数据挖掘复习题和答案.docx
《数据挖掘复习题和答案.docx》由会员分享,可在线阅读,更多相关《数据挖掘复习题和答案.docx(20页珍藏版)》请在冰豆网上搜索。
数据挖掘复习题和答案
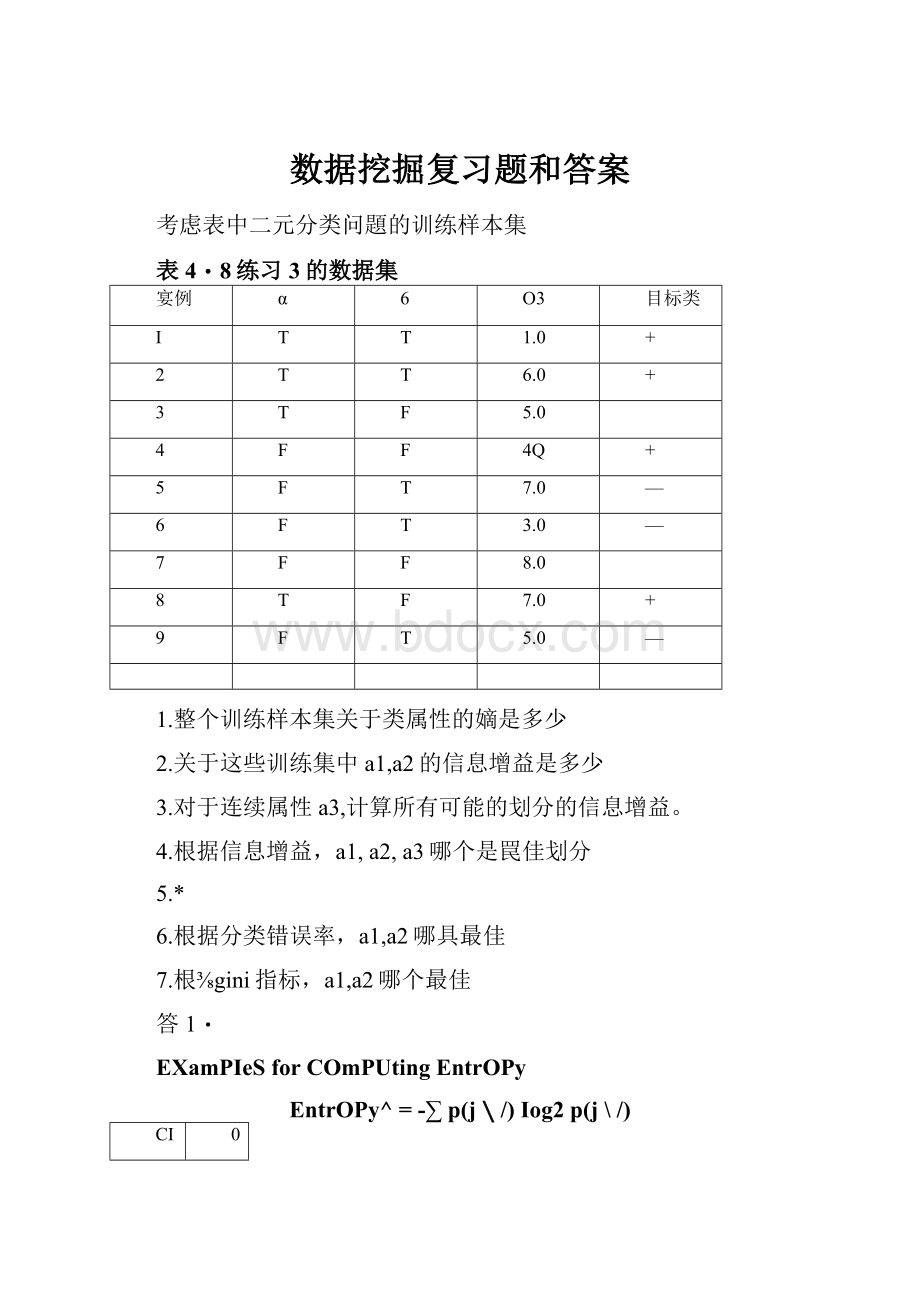
考虑表中二元分类问題的训练样本集
表4・8练习3的数据集
宴例
α
6
O3
目标类
I
T
T
1.0
+
2
T
T
6.0
+
3
T
F
5.0
4
F
F
4Q
+
5
F
T
7.0
—
6
F
T
3.0
—
7
F
F
8.0
8
T
F
7.0
+
9
F
T
5.0
—
1.整个训练样本集关于类属性的嫡是多少
2.关于这些训练集中a1,a2的信息增益是多少
3.对于连续属性a3,计算所有可能的划分的信息增益。
4.根据信息增益,a1,a2,a3哪个是罠佳划分
5.*
6.根据分类错误率,a1,a2哪具最佳
7.根⅜gini指标,a1,a2哪个最佳
答1・
EXamPIeSforCOmPUtingEntrOPy
EntrOPy^=-∑p(j∖/)Iog2p(j\/)
CI
0
C2
6
P(CI)=O/6=0P(C2)=6/6=1
EntrOPy≡-0IOgO-IlOgl=-O-O=O
Ri
1
C2
5
P(CI)=1/6
P(C2)=5/6
EntrOPy=-(1/6)Iog2(1/6)-(5/6)Iog2(5/6)=0.65
CI
2
C2
4
P(Cl)=2/6
P(+)二4/9andP(-)=5/9
P(C2)=4/6
EntrOPy=一(2/6)log?
(2/6)-(4/6)Iog2(4/6)=0.92
-4/9Iog(4/9)-5/9log(5/9)二・
答2:
SPlittingBaSecIOnINFO...
•InfOrmatiOnGain:
GAlN..=EntrOPy(P)-(Σ-Entropy(I)
ParentNode,PisSPIitintokPartrtiOns;
nlisnumberOfrecordsinPartitiOni
一MeaSUreSRedUCtiOninEntrOPyachievedbecauseOftheSPIit・ChOOSetheSPlitthatachievesmostreductiOn(maximizesGAIN)
一USedinID3andC4.5
一DiSadVantage:
TendStoPreferSPlitSthatresultinIargenUmberOfPartitiOns,eachbeingSmaIlbutPUre.
(估计不考)
FQrattributeαι5theCOrreSPOlldingCoulltSandPrObabilitieSare:
5
十
■
T
3
1
F
1
4
Theentropyforaγis
-(3∕4)l□g2(3∕4)-(1/4)Iog2
-(l∕5)l□g2(l∕5)-(4/5)lαg2(4/5)
=0.761G.
TherefoTertheinformationgainforλ1is0.9911—0.7GIG=0.2294.
FOrattributeQ2,theCOrreSPOndingCOlnItSandProbabilitieSare:
d*2
+
-
T
2
3
F
2
2
TIIeentropyforα2is
計一(2/5)l□g2(2/5)-(3∕5)l□g2(3/5)
+-(2∕4)log2(2∕4)-(2/4)Iog2(2/4)=0.9839.
TIIerefbreftheinformationgainforis0,9911一0.9839=0,0072,
答3:
COntinUOUSAttributes:
COmPUtingGiniIndex...
•FOrefficientCOmPUtation:
foreachattribute,
一SOrttheattributeOnVaIUeS
一LinearlySCanthesevalues,eachtimeUPdatingtheCOUntmatrixandCOmPUtingginiindex
一ChOOSetheSPlitPOSitiOnthathastheIeaStginiindex
α∙3
ClaSSIabel
SPlItPoint
EntrOPy
InfOGaLirl
1.0
十
2.0
0.8484
0.1427
3.0
-
3.5
0.9885
0.0026
4.0
+
4.5
0.918i
0.0728
5.0
5.0
—
55
0.9839
0.0072
6.0
一
6.5
0.9728
0.0183
7.0
7.0
+
7.5
0.888&
0.1022
答4:
ACCOrdingtoinformationgain,^producesthebestSPIit.答5:
EXamPIeSforCOmPUtingErrOr
ErrOr(J=I-maxP(J∖t)
=O
答6:
BinaryAttributes:
COmPUtingGlNIIndeX
•SPIitSintotwoPartitiOnS
•EffeCtOfWeighingPartitions:
一Larger2ndPUrerPartitiOnSareSOUghtfor.
NOdeNlNOdeN2
rq
Parent
Cl
Zo
Pl
IGiIli:
=0∙500
Gini(NI)
=1_(5/7)2_(2/7)2
=0.408
Gini(N2)
=1-(1/5)2-(4/5)2
=0.32
NI
N2
CI
5
1
C2
2
4
Gini=O.333
Gini(ChiIdren)
=7/12*0.408+
5/12*0.32
=0.371
4/18/200434
I-TantSteinbachKUmar
IntrOdU⅛ontoDataMinina
Forattributeα11theginiindexis
A片
δ1-(3/4)2-(1/4)2+-1-(1/5)2_(4/5)2=0ta444.
■aJJ∙
FOrattribute«2.theginiindexis
R4Γ'
ξ1-(2/5)2-(3/5)2+g1-(2/4)2_(2/4)2=0.488&.
■∙
SinCetheginiindexfora↑issmaller,itPrOduCeSthebettersplit.
考虑如下二元分类问题的数据集
A
B
类标号
T
F
+
T
T
T
T
÷
T
F
—
T
T
+
F
F
—
F
F
—
F
F
—
T
T
—
T
F
3二元分类问题不纯性度量之间的比较
1.计算信息增益,决罠树归纳算法会选用哪个属性
ThGCOntingenCytablesaft.erSPIittingOnattributesAandBarc:
TheOVerallentropybeforeSPIittingis:
EOrig=—0.4log0.4—().Glog0.C=0.9710
TheinformationgainafterSPlittingOnAis:
EA=T=-IlOgf-IIogl=O≡2
D_3.3()1()_n
EA=P=——IOgmmSg~=θ
Δ=Eorig-7∕WEλ=t-3∕10⅛=f=0.2813∣
TheinformationgainafterSPIittingOrlBis:
33II
EB=T=-Tl°g了—Tl°g[=0∙8113J5
EP=F=——IOg———log—=0.6500
△=Eorig-4∕10Eβ=T-6/1OEB=^=(),2565
Therefbre.attributeAWillboChoSCTItoSPlitthenode.
2.计算gini指标,决策树归纳会用哪个属性
TheOVeralIginibeforeSPIittingis:
Gorig=1-0.42-0.62=0.48
Th€?
gaininginiafterSPlittingOnAis:
Δ=GOrig-7/10GA=T-3/10G川=F=0J371
ThegaininginiafterSPlittingOnBis:
GB=T=I-Q)2-Q)2=0.37506"=1=(I)"(I)"2778
△=Gtσrig—4/1OGB==T—6/10GB==F=0.1633
Therefore,attributeBWillbeChOSelItoSPIitt.henode.
这个答案没问题
3.从图4T3可以看出炳和gini指标在[0」都是单调递增,而[「]之间单调递减。
有没有可能信息增益和gini指标增益支持不同的属性解释你的理由
YeSteventhoughthesemeasureshaveSimiIarrangeandmonOtOr)OUS
%
behavior,theirrespectivegains,Δ,WhiChareSCaIeddifferencesOfthemeasures,donotnecessarilybehaveintheSameway,asiIIUStratedbytheresultsinPartS(a)and(b)・
贝叶斯分类
EXamPIeOfNaYVeBayeSCIaSSifier
GiVenaTeStRecord:
X二(RefUnd二No,Married.InCOme二120K)
naiveBayeSClassifier:
©Tan,Stel∩Dacħ.KUmafInUOdUCtiOnlODataMininQ4∕ia^200466
7.考虑≡540中的数据集。
匀慝7茁数抿建
τd^:
A
B
C
类
1
O
O
O
+
2
O
O
1
■
3
O
1
1
-
4
O
1
1
一
5
O
O
1
÷
6
1
O
1
+
7
1
O
1
8
1
O
1
一
9
1
I
1
+
10
1
O
1
+
(a)估计条件概率P(Aj+),P(B∣+),P(Q+),P(A卜),P(EH)和P(C∏°
Ib)根据(a)中的条件概率,使用朴素贝叶斯方法预测测试样本(A=O,θ=l,C=O)的类标号。
(C)便用m佔计方法(p=l∕2且加=4)估计条件概率。
@)同(b),使用(C)中的条件概率。
@)比较估计概率的两种方法。
哪一种更好?
为什么?
1.PU=1/-)=2/5二,P(B二1/-)二2/5二,
P(C
1/-)=1,P^A
=O/-)=3/5=,
P(B
0/-)=3/5=,
P(C=O/-)=0;P(A=1/+)=3/5=,
PlB
1/+)=1/6=,
P(C=1升)=2/5=,
P{A
0∕÷)=2/5=,
P(B=OA)=4/5=,
P(C=0∕÷)=3/5二.
LotP(A=OTZ?
=1,Cr=O)=K.
P(+∖A=(KZ?
=1、C=0)
_P(A=O,B=LC=0∣+)XF(+)=P(A=O,Z?
=1,C=0)
_P(A=()∣+)F(β=1∣+)P(C=0∣+)XP(+)κ~
=().4X0.2×().6X0.5∕∕<
=().024/K・
P(-∖A=O.B=1.C=0)
P(A=Om=l,Cf=()∣-)XΓ(-)
=P(Λ=O.Z?
=LC=O)
_P(A=0∣-)XP(B=1∣-)×P(C=O-)XF(-)
K
=0/7V
2.TheCIaSSIaI)ClShOUIdbe*+\
3.P(A=0/+)=(2+2)/(5+4)=4/9,
PM二0/-)=(3+2)/(5+4)=5/9,
P(B=1/+)=(1+2)/(5+4)=3/9,
P{B=1/-)=(2+2)/(5+4)=4/9,
P(C=O/+)=(3+2)/(5+4)=5/9,
P(C=0/-)=(0+2)/(5+4)=2/9.
4.LetP(A=0,5=1,C=O)=K
P(+∣4=OR=LC=O)
_P(4=β5β=I5C=O∣÷)XP(÷)
=n(q=o,ZJ=I,o=0〉
_P(A=U∣+)"(B=1∣+)P(C=U∣+>:
XP(+)K
(d∕Q)×(3/9)X(5/9)X(15
=K
=0.0412/K
P(-∣A=O^=1,C=U)
_P(Λ=0:
〃=IC=Ol—)乂P(-)
=P(A=O,D=1,C=O)
P(A=U∣-)XP(β=1∣-)XP(C=0∣-)XP(_)
=K
(5/9)X(4/9)X(2∕Q)x0.5
=K
=0.0274∕∕<
TheCIaSSIabelSholLldbe?
+\
5当的条件概率之一是零,則估计为使用m-估计概率的方法的条件概率是史好的,因为我们不希望整个表达式变为零。
&考虑表,11中的数据集。
«5-11习题8的数据集
(a)估计条件概率P(A=II+),P(B=II+),P(C=Il+),P(A=II-),P(B=1卜)和P(C=IU
(b)根据(a)中的条件槪率,使用朴素贝叶斯方法预测测试样本3=l,B=l,C≈i)的类标号。
(C)比较P(A=I),P(Λ≈1,B=1)«陈述A、〃之间的关系。
(d)对P(A=1),P(B=0)和P(A=UB=0)重复(C)的分析。
(e)比较P(A=:
1,Hll类=+)与P(A=Il类=+)和P(B=Il类*)。
给定类+,⅛gA>B条件独立吗?
1.P{A=1/+)=,P{B=1/+)=,P(C=1/+)=,P{A-
1/-)=,P(B=I/-)=,andP(C=1/-)=
2.
LetR:
(.A=↑fB-1,C=I)bethetestrecord.TOdetermineits
class,v/eneedtoCOmPUtePalR)andP{-IR)・USingBayeStheorem,P^IR)=PIRlHPW/P(R)andP(-IR)=P(RlmPe・
SinCeP(+)=P(-)=andP(RisCOnStant,RCanbeClaSSifiedby
COmParingPalR)andP{-IR)・
FOrthisquestion,
PIRiH=PU=I/+)XP(B=∖/+)XP(C=∖2=
PIRl-)=P(彳二1/-)XP(B=∖卜)XP(C=H-)=
SinCeP(RImisIarger,therecordiSassignedto(+)class.3.
P(A=1)=,P(B=1)=andP{A=I^=I)=P(A)×
P{ff)=・Therefore,AandBareindependent.
4.
P{A=1)=fP(B=O)=,andP(A=1,F=O)=PIA=1)XP(B=O)=・AandBareStiIIindependent.
5.
COmPareP{A=IJ^=I/+)=againstP(A=1/+)=and
P(B=11ClaSS=+)=・SinCethePrOdUCtbetweenP(A=1/+)andP(A=1/-)arenottheSameasP(A=1,5=1∕÷),AandBare
notCOnditiOnaIlyindependerτtgiventheClaSS・
三.使用下表中的相似皮矩阵进行单琏和全链展次聚类。
绘制树状况显示结果,树状图应该淸楚地显示合并的次序。
Table8.1.SimilantymatrixforEXerCiSe16.
2.考虑表6>22中显示的数据集。
表6∙22购物篮事务的例子
顾客ID
事务ID
购买项
1
OOol
{atd9e}
1
0024.
{atbfc^}
2
0012
{cιMe}
2
0031
{αβc∕i,e)
3
0015
{6c∙e}
3
0022
{M>ej
4
0029
4
0040
M,c}
5
0033
5
0038
(a)将每个事务ID视为一个购物篮,计算项集{e}.{b.d}和{b∙de}的支持虔。
(b)使用(町的计算结果,计算关联规则{b,d}-{e}和何一&刃的置信度。
置信度是对称的度量吗?
(C)将每个顾客ID作为一个购物篮,重复(a)。
应当将每个项看作一个二元变量(如果一
个顼在顾客的购买事务中至少出现了一次,则为h杏则,为0)。
9)便用(C)的计算结果,计算关联规则2,N}f何和何一{方,刃的置信度。
(e)假定印和G是将每个事务ID作为一个购物篮时关联规则r的支持度和宣信度,而也和C2是将每个顾客ID作为一个购物篮肘关联规则r的支持度和置信度。
讨论Sl和$2或G和Q之间是否存在某种关系?
s({e})=
就{"})=
822•∙∙OOO
---
8-W2-W2-W
⅛({6,d,e})=
NsconfidenceisnotaSyTnmetriCmeasure.
仆})=7=0.8
O
s({"∕})=∣=1
s({b,d,E})=T=0.8
∙>
c(bd—>e)
c(e—>bd)
TherearenoapparentreIatiOnShiPSbetWeens,s,c9andc.
6.考虑表6∙23中显示的购物篮事务。
表6・23购物篮事务
事务ID
购买坝
1
2
3
4
5
6
7
8
9
10
{牛奶.啤酒.尿布}{回包,黄泊,牛奶}{牛奶•尿布.饼干}{面包•黄饼千}{啤酒•饼干,尿布}
{牛奶•尿布.面包,黄沟}{面包•黃油,尿布}
{咤酒,尿布}
{牛奶,尿布•面包,贺油}(呻酒•饼干}
(a)从这些数据中,能够提取出的关联规则的最大数量是多少(包括零支持度的规则)?
(b)能够提取的频繁项集的最大长度是多少(假定最小支持度>0)?
(C)写出从该数据集中能够提取的3∙项集的最大数量的表达式。
(d)找出一个具有最大支持度的项集(长度为2或更大)。
(e)找出一对项α和力,使得规则{a]-[b}和{6}f{α}具有相同的置信度。
(a)WhatistheIIIaXimllmnιπnberOfassociationrulesthatCanbeωctτactedfromthis(Iata(includingrulesthathaveZCrQsupport)?
Answer:
ThereareSiXitemsinthe(Iataset.ThereforethetotalnumberOfrulesisGO2.
(b)WhatisthemaximumSiZeOffrequentitomsotsthat.Canbeextracted(assumingminsup>O)?
Answer:
BeCaIISetheIolIgeSttransartionContainS4items,theιnaxi-IInlInSiZeOffrequentitemsetis4.
(C)WrLteanexpressionforthemaximumIlILmberOfSiZe-3itemsetsthatCailbederivedfromthisdataset.
Answer:
(;)=20.
(d)FiTldAnitemsot(OfSiZ€2OTIaTgOr)thathastheIargeStsupport-Answer:
{Bread.Butter}.
(e)FindaPairOfitems,αandb.SUChthattherules{a}—{6}aιιd{b}—>{a}havetheSaIneCOlIfidCnCe・
Answer:
(BeCrJCOOkieS)Or(Bread,Butter).
8.A"3√算法使用产生-计数的策略找出频繁项集。
通过合并一对大小为&的频緊项集得到一个大小为炽4的候选项集(称作猴选产生步骤)。
在候选项集剪枝步骤中,如果一个候选项集的任何一个子集
 升级会员
升级会员 