Spss大作业.docx
《Spss大作业.docx》由会员分享,可在线阅读,更多相关《Spss大作业.docx(12页珍藏版)》请在冰豆网上搜索。
Spss大作业
大作业
汽车市场研究
问题描述
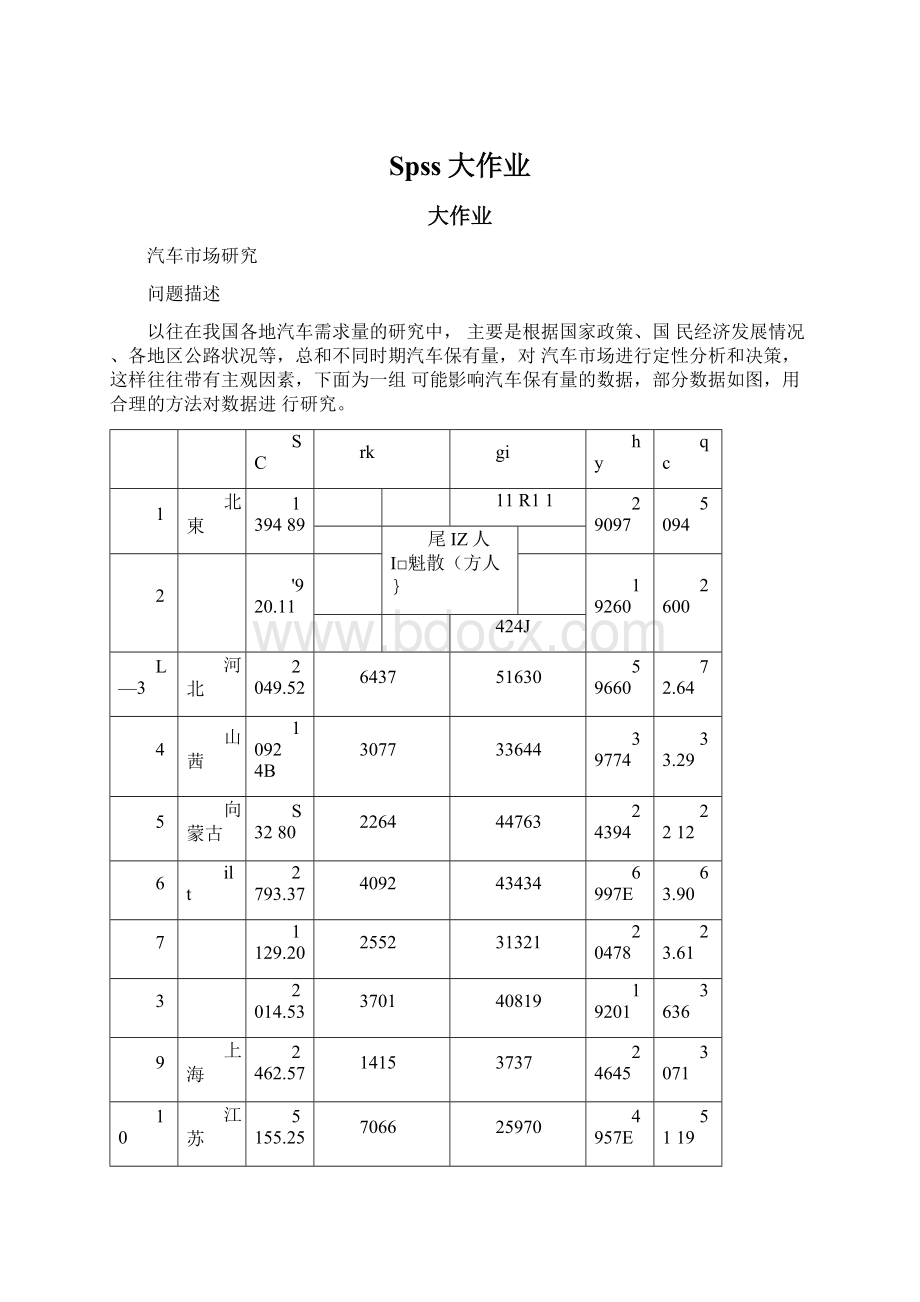
以往在我国各地汽车需求量的研究中,主要是根据国家政策、国民经济发展情况、各地区公路状况等,总和不同时期汽车保有量,对汽车市场进行定性分析和决策,这样往往带有主观因素,下面为一组可能影响汽车保有量的数据,部分数据如图,用合理的方法对数据进行研究。
SC
rk
gi
hy
qc
1
北東
139489
11R11
29097
5094
尾IZ人I□魁散(方人}
2
'920.11
19260
2600
424J
L—3
河北
2049.52
6437
51630
59660
72.64
4
山茜
10924B
3077
33644
39774
33.29
5
向蒙古
S3280
2264
44763
24394
2212
6
ilt
2793.37
4092
43434
6997E
63.90
7
1129.20
2552
31321
20478
23.61
3
2014.53
3701
40819
19201
3636
9
上海
2462.57
1415
3737
24645
3071
10
江苏
5155.25
7066
25970
4957E
5119
一层次聚类、求解思路
用层次聚类的方法,分析与预测各个地区的汽车市场发展情况
首先对原始数据进行标准化变换处理,经过运算使得每列数据的平均值为0,方差为1,这样原始数据中5列具有不同比较标准的数据就能放在一起比较;然后用标准化后的30个不同地区数据求出欧式距离;最后米用Wald离差平方和法。
、问题求解与分析
通过SPSS软件求解的结果与分析:
结果分析:
图为层次分析的凝聚状态表,第一列为聚类步骤,表示共进行了29个步骤的分析;第二列和第三列表示某部聚类分析中,哪两个样本或聚类成了一类;第四列表示两个样本或类间距,从图看出,距离小的样本之间先聚类;第五列和第六列表示某步聚类分析中,参与聚类的是样本还是类,0表示样本;第七列表示本步聚类分析结果在下面聚类的第几步中用到。
AgglomerationSchedule
Cluster
Combined
StageCluster
FirstAppears
Stag
Cluste
Cluste
Coeffici
Next
e
r1
r2
ents
Cluster1
Cluster2
Stage
1
12
16
.010
0
0
17
2
14
20
.025
0
0
15
3
7
26
.040
0
0
10
4
5
30
.056
0
0
13
5
3
4
.081
0
0
9
6
8
29
.107
0
0
23
7
24
27
.136
0
0
8
8
13
24
.169
0
7
12
9
3
15
.213
5
0
26
10
7
18
.269
3
0
24
11
19
22
.328
0
0
17
12
13
21
.395
8
0
15
13
5
17
.469
4
0
19
14
2
11
.559
0
0
20
15
13
14
.650
12
2
19
16
23
28
.766
0
0
22
17
12
19
.887
1
11
24
18
1
10
0
0
21
19
5
13
13
15
23
20
2
9
14
0
25
21
1
6
18
0
25
22
23
25
16
0
27
23
5
8
19
6
27
24
7
12
10
17
26
25
1
2
21
20
29
26
3
7
9
24
28
27
5
23
23
22
28
28
3
5
26
27
29
29
1
3
25
28
0
结果分析:
图将30个样本分为三类,
第一类包括1、2、6、9、10、11,
Cluster
Membership
Case
3
Cluster
s
1:
北京
1
2:
天津
1
3:
河北
2
4:
山西
2
5:
内蒙
古
3
6:
辽宁
1
7:
吉林
2
8:
黑龙
江
3
9:
上海
1
10:
江
苏
1
11:
浙
江
1
12:
安
徽
2
13:
福
建
3
14:
江
西
3
15:
山
东
2
16:
河
南
2
17:
湖
北
3
18:
湖
南
2
19:
广
东
2
20:
广
西
3
21:
海
南
3
22:
四
川
2
23:
贵
州
3
24:
云
南
3
25:
西
藏
3
26:
陕
西
2
27:
甘
肃
3
28:
青
海
3
29:
宁
夏
3
30:
新
3
疆
结果分析:
图是层次聚类分析的树形图,由于部分样本或小类之间的距离较小,因此光从该图很难清晰看出哪几个样本先聚类,这时应借助于图进行判别。
*******************H
IERARCHICALCLUSTER
ANALYSIS***********
Rescaled
DistaneeClusterCombine
CASE
10
1520
安徽
12
河南
16
广东
19
四川
22
吉林
7
陕
西
26k
1
湖
南
181
河
北
3—
东15
I
贵
州23
青
海28
西
藏25
黑龙
江8
I
夏29
内蒙
古5
新
疆30
湖
北17
江
西14
24
肃27
建13
南21
天
津2
浙
江11
上
海9
I
北京11
江苏10k
辽宁
I
总分析:
第一类反应的是我国经济发展较发达地区与相对欠发达地区。
1、2、9代表为北京、天津、上海三个直辖市,在全国具有举足轻重的地位,它们的汽车市场发展仍将处于全国领先水平;6、10、11代表辽宁、江苏、浙江,由于地理、人口、气候及交通等原因,汽车市场的发展将作为今后发展的重要因素,带动这些地区经济的腾飞。
第二类中10个元素,分别代表陕西、山东、陕西等,这些地区从经济发展看处于中等水平,将是今后汽车发展的大市场。
第三类为内蒙古、宁夏、新疆等,这些地区相对来说经济发展较慢,汽车发展空间不大。
二多元线性回归分析
求解思路
用多远线性回归的方法,分析国内生产总值、地区人口总数、地区公路长度、全社会货运量对汽车保有量是否有影响。
首先自变量强制进入,不用管个因素质量如何,对回归方程是否有影响;然后选择输出默认输出项,输出回归系数的标准误差、标准回归系数等;最后选择Modelfit和Descriptives,输出判定系数、自变量与因变量的均值、标准差等。
问题求解与分析通过SPSS软件求解的结果与分析:
DescriptiveStatistics
Mean
Std.
Deviation
N
汽车总保有量
(万辆)
30
国内生产总值
(亿元)
30
地区人口总数
(万人)
30
地区公路长度
(km)
30
全社会货运量
(万吨)
30
结果分析:
图为四个自变量和一个因变量的平均值、方差和个案数为
30。
VariablesEntered/Removed
Model
Variables
Entered
Variables
Removed
Method
1
全社会货运量
(万吨),地区公路长度
(km,国内生产总值(亿元),地区人口总数(万人)a
.
Enter
a.Allrequestedvariablesentered.
VariablesEntered/Removed
Model
Variables
Entered
Variables
Removed
Method
1
全社会货运量
(万吨),地区公路长度
(km),国内生产总值(亿元),地区人口总数(万人)a
.
Enter
b.DependentVariable:
汽车总保有量(万辆)
结果分析:
图2.2中第二列为被引入的变量,第三列为从回归方程中被剔除的各个变量,第四列为进入方式。
ModelSummary
Model
R
RSquare
AdjustedR
Square
Std.ErroroftheEstimate
1
.916a
.838
.812
a.Predictors:
(Constant),全社会货运量(万吨),地
区公路长度(km,国内生产总值(亿元),地区人口
总数(万人)
图
结果分析:
图输出常用统计量关系数R为,调整的判定系数为,回归
估计的标准误差s=。
anoVA
Model
Sumof
Squares
df
Mean
Square
F
Sig.
1Regressi
4
.000a
on
Residual
25
Total
29
a.Predictors:
(Constant),全社会货运量(万吨),地区公
路长度(km,国内生产总值(亿元),地区人口总数(万人)
b.DependentVariable:
汽车总保有量(万辆)
图
结果分析:
图为方差分析表,统计量F二;相伴概率p=0,说明多个变量
与因变量之间存在线性回归关系。
Coefficients
Model
Unstandardized
Coefficients
Standardized
Coefficients
t
Sig.
B
Std.
Error
Beta
1(Constant)
.404
.690
国内生产总值
(亿元)
.010
.003
.606
.002
地区人口总数
(万人)
.002
.009
地区公路长度
(km
.000
.000
.237
.100
全社会货运量
(万吨)
.001
.000
.603
.002
a.DependentVariable:
汽车总保有量(万
辆)
图
结果分析:
图为回归系数分析,UnstandardizedCoefficients为非
标准化系数,StandardizedCoefficients为标准化系数,t为回归系数检验统计量,Sig为相伴概率,从图看出各个自变量与因变量的线性回归分析关系不显著。
总分析:
四个因变量对因变量的影响作用不显著
 升级会员
升级会员 