计算机科学系、数学系,也不是信息系的学生的姓名和性别。
SELECTSname,Sgender
FROMStudent
WHERESdeptNOTIN(‘CS’,’MA’,’IS’);
注意:
如果某些学生的Sdept为空(NULL),其学号姓名不会出现在结果中,如果把NOTIN改为IN,这些学生的信息也不会出现在结果中!
原因:
在有NULL的情况下,二值逻辑转化为三值逻辑,unknown介于true和false之间。
只有使WHERE条件为true的元组才被选出。
改进:
添加修饰
修饰语如下:
●ISTRUE
●ISNOTTRUE
●ISFALSE
●ISNOTFALSE
SELECTSname,Sgender
FROMStudent
WHERESdeptNOTIN(‘CS’,’MA’,’IS’)ISNOTFALSE;
(2)字符匹配LIKE
[NOT]LIKE‘<匹配串>’
<匹配串>可以是一个完整的字符串,也可以含有通配符%和_的字符串
●%(百分号)代表任意长度(>=0)的字符串
例如a%b表示以a开头,以b结尾的任意长度的字符串
●_(下横线)代表任意单个字符。
例如a_b表示以a开头,以b结尾的长度为3的任意字符串
例1匹配串为固定字符串
查询学号为201215121的学生的详细情况。
SELECT*
FROMStudent
WHERESnoLIKE‘201215121';
例2匹配串为含通配符的字符串
查询所有姓刘学生的姓名、学号和性别。
SELECTSname,Sno,Ssex
FROMStudent
WHERESnameLIKE'刘%';
查询姓"欧阳"且全名为三个汉字的学生的姓名。
SELECTSname
FROMStudent
WHERESnameLIKE'欧阳__';
例3表示%和_本身的方法用转义字符\,#,&,!
等+ESCAPE指明所用转移字符
查询DB_Design课程的课程号和学分。
SELECTCno,Ccredit
FROMCourse
WHERECnameLIKE‘DB\_Design’ESCAPE‘\’;
或者
SELECTc1
FROMtb
WHEREc1LIKE'%10-15!
%off%'ESCAPE'!
';
(3)涉及空值的查询ISNULL和ISNOTNULLSQL标准不允许NULL比较
例1查询缺少成绩的学生的学号及相应课程号。
SELECTSno,Cno
FROMSC
WHEREGradeISNULL;
(4)多重条件查询优先级AND>OR
关系代数中的
在SQL中的对应
●并UNION
●交INTERSECT
●差EXCEPT
两条SQL语句间使用默认不消重
例1查询数学系选了’3’号课程的学生的学号。
(SELECTSno
FROMStudent
WHERESdept=‘MA’)
INTERSECT
(SELECTSno
FROMSC
WHERECno=‘3’);
例2查询选了‘1’号课程但是没有选‘2’号课程的学生的学号。
(SELECTSno
FROMSC
WHERECno=‘1’)
EXCEPT
(SELECTSno
FROMSC
WHERECno=‘2’);
(5)查询结果排序ORDERBY子句明确指定结果顺序。
●可以按一个或多个属性列排序
●升序:
ASC;降序:
DESC;缺省值/默认为升序ASC,NULL值最大。
例1查询计算机系(CS)学生的学号和姓名,按年龄从大到小排,相同年龄的按学号升序排。
SELECTSno,Sname
FROMStudent
WHERESdept=‘CS’
ORDERBYSageDESC,Sno;
(6)集函数
COUNT([DISTINCT|ALL]*)统计元组个数
COUNT([DISTINCT|ALL]<列名>)统计一列中值的个数
SUM([DISTINCT|ALL]<列名>)计算一列值的总和(此列必须是数值型)
AVG([DISTINCT|ALL]<列名>)计算一列值的平均值(此列必须是数值型)
MAX([DISTINCT|ALL]<列名>)求一列值中的最大值
MIN([DISTINCT|ALL]<列名>)求一列值中的最小值
例1查询学生总人数
SELECTCOUNT(*)
FROMstudent;
或
SELECTCOUNT(Sno)
FROMstudent;
例2查询选修了课程的学生人数
SELECTCOUNT(DISTINCTSno)
FROMSC;
学生每选修一门课,在SC中都有一条相应的记录,而一个学生一般都要选修多门课程,为避免重复计算学生人数,必须在COUNT函数中用DISTINCT短语。
注:
NULL值的影响:
除count(*)外,NULL值均被聚集函数所忽略。
COUNT(*)总是返回记录的总个数
COUNT(字段)返回指定字段值非空的记录个数。
(7)对查询结果分组
GROUPBY子句可以将查询结果表的各行按一列或多列取值相等的原则进行分组。
目的:
细化集函数的作用对象。
如果未对查询结果分组,集函数将作用于整个查询结果,即整个查询结果只有一个函数值;
否则,集函数将作用于每一个组,即每一组都有一个函数值。
例1求各个课程号及相应的选课人数。
SELECTCno,COUNT(Sno)
FROMSC
GROUPBYCno;
结果如下
CnoCOUNT(Sno)
122
234
344
433
注:
SQL规定,所有带有NULL值的记录在分组时被作为一组。
分组后,一些详细信息可能损失,不能出现在SELECT结果中。
例2查询选修了3门以上课程的学生学号。
SELECTSno
FROMSC
GROUPBYSno
HAVINGCOUNT(*)>3;
HAVING短语与WHERE子句的区别:
作用对象不同
●WHERE子句作用于基表或视图,从中选择满足条件的元组
●HAVING短语作用于组,从中选择满足条件的分组。
例3查询有三科或三科以上成绩在80分以上的学生学号。
SELECTSno
FROMSC
WHEREGrade>=80
GROUPBYSno
HAVING(COUNT(Cno)>=3)
3.3多表查询/连接查询
连接查询主要包括等值连接、非等值连接查询、自身连接查询、外连接查询和复合条件连接查询。
(1)等值与非等值连接查询
用来连接两个表的条件称为连接条件或连接谓词,其一般格式为:
[<表名1>.]<列名1><比较运算符>[<表名2>.]<列名2>
例1查询每个学生及其选修课程的情况
学生情况存放在Student表中,学生选课情况存放在SC表中,所以本查询要把Student与SC表的数据通过两个表都具有的属性Sno(外码连接)实现的。
这是一个等值连接。
完成本查询的SQL语句为:
SELECTStudent.*,SC.*
FROMStudent,SC
WHEREStudent.Sno=SC.Sno;
上述作法只是基本连接形式之一,称为“交叉连接”或“叉积连接”。
除交叉连接外,还有“内连接”和“外连接”两种基本形式。
上例改为内连接形式
SELECT*
FROMStudentINNERJOINSC
ONStudent.Sno=SC.Sno;
注意:
内连接是从结果表中删除与其他被连接表中没有匹配行的所有行,所以内连接可能会丢失信息
(2)自身连接
例查询每一门课的间接先修课(即先修课的先修课)
题目要求查询每一门课程的先修课的先修课,在“课程”表即Course关系中,只有每门课的直接先修课信息,而没有先修课的先修课,要得到这个信息,必须先对一门课找到其先修课,再按此先修课的课程号,查找它的先修课程。
为Course表取两个别名,一个是FIRST,另一个是SECOND
这两个表通过FIRST的Cpno与SECOND的Cno等值连接即可达到查询目的。
这相当于将Course表与其自身连接后,取第一个副本的课程号与第二个副本的先修课号做为目标列中的属性。
故答案如下
SELECTFIRST.Cno,SECOND.Cpno
FROMCourseFIRST,CourseSECOND
WHEREFIRST.Cpno=SECOND.CnoANDSECOND.CpnoISNOTNULL;
注意有可能某门课的先行课的先行课为NULL
(3)外连接
●左外连接LEFTOUTERJOIN
●右外连接RIGHTOUTERJOIN
●全外连接FULLOUTERJOIN
SQL标准外连接关键字为OUTER
外连接时,OUTER常省略。
例SELECT*
FROMStudentLEFTJOINSC
ONStudent.Sno=SC.Sno
FULLJOINCourse
ONSC.Cno=Course.Cno;
(4)复合条件连接WHERE子句中有多个条件的连接操作,称为复合条件连接。
例查询选修2号课程且成绩在90分以上的信息系或计算机系学生的学号和姓名。
SELECTStudent.Sno,Sname
FROMStudent,SC
WHEREStudent.Sno=SC.Sno
AND(Student.Sdept=‘IS’ORStudent.Sdept=‘CS’)
 升级会员
升级会员 