如何找一个基因的启动子序列呢.docx
《如何找一个基因的启动子序列呢.docx》由会员分享,可在线阅读,更多相关《如何找一个基因的启动子序列呢.docx(24页珍藏版)》请在冰豆网上搜索。
如何找一个基因的启动子序列呢
1、UCSC
(1)网址:
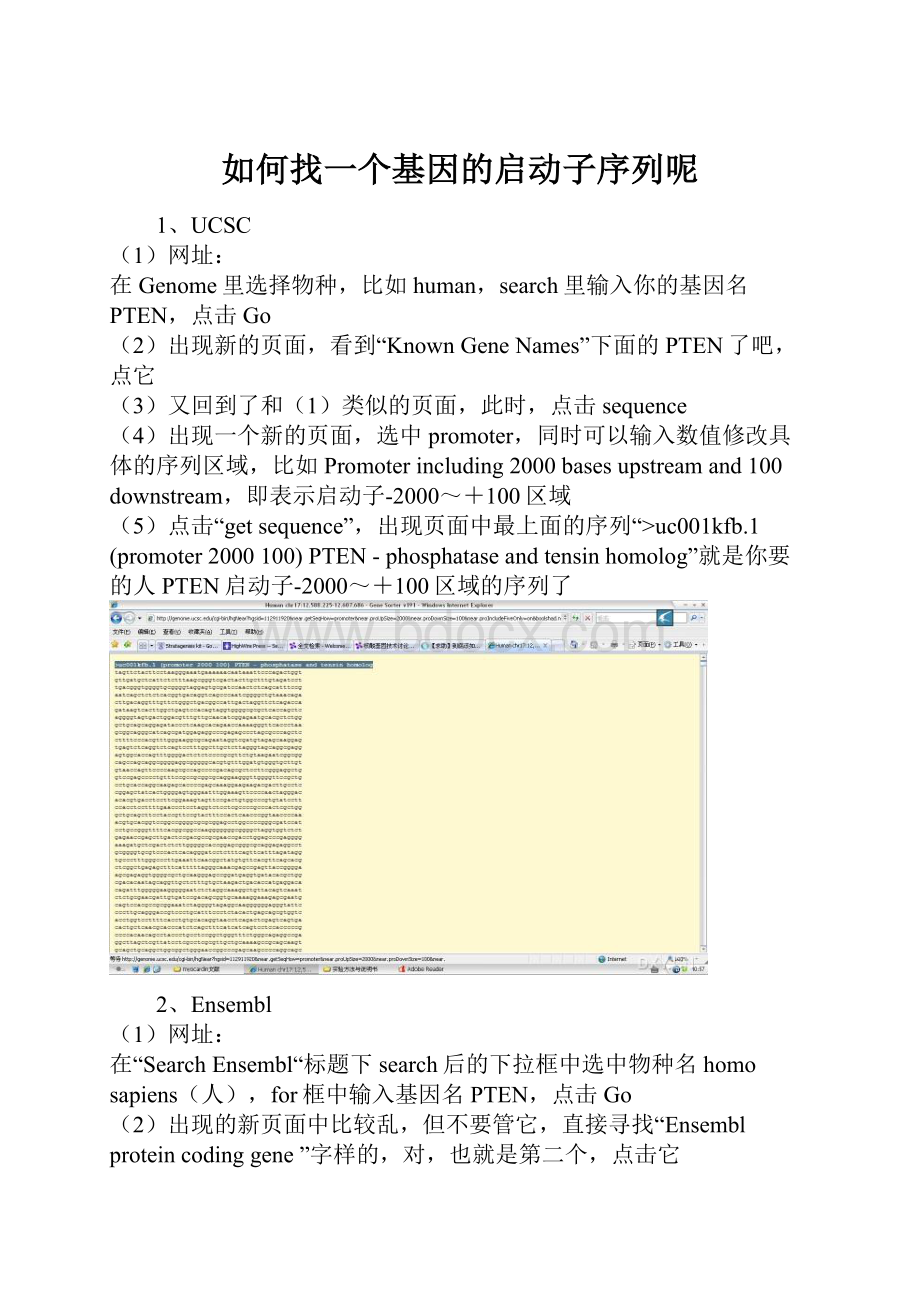
在Genome里选择物种,比如human,search里输入你的基因名PTEN,点击Go
(2)出现新的页面,看到“KnownGeneNames”下面的PTEN了吧,点它
(3)又回到了和
(1)类似的页面,此时,点击sequence
(4)出现一个新的页面,选中promoter,同时可以输入数值修改具体的序列区域,比如Promoterincluding2000basesupstreamand100downstream,即表示启动子-2000~+100区域
(5)点击“getsequence”,出现页面中最上面的序列“>uc001kfb.1(promoter2000100)PTEN-phosphataseandtensinhomolog”就是你要的人PTEN启动子-2000~+100区域的序列了
2、Ensembl
(1)网址:
在“SearchEnsembl“标题下search后的下拉框中选中物种名homosapiens(人),for框中输入基因名PTEN,点击Go
(2)出现的新页面中比较乱,但不要管它,直接寻找“Ensemblproteincodinggene”字样的,对,也就是第二个,点击它
(3)新出现的页面也很乱,不过依然不用管它,看到左侧有点肉色(实在不知道怎么描述了)的那些选项了吗,对,就是“YourEnsembl”下面那一堆,在里面找“Genomicsequence”,点它
(4)现在的界面就一目了然了,在“5'Flankingsequence”中输入数值确定启动子长度(默认为600),比如1000,点击update;
(5)出现的序列中,标为红色的就是基因的外显子,红色之间黑色的序列就是内含子,而第一个红色自然就是第一外显子了,那么从开始的碱基一直到第一个红色的碱基间自然就是启动子-1000~+1的序列啦
这样,你不仅查到了启动子,连它的外显子、内含子序列也全部搞定了
3、SIB-EPD
(1)网址:
(2)具体使用方法大同小异,就是输入物种名、基因名,限定启动子序列区域
不过有了前两个,我想已经足够用了,个人感觉SIB-EPD的库容量太小,很多基因查不到
我以前回的贴,总结一下
ensembl一般也和NCBI的一致,你的情况可能例外。
这就不清楚了。
ensembl有七个外显子可能有它自己的理由。
另外,NCBI的基因中gene库中同时有ensembl和genbank的链接,不如从这个链接看看。
此外,还可以看一看这个基因在物种间的同源性,以及其它物种有几个外显子,做为参考。
综合考虑一下。
给你提供几个启动子区域查找的网站,慢慢摸索会学到更多的。
果蝇的
PROMOTER2.0
通常确定启动子的算法可以分成两种,一种根据启动子区各种转录信号,如TATA盒、CCAAT盒,结合对这些保守信号及信号间保守的空间排列顺序的识别进行预测。
如PROMOTER2.0,用神经网络方法确定TATA盒、CCAAT盒、加帽位点(capsite)和GC盒(GCbox)的位置和距离,识别含TATA盒的启动子。
PROMOTERSCAN
根据转录因子结合部位在基因组中分布的不平衡性,将转录因子结合部位分布密度及TATA盒的权重矩阵(weightmatrix)结合起来,从基因组DNA中识别出启动子区[3]。
但上述程序预测的假阳性率较高,PROMOTER210每23kb出现一个假阳性;PRO2MOTERSCAN平均每19kb出现一个假阳性。
PromoterInspector
另一种方法根据启动子区序列的特征进行预测。
Promo2terInspector从一组训练序列中提取出启动子区的环境特征,并将外显子、内含子和3’端非翻译区的特征及启动子区加以区分,从而在基因组中确定启动子位置
初来乍到,发个技术贴了!
!
1、获取目的基因的mRNA序列,并且在NCBI的数据库中查获转录起始点
2、截取转录起始点为中心,上下约各1000bp,若在此范围内出现CDS,可到翻译起始点终止
3、利用在线软件进行分析
PromoterInspector
PromoterScan
Promoter2.0
NNPP
EMBOSSCpgplot
CpGIslandsPrediction
本人是采取多种软件结合的方法,由于proscan和promoter2.0的假阳性率较高,仅作为参考,而promoterinspector的特异性较高,结果比较可信。
同时,利用CpG岛预测,作为辅助参考
4、最后,可以找到小鼠的同源区,进行同源性比较,启动子区域一定是高保守区
5、到此,可以初步预测启动子区域的范围了。
请高手多多指教!
!
启动子预测:
转录因子预测:
此处亦有好多,自己挑吧!
以下内容转自
启动子及转录因子结合位点数据库及预测工具
PROMOTERFINDINGANDANALYSISPROGRAMSONTHEINTERNET
--------------------------------------------------------------------------------
TRANSPLORER(TRANScriptionexPLORER)
Dnanalyze(TFmapping)
DragonPromoterFinder1.2(TSSfinderandpromoterregionanalysis)
FunSiteP2.1
HCtata(TATAsignalprediction)
McPromoterVer.3
MatInspector(SearchforTFbindingsites)
ModelGeneratorandModelInspector
NNPP2.1(TSSfinder)
PromoterInspector(Strandnon-specificpromoterregionfinder)
Promoter2.0(TSSfinder)
PromoterScanII(Promoterregionprediction)
RGSiteScan
SignalScan(SearchforEukaryoticTranscriptionalElements)
TESS(SearchforTranscriptionElements)
TFSEARCH(PredictsTFbindingsitesbasedonTRANSFACdata)
TRANSFAC(TFdatabaseandanumberofassociatedprograms)
TSSGandTSSW
PROMOTER2.0
通常确定启动子的算法可以分成两种,一种根据启动子区各种转录信号,如TATA盒、CCAAT盒,结合对这些保守信号及信号间保守的空间排列顺序的识别进行预测。
如PROMOTER2.0,用神经网络方法确定TATA盒、CCAAT盒、加帽位点(capsite)和GC盒(GCbox)的位置和距离,识别含TATA盒的启动子。
PROMOTERSCAN
根据转录因子结合部位在基因组中分布的不平衡性,将转录因子结合部位分布密度及TATA盒的权重矩阵(weightmatrix)结合起来,从基因组DNA中识别出启动子区[3]。
但上述程序预测的假阳性率较高,PROMOTER210每23kb出现一个假阳性;PRO2MOTERSCAN平均每19kb出现一个假阳性。
PromoterInspector
另一种方法根据启动子区序列的特征进行预测。
Promo2terInspector从一组训练序列中提取出启动子区的环境特征,并将外显子、内含子和3’端非翻译区的特征及启动子区加以区分,从而在基因组中确定启动子位置
FirstEF
近来还有一些程序将上述方法及CpG岛(CpGislands)信息相结合。
CpG岛是一段200bp或更长的DNA序列,核苷酸G+C的含量较高,并且CpG双核苷酸的出现频率占G+C含量的50%以上。
许多脊椎动物的启动子区都及CpG岛的位置重合。
FirstEF(http:
//rulai1cshl1org/tools/FirstEF/)搜索通过5’UTR定位技术构建的第一外显子数据库,识别第一剪切点(firstsplicingdonorsite),结合CpG岛信息,确定启动子区。
这种方法使预测的敏感性和特异性都明显提高。
该程序预测含CpG岛的启动子的敏感性和特异性都高于90%,预测不含CpG岛的启动子的精确性相对略低。
TRRD数据库收录了真核基因调控区结构和基因表达方式的信息,每个条目对应一个基因。
应用权重矩阵数据库搜索转录因子结合部位的程序包括
SIGNALSCAN
MatInspector
转录因子搜索程序(transcriptionalfactorsearch,
TF2SEARCH)
等等。
尽管基于PWM的搜索比较敏感,但它最大的缺点就是假阳性率过高,在预测的结果中有很多结合部位并不真正具有生物学功能。
COMPEL数据库
经实验确定的复合元件不多,COMPEL数据库中收录了近200条经实验确定的复合元件的信息。
如果转录因子结合部位的预测结果中包含复合元件,显然比单个元件更有可能具有生物学功能。
Co-Bind程序通过建立两个转录因子结合部位的PWM及其复合作用的模型,可以预测序列中的复合元件。
还有一些程序利用COMPEL数据库中已知的复合元件去搜索基因组序列。
Consensus
AlignACE
等是用来搜索高含量基序(overrepresentedmotiffinding)的一些算法,可以对一组基因簇中的基因调控区进行比较,以发现其中存在的高含量的基序,调控元件可能就存在于这些基序之中。
在UCSC查找可能的启动子
1、进入网站。
2、点击Tables菜单,在position后面的搜索框内写入待查的基因名称,点击getoutput。
3、出现一系列候选序列。
当搜索用词不特异的时候会出来太多的结果,只显示500条。
4、点击自己目的基因的结果链接,会出现该基因在染色体上的位置(有时候会直接跳到选择genome,protein,mRNA那一页面,可能是在搜索词比较特异的情况写),继续getoutput。
5、选择genome这一项。
6、promoter/upstream前面的框中打勾,一般的启动子长度大约为2kb左右,这个数字可以修改。
为便于观察,可继续修改下面的几个选项。
这里选择CDS大写。
7、点击getsequence即可得到结果。
UTR和upstream是分开的,CDS是大写的,可以看到起始码。
copyATG以前的序列进行启动子分析。
PCR以genome为模板。
在Ensembl查找可能的启动子
1、进入网站,选择物种,填入搜索的基因名称。
2、出来2个结果。
本例中貌似是同一个。
点击相应链接进入新页面。
3、貌似有2个不同的转录本。
点击ExonInfo。
4、新页面中即可看到5'upstreamsequence。
可以在Flankingsequenceateitherendoftranscript后面的框中修改期望显示的序列长度。
一般启动子最好选>2kb。
然后copy所显示的上游序列进行分析。
随着基因工程的发展,常常需要构建一种能高水平表达异源蛋白质的表达载体。
启动子对外源基因的表达水平影响很大,是基因工程表达载体的重要元件。
因此研究启动子的克隆方法,对研究基因表达调控和构建表达载体至关重要。
迄今为止,国外尚未见到有关启动子克隆方法的综述性报道,国内仅孙晓红等曾就启动子的结构、分类、克隆方法和食用菌中已经分离到的启动子作过综述。
而近年来又有许多改进的克隆启动子的方法获得了多方面的成功,本文就近年来改进的启动子克隆方法作一综述,以期促进对启动子分离技术的应用。
1 启动子克隆的几种方法
1.1 利用启动子探针载体筛选启动子
启动子探针型载体是一种有效、经济、快速分离基因启动子的工具型载体,包含2个基本部分:
转化单元和检测单元。
其中,转化单元含复制起点和抗生素抗性基因,用于选择被转化的细胞;检测单元则包括1个已失去转录功能且易于检测的遗传标记基因以及克隆位点。
利用启动子探针载体筛选启动子的过程为,先选用1种适当的限制性核酸内切酶消化切割染色体DNA,然后将切割产生的DNA限制片段群体及无启动子的探针质粒载体重组,并按照设计的要求使克隆的片段恰好插在紧邻报告基因的上游位置;随后再把重组混合物转化给寄主细胞,构建质粒载体基因文库,并检测报告基因的表达活性。
当插入段同时满足
(1)具有基因启动子序列;
(2)具有翻译启始区;(3)具有启始MM子;(4)插入方向正确;(5)插入片段3'端编码区序列抗性基因编码区读码框一致,则有可能形成有功能的抗性融合基因,从而启动抗性基因的表达。
最早由Rachael等在大肠杆菌中以四环素抗性基因作为报告基因构建了启动子探针质粒pBRH3B,并克隆了一些原核和真核启动子片段。
其后Donna等以氯霉素抗性基因作为报告基因,Fodor等以大肠杆菌LacZ为报告基因,构建了酵母启动子探针质粒并克隆了一些启动子片段。
构建启动子探针型载体,较为常见的检测标记基因有β-半乳糖苷酶基因(lacZ)、氯霉素乙酰转移酶基因(cat)、四环素抗性基因(Tet')和卡那霉素抗性基因(Kan')。
近年来,人们渐渐较多地使用潮霉素B磷酸转移酶(hph)基因作为检测标记基因。
李维等曾构建了含有hph抗性基因的启动子探针型载体pSUPV8,直接在大肠杆菌中分离黄孢原毛平革菌基因的启动子。
先用Sau3AI酶切黄孢原毛平革菌基因总DNA,再及用BamHI酶切后的pSUPV8相连,转化大肠杆菌,用间接筛选法从氨苄青霉素和潮霉素抗性平板上筛选重组子,得到6个双抗重组子(pCH1~pCH6),电泳检测插入片段分别命名为CHl~CH6;再用原生质体转化法将重组子分别转化黄孢原毛平革菌,对获得的转化子进行复筛,仅pCH6的转化平板上有稳定生长的菌落,说明了CH6片段在黄孢原毛平革菌中具有启动基因表达的功能。
该方法不需要知道具体基因的序列,可随机筛选启动子,避免了引物设计,能获得大量的启动子片段。
1.2 利用PCR技术克隆启动子
即根据发表的基因序列,设计引物,克隆基因的启动子,由于PCR法简便快捷,近年来人们较多采用此方法克隆基因启动子。
苏宁等根据已报道的水稻叶绿体16SrRNA启动子基因序列设计5'启动子序列的引物,以水稻叶绿体DNA为模板,PCR扩增出16SrRNA基因5'启动子区的片段,酶切克隆到pSK的SacI和SphI位点,构建测序载体质粒pZ16S,进行序列测定,结果表明所克隆的片段长为144bp,含有SD序列。
同源比较结果表明,所克隆的片段及水稻叶绿体16SrRNA启动子序列具有100%的同源性。
上述的PCR方法简便、快捷、操作简单,是人们较为广泛使用的技术。
1.3 环状PCR
环状PCR包括I-PCR(Inverse-PCR)和P-PCR(Panhandle-PCR)。
这2种PCR都是根据一端已知序列设计的嵌套式引物进行PCR。
1.3.1 I-PCRI-PCR是1988年由Triglia最早提出的一种基于PCR的改进的染色体步行方法。
I-PCR的实验程序包括,基因组DNA经酶切后用T4DNA连接酶进行自连接,产生环状DNA片段;以环化产物为底物,用根据已知片段设计的反向引物进行PCR扩增,从而得到含有未知片段的扩增产物(流程如图1所示)。
韩志勇等以I-PCR技术为基础克隆了转基因水稻的外源基因旁侧序列。
先用小量法提取转基因水稻的总DNA,总DNA用10倍过量的限制内切酶进行过夜酶切,酶切片段进行自连接,然后根据工程质粒的T-DNA区设计2对反向引物,进行套式PCR扩增旁侧序列。
建立了适合于处理大量材料的克隆转基因水稻中外源基因旁侧序列的技术体系。
在1周内克隆了35个转基因水稻株系中外源基因的旁侧序列,长度在300~750bp之间。
I-PCR法快速、高效、稳定,操作相对简单,花费少,PCR引物设计比较方便。
1.3.2 P-PCRP-PCR是由Jones等提出的利用末端反向重复序列及已知序列互补配对形成环状单链模板,有效增强了引物及模板结合的特异性。
反应需要3个根据已知序列设计的引物,3个引物在已知序列内呈线性排列,其中第3个引物可作为接头使用,可及已知序列互补配对形成锅柄状单链模板。
其过程为,首先酶切基因组DNA,产生5'或3'粘末端,然后连接上合适的接头(primer3),连接好后最好用核酸外切酶I除去多余的接头,由于连接上的接头及已知序列是反向重复序列,变性后的DNA单链可退火形成锅柄状单链模板,之后分别用3个单引物进行3次PCR扩增,能有效地扩增2~9kbp的大片段未知序列(流程如图2所示)。
黄君健等成功地应用P-PCR技术从正常的人外周血单核细胞基因组DNA中扩增端粒催化亚基hTERT基因5'端上游旁侧序列,获得了hTERT基因翻译启始位点上游2090bp的基因组DNA序列。
首先用酶切消化基因组DNA,得到带有GATC的5'突出端的DNA片段。
然后利用已知的hTERTcDNA序列设计PCR引物,用常规的PCR方法扩增出1条大约900bp的基因组特异片段,序列分析为hTERT的基因组DNA片段。
根据得到的基因组DNA序列的信息,确定P-PCR的引物退火区,并合成了5'磷酸化的连接寡核苷酸和4条基因特异性引物,其中连接寡核苷酸5'端的4个碱基CTAG及上述核酸内切酶消化产生的5'突出端GATC互补,然后将连接寡核苷酸及基因组酶切产物连接,以连接产物为反应模板,进行PCR,使模板自身进行退火-延伸反应,以形成Panhandle结构。
最后以单链Panhandle为模板,4条基因特异序列为引物进行嵌套式PCR,最终获得了1条约2kb的含hTERT基因启动子的DNA片段。
Jones等利用改进的P-PCR,在形成panhandle结构之前3'末端连上ddCTP,使引物错配的机率减少,特异性增加。
他们从人类基因组DNA已知位点侧翼扩增了4~9kb的大片段未知序列。
P-PCR是目前能够扩增距已知序列最远的未知DNA序列的方法,有很高的特异性。
1.4 利用载体或接头的染色体步行技术克隆基因启动子
这类方法的第一步都是酶切基因组DNA,连接载体或接头,既可以用pUCl8等质粒载体,也可以使用λDNA等噬菌体载体,只要选用的载体带有合适的酶切位点;同样根据实验需要,接头既可以是双链也可以是单链,然后根据基因组DNA序列设计的特异引物和载体的通用引物或接头序列进行扩增。
1.4.1 利用载体的PCRShyamala等利用的单特异性引物PCR(SSP-PCR)对以小鼠伤寒杆菌组氨酸转运操纵子为起点进行连续步行。
以M13mpl8RFDNA为载体。
用PstI和AraI酶切基因组DNA,PstI和XmaI酶切载体DNA,然后连接基因组片段和载体片段,用根据基因组DNA序列设计的特异引物和载体的通用引物进行扩增,由于非特异片段没有单特异引物结合的位点,即使有载体连到非特异片段,也无法得到大量扩增,而使特异片段得到有效扩增。
1.4.2 利用接头的PCR王新国等利用衔接头的方法,设计了位于单链DNA两端互补的颠倒末端重复序列,增加了反应的特异性,在胡萝卜II型转化酶基因启动子的克隆方面取得了新的进展。
首先将胡萝卜基因组DNA分别用PvuI、SmaI、DraI、EcoRV酶切,并设计了1个衔接头长链序列和1个衔接头短链序列,并在衔接头短链的3'末端带有1个氨基的衔接头,能够阻止聚合酶催化的衔接头短链的延伸,同时衔接头的长链和短链之间是反向重复序列。
将酶切片段及此衔接头连接,取连接产物做模板,以衔接头引物和基因特异引物做PCR,在首轮PCR中只有限定的远端基因特异引物有结合位点,当基因特异引物延伸产生的DNA链通过衔接头时,才能产生衔接头引物的结合位点,PCR才能以衔接头引物和基因特异引物进行指数扩增。
而另一方面,如果非特异合成产生了DNA两端都有双链衔接头序列的PCR产物时,这种PCR产物在每次变性后,单链DNA末端的衔接头反向重复序列将形成锅柄结构,此结构比引物-模板杂交更稳定,能抑制非特异序列的指数增长。
最后得到主要的PCR产物为3.4kb、1.3kb、0.6kb和0.4kb。
将EcoRV-衔接头体系的PCR产物克隆、测序、同源性比较,得到1个新的胡萝卜II型转化酶基因启动子序列,它含有类似于TATAbox和CAATbox的元件,在启动子的远上游区域含多个AT富含区,该启动子的发现对于研究植物中的糖代谢具有重要的意义。
接头引物的相对位置如图3所示。
这种方法具有便于操作、实验线路简单的优点,但是特异性较差,产物需进一步杂交验证。
1.5 YADE法
Prashar等在扩增cDNA3'端时采用“Y”形接头,以减少接头引物的单引物扩增。
其原理是接头引物处于“Y”接头的2个分叉单链上,序列及接头一样,只有及特异引物引导合成了接头的互补序列后,接头引物才能退火参及扩增,流程如图4。
方卫国等尝试将YADE法引入到昆虫病原真菌的分子生物学研究,并取得了成功,建立了适合于球孢白僵菌和金龟子绿僵菌YADE体系。
在已克隆的类球孢白僵菌类枯草杆菌蛋白酶基因CDEP-1的基础上,利用YADE法,克隆到该基因的启动子CDEPP。
先酶切球孢白僵菌基因组DNA,然后及“Y”形接头相连,取连接产物做模板,先以基因特异引物1做线性扩增,再以线性扩增产物为模板,以接头引物和基因特异引物2做指数扩增,只有当线性扩增时合成了含有接头引物的互补单链,接头引物才能及其发生退火,参及指数扩增,从而有效防止了接头引物的单引物扩增。
最后得PCR产物,进行序列分析确定为CDEP-1的上游启动子序列。
在应用YADE法时,内切酶的选择至关重要。
好的内切酶产生适合PCR扩增的片段,太大太小都不行。
为了得到合适的内切酶,需要从众多的内切酶中筛选。
研究表明,不同的物种有自己合适的内切酶。
YADE法延伸的起始片段可以是基因组DNA片段,也可以是cDNA片段,在延伸cDNA片段时,设计的引物需要避开内含子和外显子的边界,在内含子的位置未知的情况下,可考虑多合成1~2条特异引物,以提高扩增未知片段的机率。
该方法假阳性低、效率高,理论上能扩出所有目的片段。
1.6 TAlL-PCR
很早就有用随机引物的PCR,但由于无法有效地控制由随机引物引发的非特异产物的产生,所以一直未能广泛应用。
近年来由IJiu等设计的TAIL-PCR(TermalAsymmetricInterlacedPCR)又叫热不对称交错PCR,则解决了这个问题,后来有研究表明,经改良过的TAIL-PCR成功地从突变体中克隆到外源插入基因的旁侧序列,从而为启动子的克隆提供了有效的新方法。
 升级会员
升级会员 