低密度奇偶检验码.docx
《低密度奇偶检验码.docx》由会员分享,可在线阅读,更多相关《低密度奇偶检验码.docx(9页珍藏版)》请在冰豆网上搜索。
低密度奇偶检验码
低密度奇偶检验码(LDPCcode)
前言:
LDPC码是麻省理工学院RobertGallager于1962年在博士论文中提出的一种具有稀疏校验矩阵的分组纠错码。
几乎适用于所有的信道,因此成为编码界近年来的研究热点。
它的性能逼近香农限,且描述和实现简单,易于进行理论分析和研究,译码简单且可实行并行操作,适合硬件实现。
LDPC码-简介
任何一个(n,k)分组码,如果其信息元与监督元之间的关系是线性的,即能用一个线性方程来描述的,就称为线性分组码。
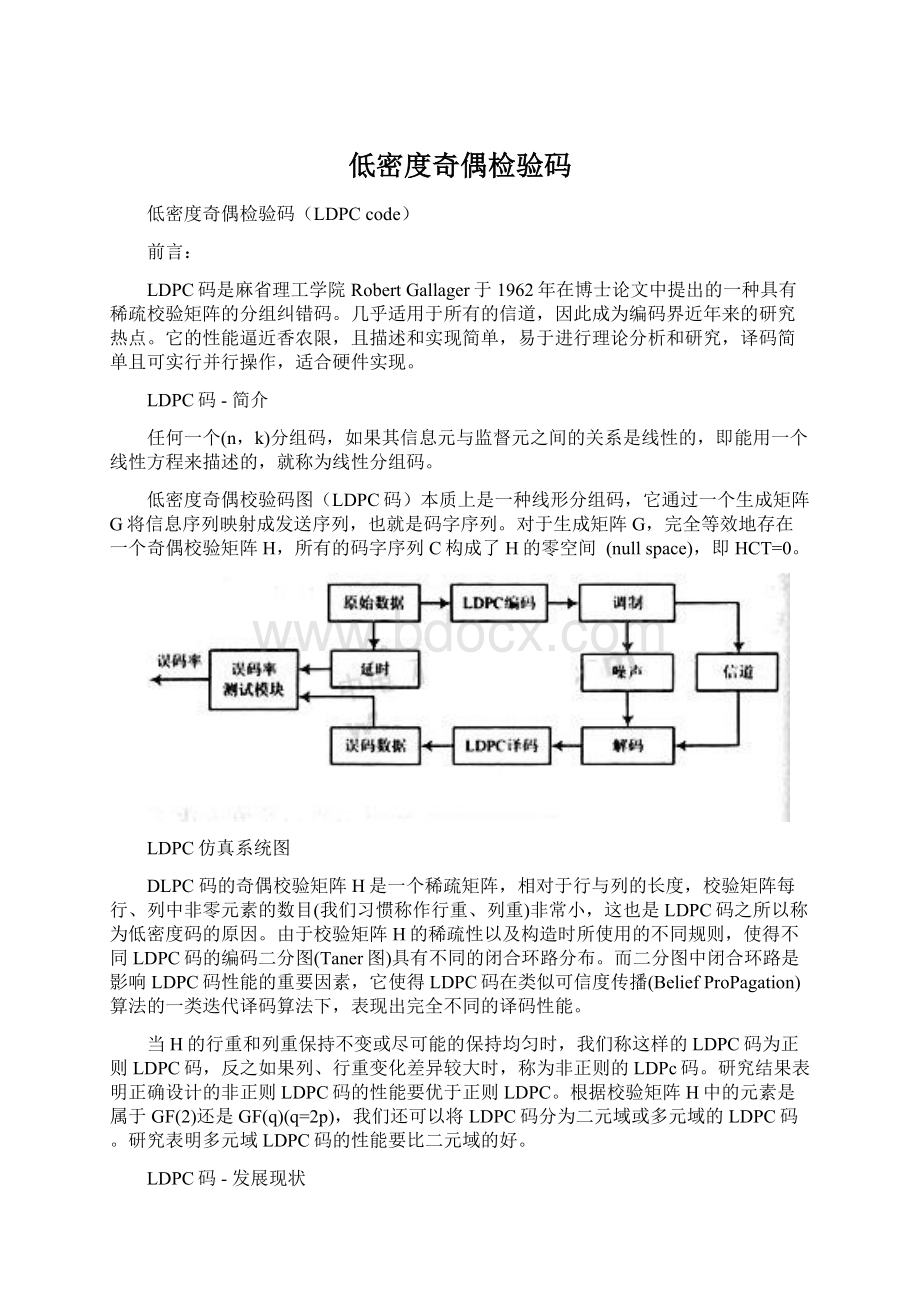
低密度奇偶校验码图(LDPC码)本质上是一种线形分组码,它通过一个生成矩阵G将信息序列映射成发送序列,也就是码字序列。
对于生成矩阵G,完全等效地存在一个奇偶校验矩阵H,所有的码字序列C构成了H的零空间 (nullspace),即HCT=0。
LDPC仿真系统图
DLPC码的奇偶校验矩阵H是一个稀疏矩阵,相对于行与列的长度,校验矩阵每行、列中非零元素的数目(我们习惯称作行重、列重)非常小,这也是LDPC码之所以称为低密度码的原因。
由于校验矩阵H的稀疏性以及构造时所使用的不同规则,使得不同LDPC码的编码二分图(Taner图)具有不同的闭合环路分布。
而二分图中闭合环路是影响LDPC码性能的重要因素,它使得LDPC码在类似可信度传播(BeliefProPagation)算法的一类迭代译码算法下,表现出完全不同的译码性能。
当H的行重和列重保持不变或尽可能的保持均匀时,我们称这样的LDPC码为正则LDPC码,反之如果列、行重变化差异较大时,称为非正则的LDPc码。
研究结果表明正确设计的非正则LDPC码的性能要优于正则LDPC。
根据校验矩阵H中的元素是属于GF
(2)还是GF(q)(q=2p),我们还可以将LDPC码分为二元域或多元域的LDPC码。
研究表明多元域LDPC码的性能要比二元域的好。
LDPC码-发展现状
LDPC码
LDPC(Low-densityParity-check,低密度奇偶校验)码是由Gallager在1963年提出的一类具有稀疏校验矩阵的线性分组码(linearblockcodes),然而在接下来的30年来由于计算能力的不足,它一直被人们忽视。
1993年,DMacKay、MNeal等人对它重新进行了研究,发现LDPC码具有逼近香农限的优异性能。
并且具有译码复杂度低、可并行译码以及译码错误的可检测性等特点,从而成为了信道编码理论新的研究热点。
Mckay,Luby提出的非正则LDPC码将LDPC码的概念推广。
非正则LDPC码的性能不仅优于正则LDPC码,甚至还优于Turbo码的性能,是目前己知的最接近香农限的码。
Richardson和Urbank也为LDPC码的发展做出了巨大的贡献。
首先,他们提出了一种新的编码算法,在很大程度上减轻了随机构造的LDPC码在编码上的巨大运算量需求和存储量需求。
其次,他们发明了密度演进理论,能够有效的分析出一大类LDPC译码算法的译码门限。
仿真结果表明,这是一个紧致的译码门限。
最后,密度演进理论还可以用于指导非正则LDPC码的设计,以获得尽可能优秀的性能。
LDPC系统结构框图
LDPC码具有巨大的应用潜力,将在深空通信、光纤通信、卫星数字视频、数字水印、磁/光/全息存储、移动和固定无线通信、电缆调制/解调器和数字用户线(DSL)中得到广泛应用。
M.Chiain等对LDPC码用于有记忆衰落信道时的性能进行了评估。
B.Myher提出一种速率自适应LDPC编码调制的方案用于慢变化平坦衰落信道,经推广还可用于FEC-ARQ系统。
Flarino开发的集成了V-DLPC的flash-OFDM移动无线芯片组己可用于基于IP的移动宽带网。
VOCALTechnologies.Ltd提出了一种用于WLAN的LDPC/Turbo不对称解决方案,即下行链路采用LDPC码,上行链路采用Turbo码。
研究表明采用该方案后用于IEEE802.11a/b/gWLAN移动终端的电池寿命可延长至原来的4倍。
工业界也己经有LDPC编译码芯片问世。
其中,处于领先地位的Flarion公司推出的基于ASIC的Vector-LDPC解决方案使用了约260万门,最高可以支持50000的码长,0.9的码率,最大迭代次数为10,译码器可以达到10Gbps的吞吐量,其性能己经非常接近香农限,可以满足目前大多数通信业务的需求。
AHA公司、DigitalFountain公司也都推出了自己的编译码解决方案。
LDPC码-因子图(二分图)表示
为了分析方便,我们一般用因子图来表示一个LDPC码。
因子图上所有的代码点可以分成互不相关的两类,我们称之为信息点和校验点。
因子图上的边以一定的规律把它们连接起来,但是同一类中的代码点不能用边连接起来。
事实上因子图与用来定义码字的奇偶校验矩阵H是相对应的,即因子图上的变量节点对应矩阵H的列向量,校验节点对应因子图上的行向量,而矩阵中非零元素就对应因子图上的每一条边。
在定义新的码字时,每一次构造的码字在二进制矢量域中定义为x=(x1,x2,…,xn)。
当且仅当方程Hx=0时为一码字,也就是说,当且仅当每一个校验点的相邻变量节点的异或值为0时,对应的二进制矢量x=(x1,x2,…,xn)才是一个码字。
假设因子图上每一个变量节点的度数是丫,每一个校验点的度数是P,节点的次数为与该节点相联边的个数。
如果Y,P相对于码字总长n来说很小,则该因子图对应的奇偶校验矩阵是稀疏矩阵。
一个码长n=6,码率r=1/3,列重Y=2,行重P=3的校验矩阵H和其对应的因子图如下:
校验矩阵
因子图
LDPC码-非正规与正规LDPC码
在LDPC码的校验矩阵中,如果行列重量固定为(P,Y),即每个校验节点有P个变量节点参与校验,每个变量节点参与Y个校验节点,我们称之为正则LDPC码。
Gallager最初提出的Gallager码就具有这种性质。
从编码二分图的角度来看,这种LDPC码的变量节点度数全部为Y,而校验节点的度数都为P。
我们还可以适当放宽上述正则LDPC码的条件,行列重量的均值可以不是一个整数,但行列重量尽量服从均匀分布。
另外为了保证LDPC码的二分图上不存在长度为4的圈。
我们通常要求行与行以及列与列之间的交叠部分重量不超过1,所谓交叠部分即任意两列或两行的相同部分。
我们可以将正则LDPC码校验矩阵H的特征概括如下:
1.H的每行行重固定为P,每列列重固定为Y。
2.任意两行(列)之间同为1的列(行)数(称为重叠数)不超过1,即H矩阵中不含四角为1的小方阵,也即无4线循环。
3.行重P和列重Y相对于H的行数M、列数N很小,H是个稀疏矩阵。
在正则LDPC码的校验矩阵中。
行重和列重的均值保持不变,所以校验矩阵中1的个数随着码长的增加而线性增长,整个校验矩阵的元素个数则成平方增长。
当码长达到一定长度时,校验矩阵H是非常稀疏的低密度矩阵。
对于正则的LDPC码,MacKay给出了以下两个结论:
1.对于任意给定列重大于3的LDPC码,存在某个小于信道传输容量且大于零的速率r,当码长足够长时,可以实现以小于r且不为零的速率无差错的传输。
也就是说任意给定一个不为零的传输速率r,存在一个小于相应香农限的噪声门限,当信道噪声低于该门限且码长足够长的时候,可以实现以r速率无差错的传输。
2.当LDPC码的校验矩阵H的列重Y不固定,而是根据信道特性和传输速率来确定时,则一定可以找到一个最佳码,实现在任意小于信道传输容量的速率下无差错的传输。
对于LDPCP码的每个变量节点来说,当它参与的校验式越多,即度数Y越大,则它可以从更多的校验节点获取信息,也就可以更加准确的判断出它的正确值。
对于H的每个校验节点来说,当它涉及的变量节点越少,即度数P越小,则它可以更准确的估计相关变量节点的状态。
这种情况对于正则LDPc码来说是一对不可克服的矛盾,于是Luby,Mitzemnacher等人就引入了非正则LDPC码的概念。
在非正则LDPC码的编码二分图中,两个集合内部的节点度数不再保持相同,即每个变量节点参与的校验式数目或每个校验式中含有的变量节点数目不再保持均匀,而是有意设置部分突出的变量节点和校验节点。
在译码过程中,那些参与较多校验式的变量节点迅速得到它们的正确译码信息,这样它们就可以给相邻的校验节点更加有效的概率信息,而这些校验节点又可以给与它们相邻的次数少的变量节点更多的信息。
整个译码的过程呈现出一种波状效应,次数越高的变量节点首先获得正确信息,然后是次数较低的节点,然后依次往下,直到次数最低的变量节点。
正是这种波状效应,使得非正则LDPC码获得比正则LDPC更好的译码性能。
LDPC码-二元域与多元域LDPC码
对DLPC码的定义都是在二元域基础上的,MaKcay对上述二元域的LDPC码又进行了推广。
如果定义中的域不限于二元域就可以得到多元域GF(q)上的LDPC码。
多元域上的LDPC码具有较二进制LDPC码更好的性能,而且实践表明在越大的域上构造的LDPC码,译码性能就越好,比如在GF(16)上构造的正则码性能己经和Turbo码相差无几。
多元域LDPC码之所以拥有如此优异的性能,是因为它有比二元域LDPC码更重的列重,同时还有和二元域LDPC码相似的二分图结构。
假设在域GF
(2)和域GF(q)(q=2p)上构造的LDCP码所对应的校验矩阵分别是H2和Hq。
H2中的元素是0或1,而Hq是由元素0,1,…,q-1构成,Hq中的每个元素都是H2中p个元素的合成。
如果设域GF(q)(q=2p)上的一个值a与一个1*p的二进制向量相关联,那么把这个向量代入Hq中,就可以得到Hq的二进制表示。
对于二进制LDPc码来说,如果它的校验矩阵H的列重量足够大,那么它可以任意地接近香农限,但是如果增加列重量会使得二分图中节点之间短圈的数H急剧增加从而使BP算法的性能下降。
而在GF(q)域上构造的LDPC可以解决这个矛盾,它的检验矩阵H。
可以增加与之对应的二进制校验矩阵HZ中列的平均重量,且它的二分图结构并没有改变,不会造成节点之间短圈数目的增加,从而使得译码性能得到显著的提高。
这种多元域上的编码构造会增加译码复杂度,但是相对于译码性能的提高来说这种增加是值得的。
LDPC码-码的构造
对LDPC码来说,不考虑码长和次数分布的情况下,校验矩阵的结构就成了影响其性能的重要因素,反映在二分图上对编码性能有重要影响的就是图中环的长度分布,需要采用一定的方法对校验矩阵进行构造,获得好的编码。
目前LDPC码的构造方法主要可以分为两大类:
随机或伪随机构造方法和代数的构造方法。
随机或伪随机的构造方法主要考虑的是码的性能,在码长比较长(接近或超过10000)时,性能非常接近香农限。
代数的构造方法通常考虑的是降低编译码的复杂度,在码长比较短的时候更有优势。
1.GallagerLDPC码
用和乘积算法(SPA:
Sum-pordcuctalgorithm)进行译码取得最大后验概率的译码性能的条件是二分图中没有小的环,即girth为4的环,无4环的条件反映到二分图中就是任意两行中1的交迭数目不超过1个。
无4环的二元高比特率LDPc码可以通过随机生成行构成,一般来说,这种方法不能生成固定行重量的矩阵。
Gallaegr提出了一种替代的方法:
采用随机置换的方法来构造规则DLPC码。
对于码长为N的(j,k)正则码,将M*N矩阵H通过j个大小为(M/j)*N的子矩阵构成,每个子矩阵本身也是LDPC矩阵,列重量为1,行重量为k,第一个子矩阵为阶梯型,即第1行的k个1的列号是从(i-1)*kl到1*k,而其他子矩阵都是第一个子矩阵的随机列置换,这样每个子矩阵每行都有k个1,每列都有1个1。
这种构造方法要求M必须是j的整数倍。
(20,3,4)LDPC码的校验矩阵
Gallager曾给出了一个码长为20的规则(3,4)LDPC码的校验矩阵,如图所示。
图中的第一个子矩阵就是一个阶梯型矩阵,而第2个和第3个矩阵都是第一个子矩阵的列置换。
Gallager同时证明了随机置换得到的GaHagerLDPC码的最小汉明距离能够随着码长的增加而线性增加,而且在对称无记忆信道中,采用最大似然译码时,其误码率随着码长的增加而呈指数形式下降,这说明随机置换得到的GallagerLDPC码是一类相当好的码。
但是,Gallager在构造LDPC码时采用的是随机置换,这就给实现带来了麻烦,就需要大量的存储单元来存储校验矩阵中这些1的位置。
2.确定性结构的LDPC码
确定性结构的DLPC码也称为准循环LDPC码。
相对于随机结构的矩阵是很容易获得的确定性结构的矩阵,这种矩阵可以通过更少的参数来定义LDPC码。
确定性结构的LDPC码的构造方法基于“阵列码”(ArrayCode)。
阵列码是用来检测和纠正突发差错的二维码。
通过三个参数定义LDPC码。
一个基本参数p和两个整数j和k。
令H为jp*kp的矩阵,定义为:
LDPC码
其中这里的I是p*p的单位阵,Bi.j是Ip*p的左循环移位Bm.n或右循环移位Bm.n的置换矩阵。
显然,H矩阵中1的分布就只与循环位数Bm.n有关。
对LDPC码的分析就可以转换为对Bm.n的分析。
将各小矩阵的循环移动位数写成一个矩阵为
LDPC码
上面的校验矩阵提供了一个可以用于SAP译码的稀疏矩阵。
而且,这个校验矩阵结构上没有四线循环。
LDPC码-译码算法
DLPC码编码是在通信系统的发送端进行的,在接收端进行相应的译码,这样才能实现编码的纠错。
LDPC码由于其奇偶校验矩阵的稀疏性,使其存在高效的译码算法,其复杂度与码长成线性关系,克服了分组码在码长很大时,所面临的巨大译码算法复杂度问题,使长码分组的应用成为可能。
而且由于校验矩阵稀疏,使得在长码时,相距很远的信息比特参与统一校验,这使得连续的突发差错对译码的影响不大,编码本身就具有抗突发错误的特性。
LDPC码的译码算法种类很多,其中大部分可以被归结到信息传递〔MesasegPrpagation,MP)算法集中。
这一类译码算法由于具有良好的性能和严格的数学结构,使得译码性能的定量分析成为可能,因此特别受到关注。
MP算法集中的置信传播(BP)算法是Gallager提出的一种软输入迭代译码算法,具有最好的性能。
如果我们首先理解并掌握了一些很简单的硬判决算法后,对BP算法的理解会更加容易。
同时,通过一些常用的数学手段,我们可以对BP译码算法作一些简化,从而在一定的性能损失内获得对运算量和存储量需求的降低。
LDPC码-发展前景
LDPC码具有很好的性能,译码也十分方便。
特别是在GF(q)域上的非规则码,在非规则双向图中,当各变量节点与校验节点的度数选择合适时,其性能非常接近香农限。
今后,LDPC码的研究方向主要有:
(1)码的设计;
(2)选择合适的硬件(以降低编译码的运算复杂性);
(3)LDPC码应用于下一代通信系统。
目前,LDPC码已成为第四代移动通信编码技术中的首选。
LDPC码VSTurbo码
和另一种近Shannon限的码-Turbo码相比较,LDPC码主要有以下几个优势:
1.LDPC码的译码算法,是一种基于稀疏矩阵的并行迭代译码算法,运算量要低于Turbo码译码算法,并且由于结构并行的特点,在硬件实现上比较容易。
因此在大容量通信应用中,LDPC码更具有优势。
2.LDPC码的码率可以任意构造,有更大的灵活性。
而Turbo码只能通过打孔来达到高码率,这样打孔图案的选择就需要十分慎重的考虑,否则会造成性能上较大的损失。
Trubo码编码器结构
3.LDPC码具有更低的错误平层,可以应用于有线通信、深空通信以及磁盘存储工业等对误码率要求更加苛刻的场合。
而Turbo码的错误平层在10量级上,应用于类似场合中,一般需要和外码级联才能达到要求。
4.LDPC码是上个世纪六十年代发明的,现在,在理论和概念上不再有什么秘密,因此在知识产权和专利上不再有麻烦。
这一点给进入通信领域较晚的国家和公司,提供了一个很好的发展机会。
而LDPC码的劣势在于:
1.硬件资源需求比较大。
全并行的译码结构对计算单元和存储单元的需求都很大。
2.编码比较复杂,更好的编码算法还有待研究。
同时,由于需要在码长比较长的情况才能充分体现性能上的优势,所以编码时延也比较大。
3.相对而言出现比较晚,工业界支持还不够。
 升级会员
升级会员 