空间统计空间数据预处理.docx
《空间统计空间数据预处理.docx》由会员分享,可在线阅读,更多相关《空间统计空间数据预处理.docx(29页珍藏版)》请在冰豆网上搜索。
空间统计空间数据预处理
第1章空间数据处理
1.
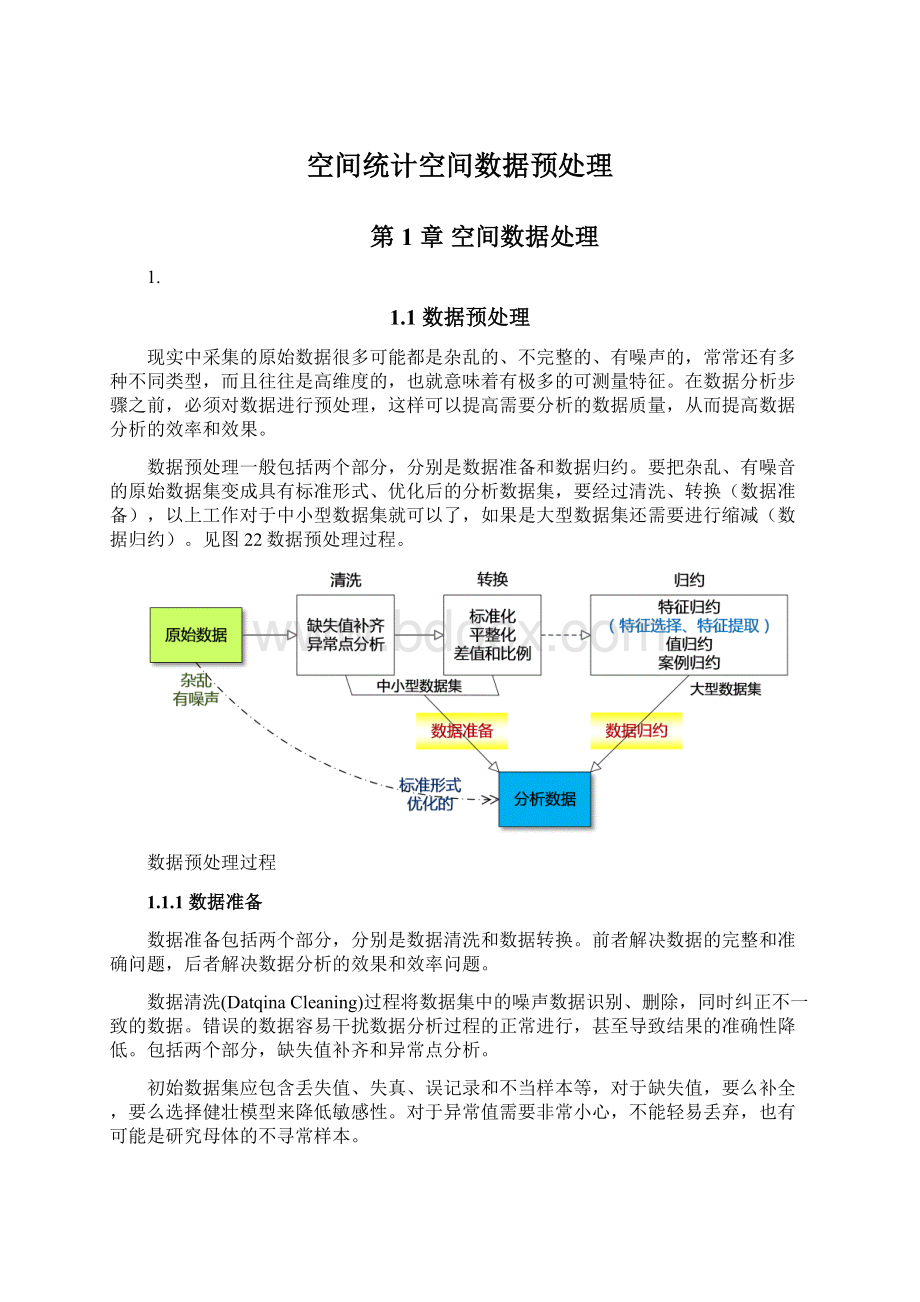
1.1数据预处理
现实中采集的原始数据很多可能都是杂乱的、不完整的、有噪声的,常常还有多种不同类型,而且往往是高维度的,也就意味着有极多的可测量特征。
在数据分析步骤之前,必须对数据进行预处理,这样可以提高需要分析的数据质量,从而提高数据分析的效率和效果。
数据预处理一般包括两个部分,分别是数据准备和数据归约。
要把杂乱、有噪音的原始数据集变成具有标准形式、优化后的分析数据集,要经过清洗、转换(数据准备),以上工作对于中小型数据集就可以了,如果是大型数据集还需要进行缩减(数据归约)。
见图22数据预处理过程。
数据预处理过程
1.1.1数据准备
数据准备包括两个部分,分别是数据清洗和数据转换。
前者解决数据的完整和准确问题,后者解决数据分析的效果和效率问题。
数据清洗(DatqinaCleaning)过程将数据集中的噪声数据识别、删除,同时纠正不一致的数据。
错误的数据容易干扰数据分析过程的正常进行,甚至导致结果的准确性降低。
包括两个部分,缺失值补齐和异常点分析。
初始数据集应包含丢失值、失真、误记录和不当样本等,对于缺失值,要么补全,要么选择健壮模型来降低敏感性。
对于异常值需要非常小心,不能轻易丢弃,也有可能是研究母体的不寻常样本。
一些数据分析方法可以接受丢失值,其他方法则需要所有的值。
若样本足够大可以去除包含丢失值的所有样本,否则需要补齐缺失值。
一般可以采用三种方法。
首先,对于数量较小的数据,可以手动检查缺失值样本,根据经验加入可能的合理的值,但这样做可能会引入一个噪点值。
其次,可以应用一些常量自动替换缺失值,如使用一个全局常量、特征平均值、给定类型的特征平均值去替换缺失值。
这样可能会形成一个未经客观证明的正因素。
最后,可以生成一个预测模型来推断每个丢失值。
如果丢失值总能预测就证明这个特征在数据集中是冗余的,带有丢失值的特征和其他特征之间的关联应该是不完全的。
不是所有的自动方法都能补上正确的丢失值。
通常有一些样本不符合数据模型的一般规则,这些样本和其他数据有很大的不同,叫做异常点。
如年龄为负数,子女达到23个,前者肯定错误,后者不寻常,需要核对。
需要在数据中检测出异常观察值,并在适当时候去出。
自动去处异常点时要非常小心,因为所去处的异常数据可能是正确的,而且包含重要的隐藏信息。
寻找异常点分为两个步骤,首先找出“正常”行为规律,然后使用“正常”规律来检测结果。
常用方法主要有图形或可视化技术,基于统计、距离、模型的技术。
数据转换(DataTransformation)操作,是指将数据源数据变换为适合数据分析的数据形式。
有三种方法,标准化、数据平整、差值和比例。
将测量值按照比例映射到一个特定范围,如[-1,1],[0,100],等,常用的三种简单方法包括小数缩放、最小-最大标准化、标准差标准化。
数值型特征y可能包含许多有微小差别的值,如对于数据集{0.99,0.98,1.03,2.97,3.06},通过下舍上入,给定精度平整化后应该为{1,1,1,3,3}。
对于数据分析来说,这些差别并不重要,让其保留不仅消耗大量计算资源,而且影响分析结果。
即使对特征很小的改变,也能显著地提高数据分析的能力,两类简单转换,差值和比例可以改进对目标描述。
如实际数据分析应用范围包括时间强相关、时间弱相关、时间无关问题。
在空间统计分析中,常常会涉及到时间问题,因此对含时间数据的准备和转换非常重要。
如某个地区每4个小时测量的PM2.5读数就是一个典型一元时间序列问题。
在这个问题中,变量X在某个时点的值应和它的以前值有关系。
其值序列可表示如下:
X={t
(1),t
(2),…,t(n)},其中,t(n)是最近的观察值。
多数情况下,把t(n+1)-t(n)作为预测结果比t(n+1)更好,同样,t(n+1)/t(n)比率揭示了变化率,有时用这个比值能得到更好的预测结果。
以上描述了数据准备阶段涉及到的数据清洗和数据转换内容,对于大型数据集来说,以上的结果数据维度太大,特征值的取值范围太广、样本量太大,会消耗太多的计算资源,分析结果不一定好,所以需要化简,就是要进行数据归约。
数据归约包括三种方法,特征规约、值规约和案例规约。
1.1.2数据归约
数据归约(DataReduction)策略是从一个大型数据集中得到一个小型的数据集,并且这个小型数据集有原数据集的完整性。
小型是指在特征数量、取值结果、样本数量上相较于原始数据都要小。
使用该小型数据集进行数据分析可以使计算效率更高,并且分析结果与使用原数据样本集的结果基本相同。
实际上是对原始数据集的一个保真约减过程,以便于数据分析时聚焦和降低计算复杂度。
大多数现实中的数据维度都很高,但是并非所有特征都很重要,甚至可能包含许多不相干的干扰信息,造成所谓的“维度灾害”。
通过减少数据维度不仅可以加快计算速度,还能确保合理的准确性。
因此需要特征规约,维规约技术即可以把已有的特征转换为一组新的规约特征,还可以选择已有特征的一个子集,前者是“特征提取”,后者是“特征选择”。
二者都是一个降维操作。
用新的较小的包含了输入所有特征的函数得到的特征集来表达就是特征提取。
结果维度是初始维度的线性或非线性组合。
常用方法包括因子分析(FA)、独立成份分析(ICA)和多维缩放(MDS)。
从数据中删除大多数非相关特征和冗余特征,选择出相关特征的一个子集就是特征选择。
需要对特征的重要性进行计算并排序,然后根据排序确定选择哪些靠前的特征。
常用的有Relief算法,熵度量方法,主成分分析等方法。
值规约就是减少已知特征的离散值数目。
技术上是将连续性特征的值离散到少量区间,对每个区间赋予一个离散符号。
从而达到简化技术描述,数据及分析结果易于理解。
传统的离散化是根据以前特征知识手工完成的,如人的年龄指定为连续型变量(0~150岁),实际中可以分为几段:
儿童、青少年、成人、中年、老年。
这种规约有两个问题,怎样确定分割点,怎样选择区间表述。
而在自动离散化有如下技术,如根据均值和众数将值进行分箱处理,还有一种是利用𝝌2统计进行自动离散的ChiMerge技术。
案例规约是在已经进行了数据准备的数据集中选出一个有代表性样本子集。
确定适当子集大小,需要考虑计算成本、存储要求、估计量精度、算法和数据的其他特性等因素。
通常,子集的大小要满足如下条件:
使整个数据集的估计误差不超过样本规定的误差限𝛿。
根据取样方法的应用范围来分,可以分为普通用途和特殊用途的。
一般只针对属于前者的技术,一种是系统化取样,如等距取样,第二种是随机取样,这是使用最多的,包括不放回和放回两种方式。
第三种是分层取样,第四种是逆取样。
总而言之,数据源中的数据一般都是含有噪声、不完整、不一致、高维度、过多取值、数量庞大。
所以对数据源数据通过数据准备和数据归约进行预处理是十分重要的。
从而提高数据质量,提高数据分析结果的有效性和准确性。
数据预处理过程
数据预处理思维导图如上。
在其步骤中并非都是必选的,更具实际情况进行选择。
1.2空间数据整理
在我国监测数据采取统一上报的形式,因此监测数据一般是存储在数据库中的,在录入数据时是某一地区某一样本检测某一物质为录入的一条数据,例如食品污染物监测数据的原始数据格式如表21所示。
但该数据格式无法直接连接到ArcMap中,必须经过一些必要的数据整理,使之变成一个地区某一污染物含量为一个值,如表22所示。
全国各省大米污染物监测数据
样品编号
监测单位地区
样品名称
检测物质类别
检测值
#######11
湖南省
早籼米
镉
#
#######11
湖南省
早籼米
总汞
#
#######11
湖南省
早籼米
铅
#
#######11
湖南省
早籼米
总砷
#
#######12
湖北省
晚稻153
镉
#
#######12
湖北省
晚稻153
总汞
#
#######12
湖北省
晚稻153
铅
#
#######12
湖北省
晚稻153
总砷
#
注:
#为任意值
全国各省大米污染物平均水平
监测单位地区
镉
总汞
总砷
铅
河北省
#######
#######
########
########
湖南省
#######
#######
########
########
湖北省
#######
#######
########
########
四川省
#######
#######
########
########
注:
#为任意值
【案例21】
利用Excel和R软件,将数据库导出的数据整理成可以导入ArcMap的数据形式。
本节所用的数据为全国各省矢量地图(sheng.shp)、食品稻谷污染物数据(全国稻谷污染物数据.csv,数据为随机生成数据),数据在光盘中获取。
部分数据分别展示如表23、图25、图26所示。
案例分析导图
图24数据整理思维导图
(1)了解数据
表23全国稻谷污染物数据(模拟数据)
样品产地
样品编号
样品名称
污染物类别
检测值
安徽省
1
稻谷
镉
0.0873
安徽省
2
稻谷
镉
0.156
安徽省
3
稻谷
镉
0.0619
安徽省
4
稻谷
镉
0.147
安徽省
5
稻谷
镉
0.0543
安徽省
6
稻谷
镉
0.633
安徽省
7
稻谷
镉
0.0988
安徽省
8
稻谷
镉
0.403
安徽省
9
稻谷
镉
0.125
安徽省
10
稻谷
镉
0.0725
图25全国地理数据属性
图26全国地市地图
(2)数据变形
首先使用R软件将一维数据变多维数据,R语言程序如下:
步骤1:
去除R工作空间中可能遗留的变量。
rm(list=ls())
步骤2:
加载数据变形命令包,第一次使用前必须先进行安装,在弹出的镜像中就近选择,如“Beijing”。
install.packages("reshape")
步骤3:
设置R的工作目录为数据文件所在目录,并读取数据。
一般数据保存为.csv格式,header=T说明表中第一行为目录。
rice<-read.csv("C:
\\Example\\Data\\2.1CleanData\\全国稻谷污染物数据.csv",header=T)
步骤4:
数据变形。
cast命令使用方法如下:
cast(data,formula=...~variable,fun.aggregate=NULL,value=guess_value(data))
其中:
data:
需要变形的数据集
formula:
变形公式,格式参照变形后目录顺序,“~”右边为需要变为目录的变量,在该例中为各种污染物的检测污染物。
fun.gggregate:
对数据的计算,取mean时表示符合某条件的值有一个时,对应值为原值,当符合某条件的值有多个时,对应值为平均值。
guess_value(data):
指定将该数据从一维变为多维,在这里是各种污染物的检测值。
library("reshape")
rice1<-cast(rice,样品产地+样品编号+样品名称+采样日期~污染物类别,mean,value=”检测值”)
得到的数据形式如表24所示:
表24全国各省大米污染物监测数据
样品产地
样品编号
样品名称
镉
铅
总铬
总汞
总砷
安徽省
1
稻谷
0.0873
-0.0035
0.0819
-0.0035
0.191
安徽省
2
稻谷
0.156
-0.0035
0.0724
-0.0035
0.171
安徽省
3
稻谷
0.0619
0.239
0.104
0.0054
0.182
安徽省
4
稻谷
0.147
0.134
0.0801
-0.0035
0.302
安徽省
5
稻谷
0.0543
0.161
0.142
-0.0035
0.098
安徽省
6
稻谷
0.633
0.178
0.124
-0.0035
0.101
安徽省
7
稻谷
0.0988
0.181
0.221
-0.0035
0.074
安徽省
8
稻谷
0.403
-0.0035
0.0794
-0.0035
0.119
安徽省
9
稻谷
0.125
-0.0035
0.0804
0.0088
0.133
安徽省
10
稻谷
0.0725
0.0229
0.162
-0.0035
0.175
(3)数据透视
用R程序对各地区污染物含量求平均值,R语言程序如下:
Hg_me<-tapply(rice1$镉,rice1$监测单位地区,mean)
得到的数据形式如表2-5所示:
表25全国各省大米污染物监测数据
样品产地
镉
铅
总铬
总汞
总砷
安徽省
0.143057
0.079339
0.101273
-0.00152
0.143006
福建省
0.00692
0.11245
0.021685
0.001074
0.146383
广东省
0.084317
0.030403
0.105818
0.00046
0.356286
广西壮族自治区
0.177275
0.096204
0.134187
-0.00027
0.202
贵州省
0.008157
0.145956
0.460167
-0.00095
0.132306
海南省
0.066926
-0.0035
0.057267
0.013145
0.080919
河南省
0.037835
0.024985
0.237595
0.00653
0.135325
黑龙江省
0.001642
0.042398
0.314391
-0.00177
0.086133
湖北省
0.082057
0.041776
0.360381
-0.00241
0.117566
(4)数据连接
将食品污染物连接到地理数据上,打开ArcGIS软件,新建一张空白地图,在新建地图上拖入全国各省的地理数据,如图27所示。
图27拖入全国各省地图
左击省所在的图层【打开属性表】,可以看到地理数据,如图25所示
此时地理数据并未有和任何食品污染物数据连接。
左击省所在的图层【连接或关联】→【连接】,打开连接数据设置框,如图28所示:
图28全国地理数据连接数据
在连接数据框中,选择NAME作为连接字段,打开数据,选监测单位地区作为连接字段。
如图29所示:
图29全国地理数据连接数据
连接目标选择完毕后,【验证连接】,连接无误,【确定】,此时再次打开【打开属性表】,发现每一个地区都已经连接上了食品污染物数据,如图210所示。
在此基础上可进行进一步的分析。
图210地理数据连接食品污染物数据
1.3地图编辑
地图编辑(MapEditing)指的是制定地图成图技术方案并负责指导地图设计、编辑与生产全过程的工作。
在实际的工作当中,往往需要根据原始的矢量地图编辑符合业务需求的矢量地图。
常见的需求:
一是从原始地图中剪切所需的部分,例如从全国矢量地图截取某个省;二是分割或合并地图中的地理单元,这个需求常是由于碰到行政区划的变动,例如某市多出一个开发区,而这个开发区又是从之前不同的区县分割一部分合并而成,这时,就可以运用ArcGis的地图分割与合并工作。
由于地图编辑的范围很广,在此我们仅介绍最符合业务需求的一些方法,均是在已有原始矢量地图的基础上进行的地图编辑。
【案例2-2】
利用ArcMap,从全国矢量地图(quxian.shp)中剪切出山西省。
案例分析导图
图211地图剪切思维导图
步骤1:
按属性选择要素(图212)
将quxian.shp(C:
\Example\Data\Geodata)拖进地图显示窗口。
右击内容列表图层中的quxian,点击【打开属性表】,可以看到quxian属性表(图212a)的内容和dbf文件的内容是一致的,点击【按属性选择】按钮
,弹出按属性选择对话框(图212b)。
因为山西省各区县行政区域代码开头是44,故输入【"CNTY_CODE">140000AND"CNTY_CODE"<150000】(图212c),【验证】成功后【应用】,结果就能在全国矢量地图看见山西省被选中(图212d)。
a
b
c
图212按属性选择要素
步骤2:
导出山西矢量地图(图213)
右击内容列表图层中的quxian,点击【数据】-【导出数据】,导出刚才剪切下来的地图,保存的格式为ShapeFile,命名为Guangdong.shp(路径可设为C:
\Example\Train\2.2MapCutting)。
在导出文件的目录下或有shp、dbf、prj、sbn、sbx、shx这六种格式的地图文件。
其中最重要的是shp和dbf文件,shp包含各地理单元的边界和位置关系;dbf文件包含各地理单元的基本地理信息,以数据表形式存储,可用Excel打开。
a
b
c
d
图213导出山西矢量地图
步骤3:
查看山西矢量地图(
a
b
图214)
经过以上操作步骤,Guangdong.shp已出现在内容列表。
为了显示出山西矢量地图,先将图层quxian的勾去掉,再右击图层Guangdong,选择【缩放至图层】,山西矢量地图就会铺满画布。
此时,可参考3.1专题地图的内容,制作山西省专题地图(图215)。
a
b
图214查看山西省矢量地图
图215山西省各区县矢量地图
【案例2-3】
本案例将模拟分别从A县和B县各分割出一部分地区,并将该两部分合并成一个新县C。
数据是C:
\Example\Data\2.2MapClippingAndMerging中的ABcounty.shp,将其拖入地图编辑窗口,A、B县的情况如图216所示。
图216A、B县矢量地图
案例分析导图
图217地图分割与合并的案例分析思维导图
步骤1:
备份AB县矢量地图(图218)
在分割前需要注意一点的是,直接在原始矢量地图上操作会使地图的属性表直接被更改,因此如果仍需原始矢量地图,可复制原始矢量地图至另一文件夹操作,本案例就将Data文件夹下的ABcounty复制到Train文件夹对应的路径下,因最终要生成C县,故重新命名为ABCcounty。
a
b
图218备份AB县矢量地图
步骤2:
依次分割A、B县(图219)
选中点击工具栏的【编辑器】-【开始编辑】,使图层ABcounty处于编辑状态。
点击选中A县,点击编辑工具栏里的【裁剪面工具】(图标为
),将鼠标点放至A县的边界开始点击(可通过拨动鼠标滚轮放大地图,这样可以更加精确地点击在边界上)并逐步往A县内部点击,至到A县的另一头双击边界结束,即可将A县切割,分出一块新的区域。
同样用此法分割B县,点击【编辑器】-【保存编辑】,保存编辑内容,结果如图220。
a
b
c
d
图219分割A县
图220AB县分别被分割后的结果展示
步骤3:
合并两地区为新县(图221)
在编辑状态下,同时选中,点击【编辑器】-【合并】,若要先保留A县信息,选择A县后,点击【确定】,分割出的A、B县即合并为新的A县。
a
b
图221合并AB县
步骤4:
修改更新属性表
在编辑状态下,右击图层中的ABCcounty.shp,点击【打开属性表】,直接编辑数据,例如更新合并后的县名称为C县;经纬度、周长和面积需要重新计算。
更新经纬度、周长和面积的方法:
右击x字段,点击【计算几何】,弹出对话框(图222),属性选择【质心的X坐标】,单位选择【十进制度】,点击确定,新的X坐标就生成;Y坐标也按此方法,只需将对话窗口的属性选为【质心的X坐标】;计算周长时,属性则选择【周长】,单位可选【千米】;计算面积时,属性则选择【面积】,单位可选【平方千米】。
a
b
图222计算几何
最终,更新后的属性表和地图结果如图223所示。
a
b
图223编辑更新后的属性表及矢量地图展示
 升级会员
升级会员 