db2purescale 集群系统cf结点文件系统丢失解决步骤.docx
《db2purescale 集群系统cf结点文件系统丢失解决步骤.docx》由会员分享,可在线阅读,更多相关《db2purescale 集群系统cf结点文件系统丢失解决步骤.docx(16页珍藏版)》请在冰豆网上搜索。
db2purescale集群系统cf结点文件系统丢失解决步骤
集群里有三个节点:
172.19.2.12(ZBBB_DB1)cf+mem,172.19.2.14(ZBBB_DB2)cf+mem;172.19.2.16(ZBBB_DB3)mem
故障现象一:
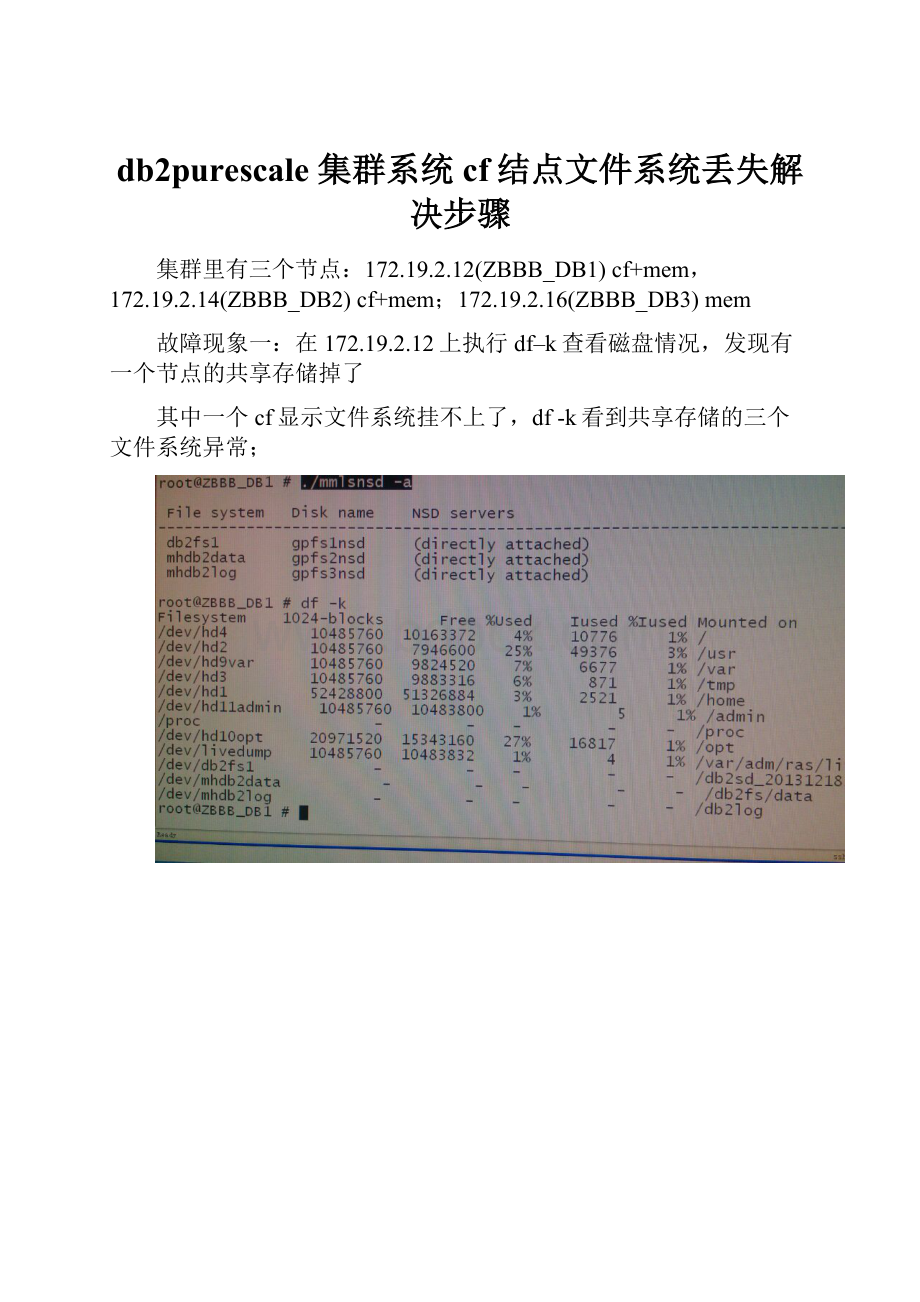
在172.19.2.12上执行df–k查看磁盘情况,发现有一个节点的共享存储掉了
其中一个cf显示文件系统挂不上了,df-k看到共享存储的三个文件系统异常;
故障现象二:
Errpt检查发现有PH报错(adapter报错,机房检查发现机器的hba1亮黄灯)。
故障现象三:
三个节点每台机器上都有两块万兆光线卡(hba),两块卡做了绑定,一块坏不应影响网络运行。
但是DB1与DB2互通;DB2与DB3互通;DB1与DB3不通。
问题:
1.节点在集群里面吗?
重新挂能挂上吗?
不知道怎么检查
2.盘掉了吗?
盘没掉(使用/usr/lpp/mmfs/bin/mmlsnsd可以查看每个文件系统的NSD配置),每个节点上的NSDservers都为“directlyattached”则说明每个节点与网络存储都是正常连接的。
NSD神马意思?
,不知道
Db2sdin1与root用户的Lspv查看结果分别为:
3.Gpfs有问题吗?
使用/usr/lpp/mmfs/bin/mmgetstat–a查看gpfs状态。
在三个节点上分别执行,发现三个节点状态不一致。
mmgetstate看到DB1处于arbitrating状态;DB2是active;DB3是unkown
此时即便在ZBBB_DB1上执行/usr/lpp/mmfs/bin/mmount–a也不能把文件系统挂载上,因为DB1不是active状态。
在ZBBB_DB1上执行/usr/lpp/mmfs/bin/mmstartup–a(这是启动所有节点),状态依旧。
在ZBBB_DB1上手工停掉GPFS,然后再启动。
在ZBBB_DB3上也执行该操作,
此时ZBBB_DB1执行/usr/lpp/mmfs/bin/mmgetstat–a查看gpfs状态发现node1和node2为active状态,node3为unknown状态;在ZBBB_DB3执行/usr/lppmmfs/bin/mmgetstat–a发现node2和node3为active;在ZBBB_DB2/usr/lppmmfs/bin/mmgetstat–a发现node1和node3为unknown状态,node2为active状态。
此现象应该是与互信导致的。
这里没有追查互信问题,继续重启了gpfs,结果数据库起不来了,在db2inst1账户下输入db2connecttoZBBB后hang住了,没有任何返回。
重开2.14窗口,db2sdin1用户下执行db2stopforce,此时三个mem都是stop状态了。
Db2sdin1>db2instance-list
只有ZBBB_DB2能执行该命令,其他两个节点均不能执行该命令。
在ZBBB_DB2或者ZBBB_DB1上执行db2stopinstanceonZBBB_DB2/ZBBB_DB1,执行成功,db2instance–list状态全部为stopped状态。
db2cluster-cm-clear–alert清空告警。
db2instance –list发现告警还在。
Hang住的sql使用ps–ef|grepdb2,找到db2pd的那些进程,手动kill掉即可结束hang的状态。
此时再次查看gpfs状态(/usr/lpp/mmfs/bin/mmgetstat–a),ZBBB_DB1看到ZBBB_DB1和ZBBB_DB2是active;ZBBB_DB2看ZBBB_DB1是unknown状态,自己是active。
但是ZBBB_DB1和ZBBB_DB2互ping能通。
Root>/opt/IBM/db2/v10.5/bin/db2cluster-cm-STOP-HOSTZBBB_DB2/1–force(在node1和node2上分别执行)
使用lsrpdomain查看cm状态是否都为offline;
在node1和node2上分别执行db2cluster-cfs-STOP-HOSTZBBB_DB2/1–force,停掉gpfs,执行后看到文件系统已卸载。
决定先甩开node3不管(等网络解决再去启动node3的cm和gpfs)
在node3上执行lsrpdomain,如为online,则
stoprpdomainb2domain_20130926120214:
/根据lsrpdomain的输出。
在node3上执行db2cluster-cfs-STOP-HOSTZBBB_DB3–force停掉gpfs。
再次检查gpfs状态:
node1与node2看到的gpfs状态仍不同。
彻底怀疑是互信问题
在node2执行mmlscluster
但是node1与node可以直接ssh。
但从上图可看出我中心的gpfs用的不是openssh,而是db2locssh(db2封装的ssh)。
(上图是使用openssh的例子)
而在ZBBB_NODE2root用户上执行/var/db2/db2ssh/db2locsshZBBB_DB1‘hostname’返回ZBBB_DB2,但是在ZBBB_DB2上root用户执行/var/db2/db2ssh/db2locsshZBBB_DB1‘hostname’
手动删掉/home/db2sdin1/.ssh/known_hosts文件中的ZBBB_NODE1和ZBBB_NODE3,然后在ZBBB_NODE2执行sshZBBB_DB1和sshZBBB_DB3手动重做互信,互信问题可能可解决。
但是此时未处理互信。
开始准备整体启动:
在每个节点检查cm与cfs是否处于maintenance
/opt/IBM/db2/V10.5/bin/db2cluster–cfs–verify–maintenance
/opt/IBM/db2/V10.5/bin/db2cluster–cm–verify–maintenance
目前都处于maintenance状态,在node1root下执行下面命令退出maintenance,启动cm
/opt/IBM/db2/V10.5/bin/db2cluster–cm-EXIT-MAINTENANCE–ALL(node2的互信有问题,不能在2上做该操作)
启动cluster:
root>db2cluster–cfs–start–all(该命令会把cluster和gpfs都启动)
在每台机器上做db2startinstanceonhostname//实例用户这个是单启动cluster的,上边命令执行完后,lsrpdomain显示节点处于online状态,所以再执行该命令时系统提示nodeisalreadyactive。
最后在mem上执行db2start,启动数据库即可。
互信问题解决前启动过数据库,启动不成功。
而后又结束。
此时互信问题问题已解决,再次启动数据库,db2instance–list显示ZBBB_DB2上的数据库启动失败。
执行db2cluster–cm–list–alert后,ZBBB_DB2尝试再次重启数据库,但是仍失败。
决定重启172.19.2.14.在德元通过crt远程reboot,
Reboot后只能telnet不能远程(ssh服务未启动
且172.19.2.14的db2sdin1无法使用db2instance、db2cluster等命令。
root在/opt/IBM/db2/V10.5/bin/db2cluster–cm–verify–resources
发现资源模型不一致(啥意思,不明白)
在root账户执行在/opt/IBM/db2/V10.5/bin/db2cluster–cm–repair–resources,报如下错误。
一直在报“ErrorOpeningClusterManager”错误。
原因不明
先不管cm了,启动试试。
在ZBBB_DB1上启动(root用户/opt/IBM/db2/V10.5/bin/db2cluster–cfs–start–all该命令会把gpfs(包括mmstartup–a作用)和domain(db2startinstanceonZBBB*)一起启动),三个节点分别看GPFS三个节点,均为active状态。
但是节点2仍无法查看domain状态lsrpdomain。
看看db2instance状态
在ZBBB_NODE1上db2sdin1用户执行db2instance–list,如下图
使用lssam查看集群资源情况,发现有offline
至此,恰好发现该状态与ibm官网一状况相似
该链接的图5
故决定去机房通过硬件控制器重启172.19.2.14(P750-2),选中该机器,restarted。
启动后,系统自动拉起GPFS。
开始启动:
root用户/opt/IBM/db2/V10.5/bin/db2cluster–cfs–start–all
检查gpfs是否均为active和domain是否为online
在db2sdin1用户下,member上执行db2start。
然后db2instance–list,启动正常。
数据入库正常。
正常状态:
实例状态
磁盘状态:
GPFS状态和domain状态:
(三个节点均如此)
集群资源组状态(全部为online,没有offline的资源)
值得学习的链接:
(目前db2purescale没有书籍可参考,基本都是参考IBM官网)
关于openssh的:
关于ibm防火墙的:
报2612-022错误时,网上有说可能是防火墙的原因,但是smit关不掉防火墙。
故除重启机器外,未找到其他解决2612-022错误的方法。
 升级会员
升级会员 