spss因子分析案例.docx
《spss因子分析案例.docx》由会员分享,可在线阅读,更多相关《spss因子分析案例.docx(14页珍藏版)》请在冰豆网上搜索。
spss因子分析案例
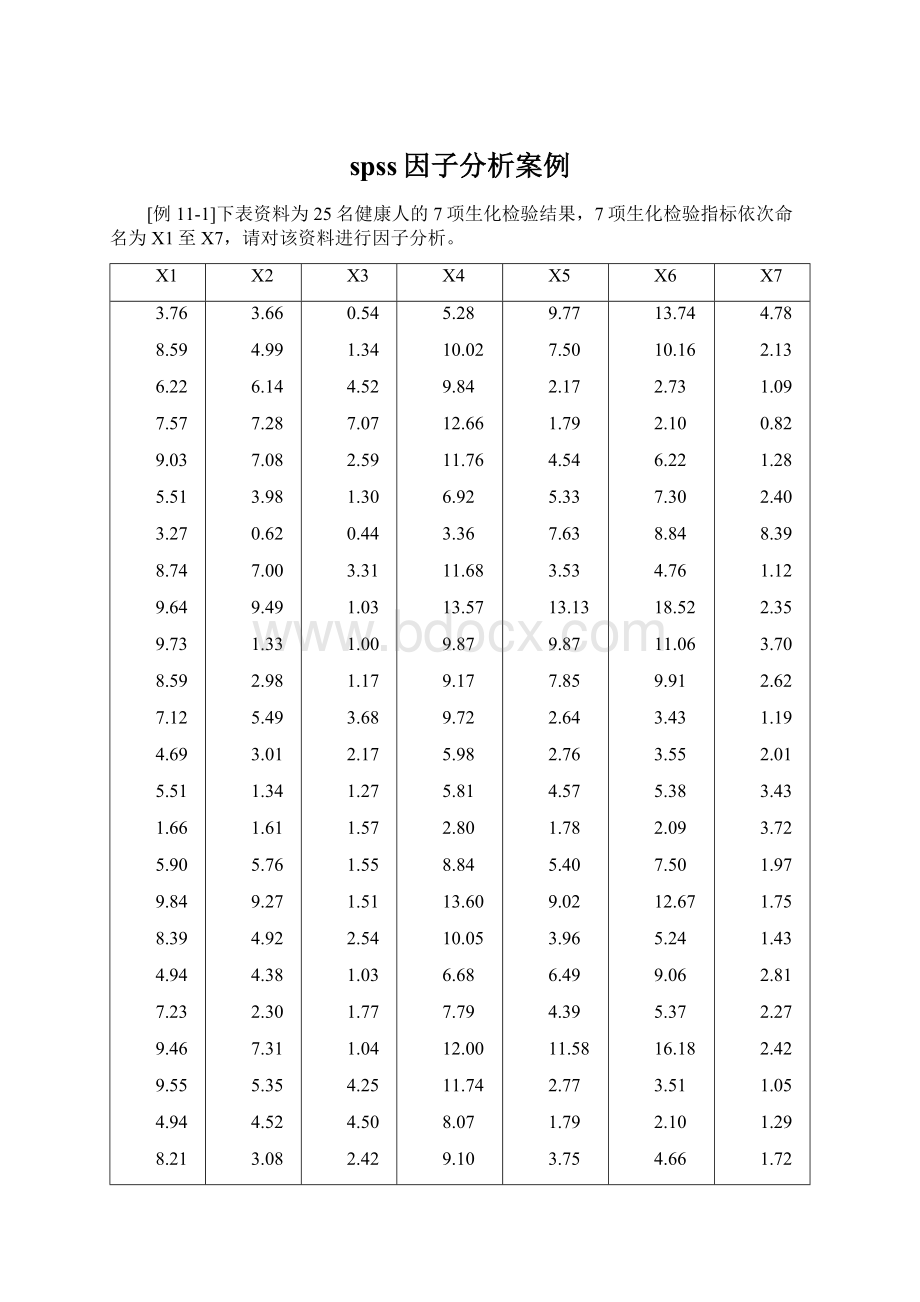
[例11-1]下表资料为25名健康人的7项生化检验结果,7项生化检验指标依次命名为X1至X7,请对该资料进行因子分析。
X1
X2
X3
X4
X5
X6
X7
3.76
8.59
6.22
7.57
9.03
5.51
3.27
8.74
9.64
9.73
8.59
7.12
4.69
5.51
1.66
5.90
9.84
8.39
4.94
7.23
9.46
9.55
4.94
8.21
9.41
3.66
4.99
6.14
7.28
7.08
3.98
0.62
7.00
9.49
1.33
2.98
5.49
3.01
1.34
1.61
5.76
9.27
4.92
4.38
2.30
7.31
5.35
4.52
3.08
6.44
0.54
1.34
4.52
7.07
2.59
1.30
0.44
3.31
1.03
1.00
1.17
3.68
2.17
1.27
1.57
1.55
1.51
2.54
1.03
1.77
1.04
4.25
4.50
2.42
5.11
5.28
10.02
9.84
12.66
11.76
6.92
3.36
11.68
13.57
9.87
9.17
9.72
5.98
5.81
2.80
8.84
13.60
10.05
6.68
7.79
12.00
11.74
8.07
9.10
12.50
9.77
7.50
2.17
1.79
4.54
5.33
7.63
3.53
13.13
9.87
7.85
2.64
2.76
4.57
1.78
5.40
9.02
3.96
6.49
4.39
11.58
2.77
1.79
3.75
2.45
13.74
10.16
2.73
2.10
6.22
7.30
8.84
4.76
18.52
11.06
9.91
3.43
3.55
5.38
2.09
7.50
12.67
5.24
9.06
5.37
16.18
3.51
2.10
4.66
3.10
4.78
2.13
1.09
0.82
1.28
2.40
8.39
1.12
2.35
3.70
2.62
1.19
2.01
3.43
3.72
1.97
1.75
1.43
2.81
2.27
2.42
1.05
1.29
1.72
0.91
11.2.1 数据准备
激活数据管理窗口,定义变量名:
分别为X1、X2、X3、X4、X5、X6、X7,按顺序输入相应数值,建立数据库,结果见图11.1。
图11.1 原始数据的输入
11.2.2 统计分析
激活Statistics菜单选DataReduction的Factor...命令项,弹出FactorAnalysis对话框(图11.2)。
在对话框左侧的变量列表中选变量X1至X7,点击Ø钮使之进入Variables框。
图11.2 因子分析对话框
点击Descriptives...钮,弹出FactorAnalysis:
Descriptives对话框(图11.3),在Statistics中选Univariatedescriptives项要求输出各变量的均数与标准差,在CorrelationMatrix栏内选Coefficients项要求计算相关系数矩阵,并选KMOandBartlett’stestofsphericity项,要求对相关系数矩阵进行统计学检验。
点击Continue钮返回FactorAnalysis对话框。
图11.3 描述性指标选择对话框
点击Extraction...钮,弹出FactorAnalysis:
Extraction对话框(图11.4),系统提供如下因子提取方法:
图11.4 因子提取方法选择对话框
Principalcomponents:
主成分分析法;
Unweightedleastsquares:
未加权最小平方法;
Generalizedleastsquares:
综合最小平方法;
Maximumlikelihood:
极大似然估计法;
Principalaxisfactoring:
主轴因子法;
Alphafactoring:
α因子法;
Imagefactoring:
多元回归法。
本例选用Principalcomponents方法,之后点击Continue钮返回FactorAnalysis对话框。
点击Rotation...钮,弹出FactorAnalysis:
Rotation对话框(图11.5),系统有5种因子旋转方法可选:
图11.5 因子旋转方法选择对话框
None:
不作因子旋转;
Varimax:
正交旋转;
Equamax:
全体旋转,对变量和因子均作旋转;
Quartimax:
四分旋转,对变量作旋转;
DirectOblimin:
斜交旋转。
旋转的目的是为了获得简单结构,以帮助我们解释因子。
本例选正交旋转法,之后点击Continue钮返回FactorAnalysis对话框。
点击Scores...钮,弹出弹出FactorAnalysis:
Scores对话框(图11.6),系统提供3种估计因子得分系数的方法,本例选Regression(回归因子得分),之后点击Continue钮返回FactorAnalysis对话框,再点击OK钮即完成分析。
图11.6 估计因子分方法对话框
11.2.3 结果解释
在输出结果窗口中将看到如下统计数据:
系统首先输出各变量的均数(Mean)与标准差(StdDev),并显示共有25例观察单位进入分析;接着输出相关系数矩阵(CorrelationMatrix),经Bartlett检验表明:
Bartlett值=326.28484,P<0.0001,即相关矩阵不是一个单位矩阵,故考虑进行因子分析。
KMO和Bartlett的检验
取样足够度的Kaiser-Meyer-Olkin度量。
.674
Bartlett的球形度检验近似卡方704.019
df28
Sig..000
解释的总方差
成份初始特征值提取平方和载入
合计方差的%累积%合计方差的%
14.64758.08758.0874.64758.087
21.64120.51878.6041.64120.518
3.6357.93586.540
4.6177.71694.256
5.3234.03798.292
6.1051.31099.602
7.031.39299.994
8.000.006100.000
提取方法:
主成份分析。
旋转成份矩阵a
成份
12
X1.580.643
X2-.020-.826
X3.854.057
X4.974.156
X5.948.062
X6.675.275
X7.091.894
X8.952.069
提取方法:
主成分分析法。
旋转法:
具有Kaiser标准化的正交旋转法。
a.旋转在3次迭代后收敛。
成份得分系数矩阵
成份
12
X1.070.287
X2.101-.461
X3.217-.078
X4.236-.038
X5.241-.087
X6.142.068
X7-.091.490
X8.241-.084
提取方法:
主成分分析法。
旋转法:
具有Kaiser标准化的正交旋转法。
构成得分。
KMO和Bartlett的检验是为了检验是否适合做因子分析,一般来说KMO的值越接近于1越好,大于0.5的话适合做因子分析,你的KMO值是0.674大于0.5。
Bartlett的检验主要看Sig.越小越好,你的接近于0.由此可以得出,你的数据适合做因子分析。
第二个表是提取了两个个公因子来替代原来的8个原始变量,这两个因子的方差贡献率是78.604%,也就是说这两个公因子能够解释原来8个原始变量所包含信息的78.604%。
第三个表是旋转因子载荷,是为了方便对提取的两个公因子命名,旋转后,第一个因子在X1上的载荷最大,第二个因子在X2与X7上载荷最大,你可以根据X1,X2,X7的含义来对这两个因子命名。
第四个表是为了计算因子得分。
比如第一个因子F1=X1*0.7+X2*0.101+X3*0.217+X4*0.236.....+X8*0.241,xi到X8这8个原始变量的值的大小你是知道的,带进去就可以求出这两个因子的分数。
纯手打,希望能帮助到您,呵呵!
Kaiser-Meyer-OlkinMeasureofSamplingAdequacy是用于比较观测相关系数值与偏相关系数值的一个指标,其值愈逼近1,表明对这些变量进行因子分析的效果愈好。
今KMO值=0.32122,偏小,意味着因子分析的结果可能不能接受。
Analysisnumber1 Listwisedeletionofcaseswithmissingvalues
Mean StdDev Label
X1 7.10000 2.32380
X2 4.77320 2.41779
X3 2.34880 1.66556
X4 9.15240 3.01405
X5 5.45840 3.27344
X6 7.16720 4.55817
X7 2.34600 1.61091
NumberofCases = 25
CorrelationMatrix:
X1 X2 X3 X4 X5 X6 X7
X1 1.00000
X2 .58026 1.00000
X3 .20113 .36379 1.00000
X4 .90900 .83725 .43611 1.00000
X5 .28347 .16590 -.70423 .16328 1.00000
X6 .28656 .26119 -.68058 .20309 .99020 1.00000
X7 -.53321 -.60846 -.64918 -.67758 .42733 .35732 1.00000
Kaiser-Meyer-OlkinMeasureofSamplingAdequacy= .32122
BartlettTestofSphericity=326.28484,Significance= .00000
使用主成分分析法得到2个因子,因子矩阵(FactorMatrix)如下,变量与某一因子的联系系数绝对值越大,则该因子与变量关系越近。
如本例变量X7与第一因子的值为-0.88644,与第二因子的值为0.21921,可见其与第一因子更近,与第二因子更远。
或者因子矩阵也可以作为因子贡献大小的度量,其绝对值越大,贡献也越大。
在FinalStatistics一栏中显示各因子解释掉方差的比例,也称变量的共同度(Communality)。
共同度从0到1,0为因子不解释任何方差,1为所有方差均被因子解释掉。
一个因子越大地解释掉变量的方差,说明因子包含原有变量信息的量越多。
Extraction 1foranalysis 1,PrincipalComponentsAnalysis(PC)
PC extracted 2factors.
FactorMatrix:
Factor 1 Factor 2
X1 .74646 .48929
X2 .79644 .37219
X3 .70890 -.59727
X4 .91054 .38865
X5 -.23424 .96350
X6 -.17715 .97172
X7 -.88644 .21921
FinalStatistics:
Variable Communality * Factor Eigenvalue PctofVar CumPct
*
X1 .79660 * 1 3.39518 48.5 48.5
X2 .77284 * 2 2.80632 40.1 88.6
X3 .85927 *
X4 .98014 *
X5 .98320 *
X6 .97561 *
X7 .83384 *
下面显示经正交旋转后的因子负荷矩阵(RotatedFactorMatrix)和因子转换矩阵(FactorTransformationMatrix)。
旋转的目的是使复杂的矩阵变得简洁,即第一因子替代了X1、X2、X4、X7的作用,第二因子替代了X3、X5、X6的作用。
VARIMAX rotation 1forextraction 1inanalysis 1-KaiserNormalization.
VARIMAXconvergedin3iterations.
RotatedFactorMatrix:
Factor 1 Factor 2
X1 .87795 .16064
X2 .87848 .03332
X3 .42098 -.82586
X4 .99001 .00414
X5 .15872 .97878
X6 .21452 .96415
X7 -.73151 .54656
FactorTransformationMatrix:
Factor 1 Factor 2
Factor 1 .92135 -.38873
Factor 2 .38873 .92135
最后将第一因子的因子分用变量名fac_1、第二因子的因子分用变量名fac_2存入原始数据库中。
这些值既可用于模型诊断,又可用于进一步分析。
基于因子分析法的西部地区服务业竞争力评价
【摘要】:
加快服务业的发展,提高服务业在国民经济中的地位,是我国政府近十年来经济政策的重要导向之一。
随着西部大开发的推进,西部地区服务业的发展状况得到广泛关注。
该研究基于服务业和服务业竞争力的理论,运用因子分析方法,对西部十二省区的服务业竞争力进行分析评价,并根据因子分析的结果和西部十二省区服务业发展的优劣势,提出提升该地区服务业竞争力水平的对策与建议。
关键词:
服务业;竞争力;因子分析中图分类号:
N949
Abstract
Duringthelasttenyears,speedingupthedevelopmentofserviceindustryandenhancingitspositionin
nationaleconomyisoneofthemostimportantdirectionsoftheeconomicpolicyofourgovernment.AlongwiththeprogressofDevelopmentoftheWestRegions,allcirclesconcernedstartspayingattentiontothedevelopmentofserviceindustryoverthere.Basedonthetheoriesofserviceindustryanditscompetitiveness,thisresearchmakesuseoffactoranalysistoevaluatethecompetitivenessofserviceindustryintwelvewesternprovincesandregions,andthenbringsforwardcountermeasuresandsuggestionstoupgradetheircompetitiveness,whichisonthebaseoftheresultsoffactoranalysisand
theadvantagesanddisadvantagesofthedevelopmentofserviceindustryinthewestregions.
Keywords:
ServiceIndustry;Competitiveness;FactorAnalysis
1.引言
服务业的发展状况与竞争力水平,不仅可以衡量一个国家和地区经济发展水平,而且能够反映一个国家和地区经济发展所处的阶段。
随着我国西部大开发战略的实施,西部十二省区服务业得到了快速发展,在促进地区经济增长、增加就业、提高人民生活水平、保持社会稳定等方面发挥了重要作用。
然而,与发达国家和东部省区相比,仍然存在许多问题,如总体发展水平偏低,现代服务业尚未形成规模,服务业国际化水平较低等。
正确、客观评价研究西部十二省区服务业的竞争力水平,对促进西部地区经济发展和推进西部大开发具有深远意义。
服务业竞争力是一个涵盖服务业本身以及相关要素关系和行为多个方面的综合系统。
一个地区的服务业竞争力是该地区服务业综合能力的体现,是其在一定的政治、经济、科技、文化、人才等环境和条件下,相对于其他地区所表现出来的生存能力和可持续发展能力的综合[1]。
因子分析法是在主成分分析法的基础上发展起来的一种综合评价方法,不仅可以给出排名,还可以进一步探索影响排名次序的因素,从而找到改善和提高西部十二省区服务业竞争力的方向和途径。
2.地区服务业竞争力评价指标体系的构建
目前我国关于服务业竞争力评价研究还处于起步阶段,对评价指标体系的研究很有限,而其中比较权威的是中国人民大学竞争力与评价研究中心建立的包括规模竞争力、结构竞争力、成长竞争力、创新竞争力、管理竞争力5个一级指标的服务业竞争力评价体系[2]和吴士元在《我国省级服务业竞争力的综合评价》一文中从经济实力、服务业总体情况、主要服务业行业发展和科技实力四个方面构建的服务业竞争力综合评价指标体系[3]。
影响地区服务业竞争力的因素很多,主要有人均GDP、城市化水平、人口规模、人口密度、居民的消费支出、固定资产投资、外部政策和经济环境等。
服务业竞争力是一个复杂系统,要从多维多角度对地区服务业竞争力进行综合评价。
根据前人对服务业竞争力评价的实证研究,参考地区服务业竞争力的影响因素,将从四个方面进行分析:
一是经济基础;二是服务业总体情况;三是主要服务行业发展状况;四是科技实力,具体指标见表1。
3.因子分析法分析评价西部十二省区服务业竞争力
在众多评价方法中,因子分析法可以较大限度地克服指标之间的相关性对评价结果的影响。
根据《中国统计年鉴(2006)》[4]得到以上各指标的相应数据,运用SPSS15.0统计分析软件中的因子分析法[5],采用主成分分析法提取公因子,计算出相关系数阵的特征值、贡献率、累计贡献率,因子载荷矩阵等,最终求得综合评价值,并据此进行排序。
第一步,利用SPSS15.0对原始数据(见附录1)进行计算,得出相关系数矩阵,可知
10个财务指标之间存在较强的相关关系,可以进行因子分析。
第二步,按照特征根大于1的原则选取公共因子。
在SPSS15.0的运行中,选择以主成分法作为因子提取方法,选定因子提取标准是:
特征值≥1。
由表2可知,有三个满足条件的特征值,它们对样本方差的累计贡献率达到了
81.687%,代表了绝大部分信息,因此提取三个因子便能够对所分析的问题进行很好的解释。
第三步,采用主成分分析法计算因子载荷矩阵。
同样利用SPSS15.0求得初始因子载荷矩阵,从表3可以看出,各公共因子的典型代表变量不是很突出,各指标前几个公共因子上均有相当程度的载荷值,难以合理解释其实际意
义,所以要进一步进行旋转。
选择方差最大化方法进行因子旋转,得到旋转后的因子载荷矩阵如表4。
转贴于中国论文下载中心http:
//www.studa.根据旋转后的因子载荷矩阵表4,可将指标集分为三个主因子,第一主因子在人均GDP、
服务业从业人员比率、人均批发零售及住宿餐饮、人均交通运输仓储及邮电、人均金融保险及房产上具有很大载荷,从各指标的经济含义可知反映了地区服务业发展的经济基础,将其定义为服务业发
展动力因子;第二主因子在服务业全社会固定资产投资额、服务业从业人员年工资总额、服务业城镇专业技术人员数上有较大载荷,从各指标的经济含义可知反映了服务业在资本、人力等方面的投入
,将其定义为服务业发展投入因子;第三主因子在人均城镇居民消费性支出、服务业增加值占GDP比重上载荷较大,从各指标的经济含义可知是反映服务业竞争力提高的潜力指标,将其定义为服务业展潜力因子。
第四步,构建服务业竞争力综合评价模型,算出因子得分并排序。
利用SPSS15.0得出的因子得分系数矩阵,一个地区相对于第一主因子的得分如下计算:
F1=0.303﹡X1
 升级会员
升级会员 