SPSS实验设计1.docx
《SPSS实验设计1.docx》由会员分享,可在线阅读,更多相关《SPSS实验设计1.docx(19页珍藏版)》请在冰豆网上搜索。
SPSS实验设计1
实验一两变量相关分析
产妇与婴儿体重相关分析
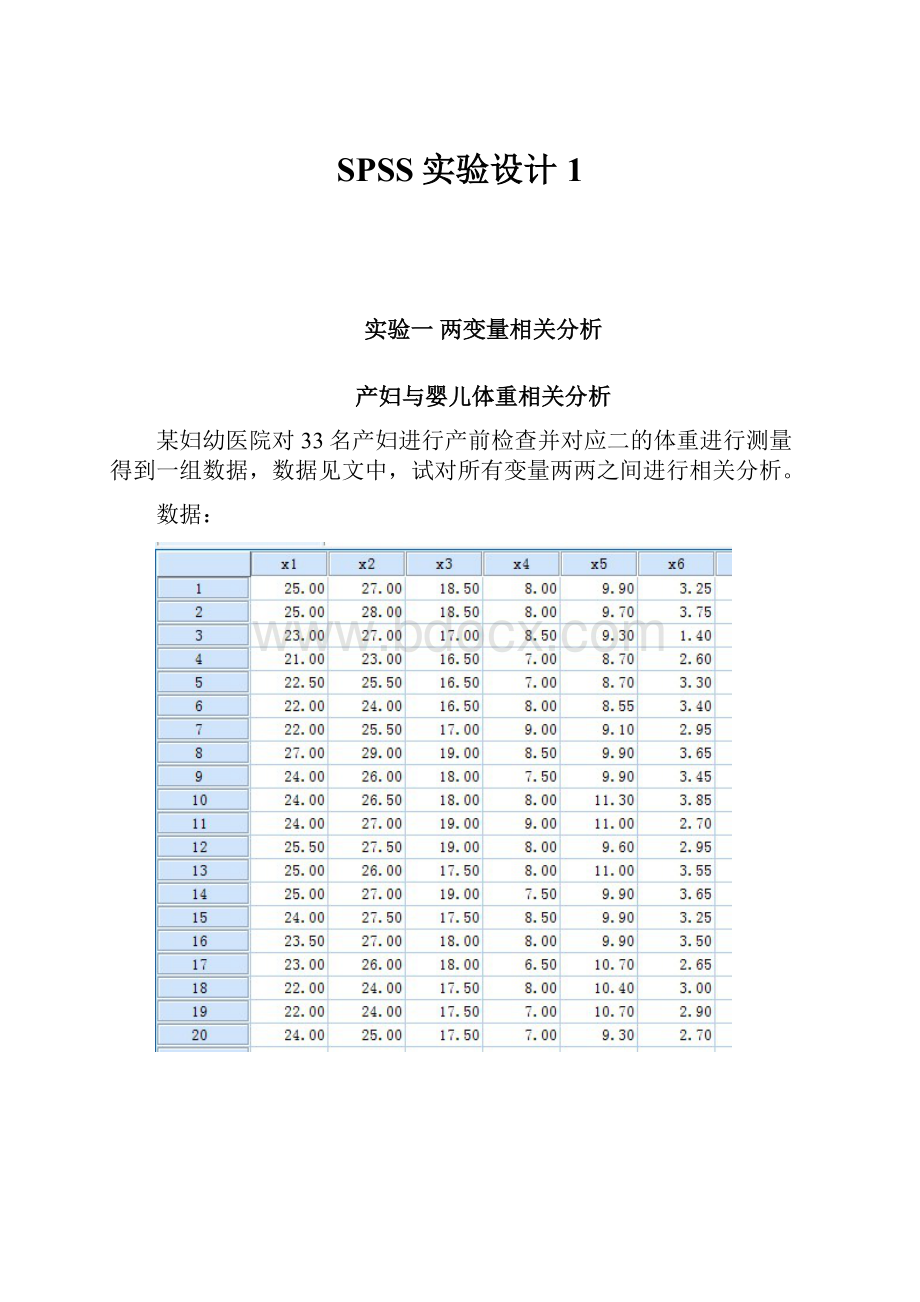
某妇幼医院对33名产妇进行产前检查并对应二的体重进行测量得到一组数据,数据见文中,试对所有变量两两之间进行相关分析。
数据:
实验结论:
相关性
描述性统计量
均值
标准差
N
髂前上棘间径
23.6515
1.20211
33
髂脊间径
25.9394
1.31552
33
耻骶外径
17.5909
.97991
33
坐骨节间径
7.8485
.64329
33
血红蛋白
9.6803
.90657
33
婴儿体重
3.0894
.51474
33
表1-1
表1-1给出了基本的描述性统计结果,其中各行数据分别是6组数据的均值,样本标准差及样本容量。
相关性
髂前上棘间径
髂脊间径
耻骶外径
坐骨节间径
血红蛋白
婴儿体重
髂前上
棘间径
Pearson相关性
1
.796**
.684**
.283
.269
.340
显著性(双侧)
.000
.000
.110
.130
.053
平方与叉积的和
46.242
40.303
25.795
7.008
9.373
6.728
协方差
1.445
1.259
.806
.219
.293
.210
N
33
33
33
33
33
33
髂脊
间径
Pearson相关性
.796**
1
.617**
.441*
.213
.277
显著性(双侧)
.000
.000
.010
.235
.119
平方与叉积的和
40.303
55.379
25.432
11.947
8.111
6.004
协方差
1.259
1.731
.795
.373
.253
.188
N
33
33
33
33
33
33
耻骶
外径
Pearson相关性
.684**
.617**
1
.171
.377*
.273
显著性(双侧)
.000
.000
.341
.031
.124
平方与叉积的和
25.795
25.432
30.727
3.455
10.709
4.407
协方差
.806
.795
.960
.108
.335
.138
N
33
33
33
33
33
33
坐骨节
间径
Pearson相关性
.283
.441*
.171
1
.166
.054
显著性(双侧)
.110
.010
.341
.355
.765
平方与叉积的和
7.008
11.947
3.455
13.242
3.102
.572
协方差
.219
.373
.108
.414
.097
.018
N
33
33
33
33
33
33
血红
蛋白
Pearson相关性
.269
.213
.377*
.166
1
.027
显著性(双侧)
.130
.235
.031
.355
.880
平方与叉积的和
9.373
8.111
10.709
3.102
26.300
.408
协方差
.293
.253
.335
.097
.822
.013
N
33
33
33
33
33
33
婴儿
体重
Pearson相关性
.340
.277
.273
.054
.027
1
显著性(双侧)
.053
.119
.124
.765
.880
平方与叉积的和
6.728
6.004
4.407
.572
.408
8.479
协方差
.210
.188
.138
.018
.013
.265
N
33
33
33
33
33
33
表1-2
**.在.01水平(双侧)上显著相关。
*.在0.05水平(双侧)上显著相关。
表1-2给出了各个变量的皮尔逊相关系数矩阵及相关性检验结果,其中每个行变量与列变量交叉单元格是二者的相关统计量的值。
例如,髂前上棘间径与髂脊间径,耻骶外径之间的相关系数分别是0.796、0.684,反映了髂前上棘间径与髂脊间径,耻骶外径具有高度的正相关关系。
而血红蛋白与耻骶外径之间的相关系数为0.377,这说明,血红蛋白与耻骶外径虽然具有一定的正相关关系,但相关系数较低,说明两者之间有差异。
非参数相关系数
髂前上棘间径
髂脊间径
耻骶外径
坐骨节间径
血红蛋白
婴儿体重
Kendall的tau_b
髂前上棘间径
相关系数
1.000
.606**
.606**
.202
.236
.229
Sig.(双侧)
.
.000
.000
.163
.080
.085
N
33
33
33
33
33
33
髂脊间径
相关系数
.606**
1.000
.534**
.388**
.165
.261*
Sig.(双侧)
.000
.
.000
.006
.215
.046
N
33
33
33
33
33
33
耻骶外径
相关系数
.606**
.534**
1.000
.146
.311*
.203
Sig.(双侧)
.000
.000
.
.307
.020
.122
N
33
33
33
33
33
33
坐骨节间径
相关系数
.202
.388**
.146
1.000
.109
.058
Sig.(双侧)
.163
.006
.307
.
.431
.670
N
33
33
33
33
33
33
血红蛋白
相关系数
.236
.165
.311*
.109
1.000
-.028
Sig.(双侧)
.080
.215
.020
.431
.
.827
N
33
33
33
33
33
33
婴儿体重
相关系数
.229
.261*
.203
.058
-.028
1.000
Sig.(双侧)
.085
.046
.122
.670
.827
.
N
33
33
33
33
33
33
Spearman的rho
髂前上棘间径
相关系数
1.000
.708**
.740**
.250
.317
.317
Sig.(双侧)
.
.000
.000
.161
.072
.072
N
33
33
33
33
33
33
髂脊间径
相关系数
.708**
1.000
.652**
.481**
.221
.350*
Sig.(双侧)
.000
.
.000
.005
.216
.046
N
33
33
33
33
33
33
耻骶外径
相关系数
.740**
.652**
1.000
.178
.413*
.290
Sig.(双侧)
.000
.000
.
.320
.017
.101
N
33
33
33
33
33
33
坐骨节间径
相关系数
.250
.481**
.178
1.000
.142
.079
Sig.(双侧)
.161
.005
.320
.
.432
.663
N
33
33
33
33
33
33
血红蛋白
相关系数
.317
.221
.413*
.142
1.000
-.013
Sig.(双侧)
.072
.216
.017
.432
.
.942
N
33
33
33
33
33
33
婴儿体重
相关系数
.317
.350*
.290
.079
-.013
1.000
Sig.(双侧)
.072
.046
.101
.663
.942
.
N
33
33
33
33
33
33
表1-3
**.在置信度(双测)为0.01时,相关性是显著的。
*.在置信度(双测)为0.05时,相关性是显著的。
表1-3给出了肯德尔和斯皮尔曼的相关系数矩阵和相关检验的结果。
注意图中标有星号的相关系数,这个结果与皮尔逊相关性检验的结果有些差异:
在0.05的显著性水平下,婴儿体重与髂脊间径之间的相关系数是显著的。
这说明不同的检验和分析方法的结论可能会有差异,要求我们在分析过程中要尽量使用多种方法进行分析,谨慎下结论,从而提高分析结果的可靠性。
附注:
创建的输出
04-6月-201212时30分31秒
注释
输入
数据
D:
\源文件\Chap04\chanfu.sav
活动的数据集
数据集2
过滤器
权重
拆分文件
工作数据文件中的N行
33
缺失值处理
缺失的定义
用户定义的缺失值将作为丢失对待。
使用的案例
每对变量的统计量是根据变量对中具有有效值的所有案例计算的。
语法
NONPARCORR
/VARIABLES=x1x2x3x4x5x6
/PRINT=BOTHTWOTAILNOSIG
/MISSING=PAIRWISE.
资源
处理器时间
0000:
00:
00.031
已用时间
0000:
00:
00.079
允许的案例数目
92521案例a
实验二线性回归分析
高血压病因线性回归分析
为研究男性高血压患者的血压与年龄、身高、体重等变量的关系,随机测量了32名40岁以上男性的血压、年龄、身高及吸烟史。
试建立血压作为被解释变量,其他变量作为解释变量的线性回归模型并进行分析。
数据表:
实验结论:
回归
描述性统计量
均值
标准偏差
N
血压
144.4375
14.30303
32
年龄
53.4375
6.89056
32
吸烟
.5313
.50701
32
体重指数
3.53484
.782755
32
表2-1
表2-1给出了基本的描述性统计结果,其中各行数据分别是各组数据的均值,样本标准差及样本容量。
相关性
血压
年龄
吸烟
体重指数
Pearson相关性
血压
1.000
.818
.243
.659
年龄
.818
1.000
-.115
.621
吸烟
.243
-.115
1.000
.069
体重指数
.659
.621
.069
1.000
Sig.(单侧)
血压
.
.000
.090
.000
年龄
.000
.
.266
.000
吸烟
.090
.266
.
.354
体重指数
.000
.000
.354
.
N
血压
32
32
32
32
年龄
32
32
32
32
吸烟
32
32
32
32
体重指数
32
32
32
32
表2-2
表2-2给出了相关系数矩阵表,表中显示各个变量两两之间的皮尔逊相关系数矩阵及相关性检验结果,其中每个行变量与列变量交叉单元格是二者的相关统计量的值。
从表中看到因变量(血压)与自变量年龄、体重指数之间的相关系数分别为0.818、0.659,反应血压与年龄、体重指数之间存在显著的相关关系;血压与吸烟之间的相关系数为0.243,吸烟与其他几个自变量之间的相关系数也很小,说明他们之间线性关系不明显。
另外,年龄与体重指数之间的相关系数为0.621,说明它们之间存在显著的相关关。
输入/移去的变量b
模型
输入的变量
移去的变量
方法
1
体重指数,吸烟,年龄
.
输入
a.已输入所有请求的变量。
b.因变量:
血压
表2-3
表2-3给出了进入模型和被剔除的变量的信息,从表中我们可以看出,所有自变量都进入模型,说明我们的解释变量都是显著并且是有解释力的。
模型汇总b
模型
R
R方
调整R方
标准估计的误差
Durbin-Watson
1
.895a
.801
.780
6.70636
1.213
a.预测变量:
(常量),体重指数,吸烟,年龄。
b.因变量:
血压
表2-4
表2-4给出了模型整体拟合的效果的概述,模型的拟合优度系数为0.895,反映了因变量与自变量之间存在高度显著的线性相关关系。
表里还显示了R平方以及调整的R值估计标准误差。
另外表中还给出了DW=1.213。
Anovab
模型
平方和
df
均方
F
Sig.
1
回归
5082.566
3
1694.189
37.669
.000a
残差
1259.309
28
44.975
总计
6341.875
31
a.预测变量:
(常量),体重指数,吸烟,年龄。
b.因变量:
血压
表2-5
表2-5给出了方差分析表,我们可以看到模型的设定检验F统计量的值为37.669,显著性水平的P值几乎为0,也就是说我们的模型通过了设定检验,因变量与自变量之间的线性关系明显。
系数a
模型
非标准化系数
标准系数
t
Sig.
B
标准误差
试用版
1
(常量)
45.724
9.746
4.692
.000
年龄
1.547
.228
.745
6.798
.000
吸烟
8.922
2.431
.316
3.670
.001
体重指数
3.195
1.995
.175
1.601
.120
a.因变量:
血压
表2-6
表2-6给出了回归系数表和变量显著性检验的T值,我们发现,只有体重指数没有达到显著性水平,因此,我们要将这个变量剔除,从这里我们也可以看出,模型虽然通过了设定检验,但很有可能不通过变量的显著性检验。
残差统计量a
极小值
极大值
均值
标准偏差
N
预测值
119.5472
168.4835
144.4375
12.80444
32
标准预测值
-1.944
1.878
.000
1.000
32
预测值的标准误差
1.648
5.992
2.245
.775
32
调整的预测值
118.7923
175.4356
144.5559
13.31790
32
残差
-9.57664
13.71040
.00000
6.37361
32
标准残差
-1.428
2.044
.000
.950
32
Student化残差
-1.474
2.206
-.003
1.012
32
已删除的残差
-10.20067
15.96993
-.11840
7.34545
32
Student化已删除的残差
-1.507
2.384
.007
1.038
32
Mahal。
距离
.903
23.777
2.906
3.982
32
Cook的距离
.000
.395
.043
.078
32
居中杠杆值
.029
.767
.094
.128
32
a.因变量:
血压
表2-7
表2-7给出了残差分析表,表中显示了预测值、残差、标准化预测值、标准化残差的极小值、极大值、均值、标准差及样本容量等统计指标。
根据概率的3西格玛原则,标准化残差的绝对值最大为2.044,小于3,说明样本数据中没有奇异值。
图表
图2-1图2-2
图2-1,2-2给出了模型残差直方图,由于我们在模型中始终假设残差服从正态分布,因此我们可以从这两张图中直观地看出回归后实际残差是否符合我们的假设。
从直方图与附于图上的正态分布曲线相比较,可以认为残差分布不是明显的服从正态分布。
但是,从2-2的散点分布状况来看,散点大致散布于斜线附近,因此可以认为残差分布基本上是正态的。
实验三配对样本T检验(自学)
检验两种轮胎耐磨性的差异
为了比较两种橡胶轮胎的耐磨性,分别从甲乙两家生产地同规格的前轮轮胎中随机的抽取10只,将它们随机的安装在10辆汽车吊左右轮胎上,行驶相同的里程之后,测得各只轮胎磨损量的数据,试用配对样本T检验过程检验两种轮胎的耐磨性之间的差异。
数据表:
实验结论:
T检验
成对样本统计量
均值
N
标准差
均值的标准误
对1
左轮胎磨损量
614.2000
10
119.64466
37.83496
右轮胎磨损量
586.9000
10
99.31258
31.40540
表3-1
表3-1给出了几个基本的配对样本描述性统计量,包括左右轮磨损前后的均值、标准差等,从这里可以看出左右轮胎磨损量的均值差别不大。
成对样本相关系数
N
相关系数
Sig.
对1
左轮胎磨损量&右轮胎磨损量
10
.989
.000
表3-2
表3-2给出了两配对样本之间的相关系数,相关系数的值为0.989,说明两组样本之间有显著的相关性。
成对样本检验
成对差分
t
df
Sig.(双侧)
均值
标准差
均值的标准误
差分的95%置信区间
下限
上限
对左轮胎磨损量-右轮胎磨损量
27.30000
25.82441
8.16639
8.82633
45.77367
3.343
9
.009
表3-3
表3-3给出了正式的配对检验结果,从图中看到T统计量的值为3.343,双尾显著性水平的P值为0.009,小于0.05,因此拒绝原假设,这样我们认为左右轮胎的磨损具有显著的差异。
 升级会员
升级会员 