8点流水线型FFT的VerilogHDL实现.docx
《8点流水线型FFT的VerilogHDL实现.docx》由会员分享,可在线阅读,更多相关《8点流水线型FFT的VerilogHDL实现.docx(47页珍藏版)》请在冰豆网上搜索。
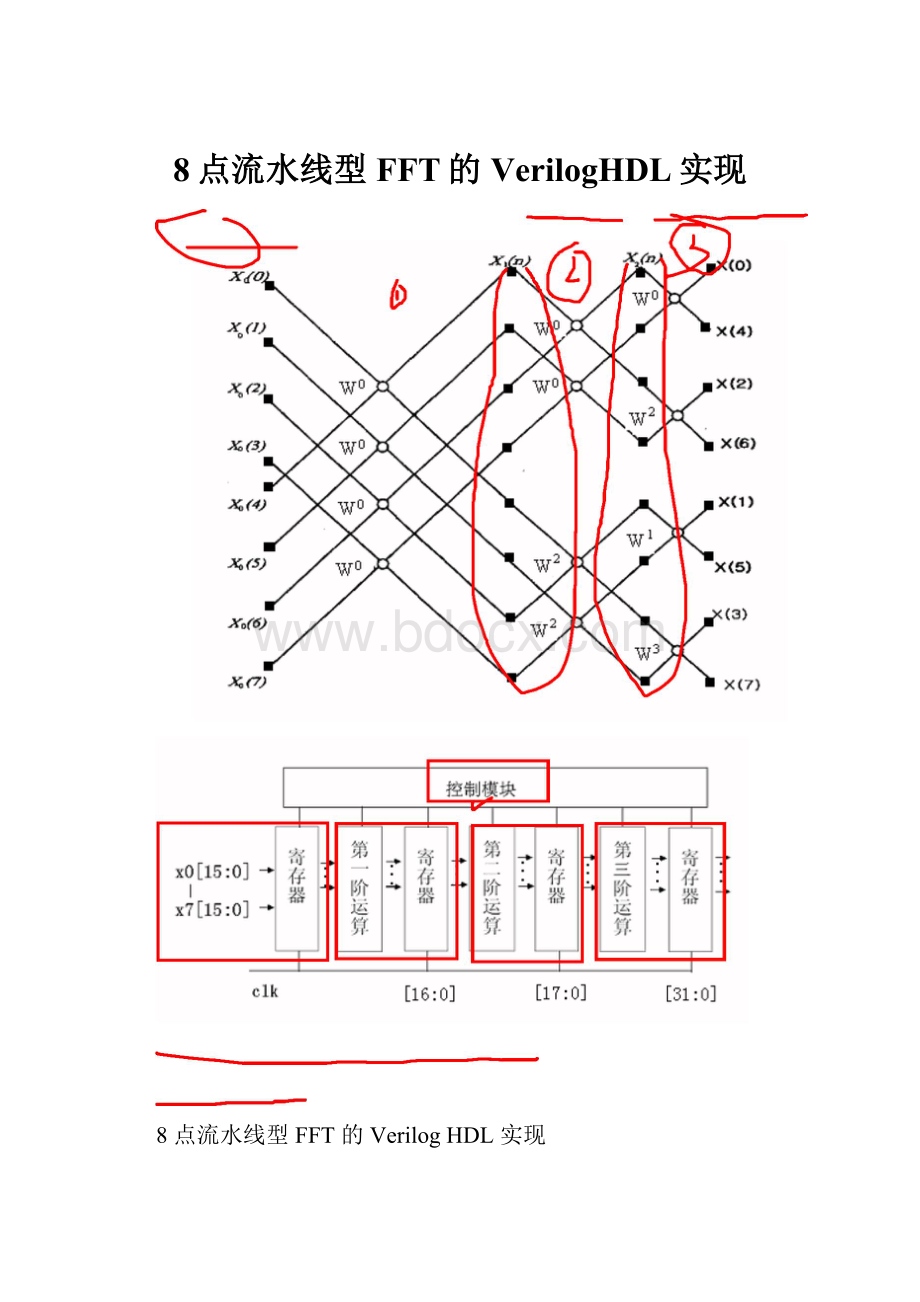
8点流水线型FFT的VerilogHDL实现
8点流水线型FFT的VerilogHDL实现
梁志明
华南理工大学
calaok@
(一)算法介绍
采用图中的结构,x0(0)~x0(7)为输入数据,位宽为16位;输出数据的位宽为32位,倒
序输出。
图38点FFT算法图
(二)系统设计
图4系统总框图
1、系统总框图如图4所示,总共包括一下几个模块:
1.。
对应三阶运算,共采用三个运算子模块:
第一阶运算模块:
对应蝶形算子只有W0(W0=1),
第二阶运算模块:
对应蝶形算子有W0、W2(W2=-j),
第三阶运算模块:
对应蝶形算子有W0、W1、W2、W3。
2.
针对各阶运算,:
第一阶控制模块;
第二阶控制模块;
第三阶控制模块。
2、各个运算模块分析。
1.第一阶运算模块:
控制模块的作用是
控制每个阶段的操
作
模块功能:
完成FFT第一阶蝶形运算。
模块设计:
此时蝶形算子只有W0,故蝶形运算结果为C=A+B,D=A-B。
因此,只需要对输入
数据做加减法即可。
考虑资源复用,这里定义一个16位的加法器和减法器,
。
2.第二阶运算模块
模块功能:
完成FFT第二阶蝶形运算。
模块设计:
第二阶运算有蝶形算子W0、W2。
对于W2蝶形运算结果为C=A+jB,D=A-jB,因
此,
对于W0算子,这里定义了一个17位有符号数加法器和减法器处理。
对于W2算子,对于运算结果的实部,可;针对虚部,对于结
果C,只需将B扩展成18位,对于结果D只用取B的补码,计算过程流程如下图。
相当于多路开关
图6第二阶运算模块
3.第三阶运算模块
这个部分是因为有
负数的出现
模块功能:
完成FFT第三阶蝶形运算。
模块设计:
第三阶运算模块:
对应蝶形算子有W0、W1、W2、W3。
采用设计要求中提示的通用
蝶形运算方法:
Rc=Ra+Rb*+(Ib-Rb)sin
Ic=Ia+Ib*+(Ib-Rb)sin
这个是蝶形运算的
通用公式
Rd=Ra-[Rb*cosaddsin+(Ib-Rb)sin]
Id=Ia-[Ib*cossubsin+(Ib-Rb)sin]
其中,
cosaddsin=cos(2πp/N)+sin(2πp/N)
cossubsin=cos(2πp/N)−sin(2πp/N)
sin=sin(2πp/N)
;这里,N=8。
根据上述公式,在进行一次蝶形运算时,只需首先确定cosaddsin,cossubsin,sin,然
后计算出(Ib-Rb)sin,Rb*cosaddsin,Ib*cossubsin,最后将结果相加减即可。
(三)仿真结果分析
1、数据输入
图7数据输入
(1)输入数据是两组连续8个的串行数据:
A=[12344321];
B=[-5-555-5-555];
数据在系统时钟的上升沿被采集。
2、最后蝶形算子运算波形
这里P的取值有0,1,2,3
图8最后蝶形算子运算波形
(1)蝶形算子运算公式为:
R=R+R⎢⎡⎣cos(2πp/N)+sin(2πp/N)⎥⎤⎦+(I-R)sin(2πp/N)
cabbb
I=I+I⎡⎣⎢cos(2πp/N)-sin(2πp/N)⎦⎥⎤(I)sin(2πp/N)
cab+b-R
b
R=R{R⎡⎣⎢cos(2πp/N)+sin(2πp/N)⎤⎦⎥+(I-R)sin(2πp/N)}
d-bbb
a
I=I{I⎡⎣⎢cos(2πp/N)-sin(2πp/N)⎤⎦⎥(I)sin(2πp/N)}
d-b+b-R
a
b
输入信号对应:
Imul_Ra->Ra
Imul_Ia->Ia
Imul_Rb->Rb
Imul_Ib->Ib
输入a和b,输出是c
和d
Imulc_Rout->Rc
Imulc_Iout->Ic
Imuld_Rout->Rd
Imuld_Iout->Id
波形上的输入信号为实际大小的有符号数,由于在
3、输出信号波形
图9输出信号波形
输出结果最后经过了排序,。
输
出数据为经过位数扩展后的数据,
(1)当输入数据为A=[12344321]时,MATLAB运算的数据为:
20.0000
-5.8284-2.4142i
0
-0.1716-0.4142i
0
-0.1716+0.4142i
0
-5.8284+2.4142i
硬件运算的结果为:
10240
-2984-1236i
0
-88-212i
0
-88+212i
0
-2984+1236i
(2)当输入数据为B=[-5-555-5-555]时,MATLAB运算的数据为:
0
0
-20.0000+20.0000i
0
0
0
-20.0000-20.0000i
0
硬件运算结果为:
0
0
-10240+10240i
0
0
0
-10240-10240i
0
(四)源程序
(1)add16.v
moduleadd16(a,b,out);
input[15:
0]a,b;
output[16:
0]out;
reg[16:
0]out;
两个数相加,所以
要扩展一位数
wire[16:
0]a1={a[15],a[15:
0]};
wire[16:
0]b1={b[15],b[15:
0]};
always@(a1orb1)
begin
out=a1+b1;
end
这里的目的是什么
呢?
好像就是避免
溢出进位造成结果
不正确?
endmodule
(2)sub16.v
modulesub16(a,b,out);
input[15:
0]a,b;
output[16:
0]out;
reg[16:
0]out;
wire[16:
0]a1={a[15],a[15:
0]};
wire[16:
0]b1={b[15],b[15:
0]};
always@(a1orb1)
begin
out=a1-b1;
end
endmodule
(3)add17.v
moduleadd17(a,b,out);
input[16:
0]a,b;
output[17:
0]out;
reg[17:
0]out;
wire[17:
0]a1={a[16],a[16:
0]};
wire[17:
0]b1={b[16],b[16:
0]};
always@(a1orb1)
begin
out=a1+b1;
end
endmodule
(4)sub17.v
modulesub17(a,b,out);
input[16:
0]a,b;
output[17:
0]out;
reg[17:
0]out;
wire[17:
0]a1={a[16],a[16:
0]};
wire[17:
0]b1={b[16],b[16:
0]};
always@(a1orb1)
begin
out=a1-b1;
end
endmodule
(5)addw2_17.v
moduleaddw2_17(a,b,Rout,Iout);
input[16:
0]a,b;
output[17:
0]Rout,Iout;
reg[17:
0]Rout,Iout;
wire[17:
0]a1={a[16],a[16:
0]};
wire[17:
0]b1={b[16],b[16:
0]};
always@(a1orb1)
begin
Rout=a1;
Iout=18'b0-b1;
end
endmodule
(6)subw2_17.v
modulesubw2_17(a,b,Rout,Iout);
input[16:
0]a,b;
output[17:
0]Rout,Iout;
reg[17:
0]Rout,Iout;
wire[17:
0]a1={a[16],a[16:
0]};
wire[17:
0]b1={b[16],b[16:
0]};
always@(a1orb1)
begin
Rout=a1;
Iout=b1;
end
endmodule
(7)Imul.v
moduleImul(p,
Ra_in,Ia_in,
Rb_in,Ib_in,
Rc_out,Ic_out,
Rd_out,Id_out
);
input[1:
0]p;
?
?
?
?
?
?
?
?
好像是可以取值为
0,1,2,3
input[17:
0]Ra_in,Ia_in,Rb_in,Ib_in;
output[31:
0]Rc_out,Ic_out;
reg[31:
0]Rc_out,Ic_out;
output[31:
0]Rd_out,Id_out;
reg[31:
0]Rd_out,Id_out;
wire[18:
0]Rb_in1={Rb_in[17],Rb_in[17:
0]};
wire[18:
0]Ib_in1={Ib_in[17],Ib_in[17:
0]};
reg[10:
0]cosaddsin,cossubsin,sin;
always@(p)
begin
case(p)
?
?
?
?
?
?
?
?
难道这就是传说的
扩大了512倍
endcase
end
wire[18:
0]IR=Ib_in1-Rb_in1;
wire[29:
0]R_sin;
mult19_11mult19_11(
.dataa(IR),
.datab(sin),
.result(R_sin));
wire[28:
0]R_cosaddsin;
mult18_11mult18_11A(
.dataa(Rb_in),
.datab(cosaddsin),
.result(R_cosaddsin));
reg[30:
0]R_Ra;
always@(Ra_in)
begin
if(Ra_in[17]==1'b1)
begin
R_Ra={4'hf,~{~Ra_in[17:
0]+18'b1,9'b0}+27'b1};
end
else
begin
R_Ra={4'b0,Ra_in[17:
0],9'b0};
end
end
wire[30:
0]R_cosaddsin1={R_cosaddsin[28],R_cosaddsin[28],R_cosaddsin[28:
0]};
reg[30:
0]RRc;
always@(R_RaorR_cosaddsin1)
begin
RRc=R_Ra+R_cosaddsin1;
end
wire[31:
0]R_sin1={R_sin[29],R_sin[29],R_sin[29:
0]};
wire[31:
0]RRc1={RRc[30],RRc[30:
0]};
always@(R_sin1orRRc1)
begin
Rc_out=R_sin1+RRc1;
end
//***********************************************************
wire[28:
0]R_cossubsin;
mult18_11mult18_11B(
.dataa(Ib_in),
.datab(cossubsin),
.result(R_cossubsin));
reg[30:
0]R_Ia;
always@(Ia_in)
begin
if(Ia_in[17]==1'b1)
begin
R_Ia={4'hf,~{~Ia_in[17:
0]+18'b1,9'b0}+27'b1};
end
else
begin
R_Ia={4'b0,Ia_in[17:
0],9'b0};
end
end
wire[30:
0]R_cossubsin1={R_cossubsin[28],R_cossubsin[28],R_cossubsin[28:
0]};
reg[30:
0]RIc;
always@(R_IaorR_cossubsin1)
begin
RIc=R_Ia+R_cossubsin1;
end
wire[31:
0]RIc1={RIc[30],RIc[30:
0]};
always@(R_sin1orRIc1)
begin
Ic_out=R_sin1+RIc1;
end
//*****************************************************************************
*************
//*****************************************************************************
*************
reg[30:
0]RRd;
always@(R_RaorR_cosaddsin1)
begin
RRd=R_Ra-R_cosaddsin1;
end
wire[31:
0]RRd1={RRd[30],RRd[30:
0]};
always@(R_sin1orRRd1)
begin
Rd_out=RRd1-R_sin1;
end
//***********************************************************
reg[30:
0]RId;
always@(R_IaorR_cossubsin1)
begin
RId=R_Ia-R_cossubsin1;
end
wire[31:
0]RId1={RId[30],RId[30:
0]};
always@(R_sin1orRId1)
begin
Id_out=RId1-R_sin1;
end
endmodule
(8)FFT.v
moduleFFT(clk,
rst_n,
data_in,
data_in_ready,
data_out_R,
data_out_I,
data_out_ready
);
//************************************************************************
inputclk,rst_n;
input[15:
0]data_in;
inputdata_in_ready;
output[31:
0]data_out_R,data_out_I;
outputdata_out_ready;
reg[31:
0]data_out_R,data_out_I;
regworking;
regdata_out_ready_reg;
wireworking_flag=working||data_in_ready;
wiredata_out_ready=data_out_ready_reg;
//DatacollectProcess*****************************************************
reg[2:
0]collect_cnt;
always@(posedgeclkornegedgerst_n)
if(!
rst_n)
begin
collect_cnt<=3'd0;
end
elseif(working_flag==1'b0)
begin
collect_cnt<=3'd0;
end
else
begin
collect_cnt<=collect_cnt+3'b1;
end
reg[15:
0]x0_reg0;
reg[15:
0]x0_reg1;
reg[15:
0]x0_reg2;
reg[15:
0]x0_reg3;
reg[15:
0]x0_regn;
always@(posedgeclkornegedgerst_n)
if(!
rst_n)
begin
x0_reg0<=16'b0;
x0_reg1<=16'b0;
x0_reg2<=16'b0;
x0_reg3<=16'b0;
x0_regn<=16'b0;
end
elseif(working_flag==1'b1)
begin
case(collect_cnt)
3'd0:
x0_reg0<=data_in;
3'd1:
x0_reg1<=data_in;
3'd2:
x0_reg2<=data_in;
3'd3:
x0_reg3<=data_in;
default:
x0_regn<=data_in;
endcase
end
//*********************************************************************
//Level1
reg[16:
0]x1_reg0;
reg[16:
0]x1_reg1;
reg[16:
0]x1_reg2;
reg[16:
0]x1_reg3;
reg[16:
0]x1_reg4;
reg[16:
0]x1_reg5;
reg[16:
0]x1_reg6;
reg[16:
0]x1_reg7;
reg[15:
0]x0add_a,x0add_b;
wire[16:
0]x0add_out;
add16add16(.a(x0add_a),.b(x0add_b),.out(x0add_out));
reg[15:
0]x0sub_a,x0sub_b;
wire[16:
0]x0sub_out;
sub16sub16(.a(x0sub_a),.b(x0sub_b),.out(x0sub_out));
always@(collect_cntorx0_reg0orx0_reg1orx0_reg2orx0_reg3orx0_regn)
begin
case(collect_cnt)
3'd5:
begin
x0add_a<=x0_reg0;
x0add_b<=x0_regn;
x0sub_a<=x0_reg0;
x0sub_b<=x0_regn;
end
3'd6:
begin
x0add_a<=x0_reg1;
x0add_b<=x0_regn;
x0sub_a<=x0_reg1;
x0sub_b<=x0_regn;
end
3'd7:
begin
x0add_a<=x0_reg2;
x0add_b<=x0_regn;
x0sub_a<=x0_reg2;
x0sub_b<=x0_regn;
end
3'd0:
begin
x0add_a<=x0_reg3;
x0add_b<=x0_regn;
x0sub_a<=x0_reg3;
x0sub_b<=x0_regn;
end
default:
begin
x0add_a<=16'b0;
x0add_b<=16'b0;
x0sub_a<=16'b0;
x0sub_b<=16'b0;
x0add_a<=16'b0;
x0add_b<=16'b0;
x0sub_a<=16'b0;
x0sub_b<=16'b0;
end
endcase
end
always@(posedgeclkornegedgerst_n)
if(!
rst_n)
begin
x1_reg0<=17'b0;
x1_reg1<=17'b0;
x1_reg2<=17'b0;
x1_reg3<=17'b0;
x1_reg4<=17'b0;
x1_reg5<=17'b0;
x1_reg6<=17'b0;
x1_reg7<=17'b0;
end
else
begin
case(collect_cnt)
3'd5:
begin
x1_reg0<=x0add_out;
x1_reg4<=x0sub_out;
end
3'd6:
begin
x1_reg1<=x0add_out;
x1_reg5<=x0sub_out;
end
3'd7:
begin
x1_reg2<=x0add_out;
x1_reg6<=x0sub_out;
end
3'd0:
begin
x1_reg3<=x0add_out;
x1_reg7<=x0sub_out;
end
default:
;
endcase
end
//************************************************************************
//Level2
reg[17:
0]x2_reg0;
reg[17:
0]x2_reg1;
reg[17:
0]x2_reg2;
reg[17:
0]x2_reg3;
reg[17:
0]x2_reg4_R,x2_reg4_I;
reg[17:
0]x2_reg5_R,x2_reg5_I;
reg[17:
0]x2_reg6_R,x2_reg6_I;
reg[17:
0]x2_reg7_R,x2_reg7_I;
reg[16:
0]x1add_a,x1add_b;
wire[17:
0]x1add_out;
add17add17(.a(x1add_a),.b(x1add_b),.out(x1add_out));
reg[16:
0]x1sub_a,x1sub_b;
wire[17:
0]x1sub_out;
sub17sub17(.a(x1sub_a),.b(x1sub_b),.out(x1sub_out));
reg[16:
0]x1addw2_a,x1addw2_b;
wire[17:
0]x1addw2_Rout,x1addw2_Iout;
addw2_17
addw2_17(.a(x1addw2_a),.b(x1addw2_b),.Rout(x1addw2_Rout),.Iout(x1addw2_Iout));
reg[16:
0]x1subw2_a,x1subw2_b;
wire[17:
0]x1subw2_Rout,x1subw2_Iout;
subw2_17subw2_17(.a(x1subw2_a),.b(x1subw2_b),.Rout(x1subw2_Rout),.Iout(x1subw2_Iout));
always@(collect_cntorx1_reg0orx1_reg1orx1_reg2orx1_reg3orx1_reg4orx1_reg5or
x1_reg
 升级会员
升级会员 