spss的数据分析报告范例Word格式文档下载.docx
《spss的数据分析报告范例Word格式文档下载.docx》由会员分享,可在线阅读,更多相关《spss的数据分析报告范例Word格式文档下载.docx(17页珍藏版)》请在冰豆网上搜索。
79
22.0
69.6
比较好
91.6
好
24
6.7
98.3
非常好
6
1.7
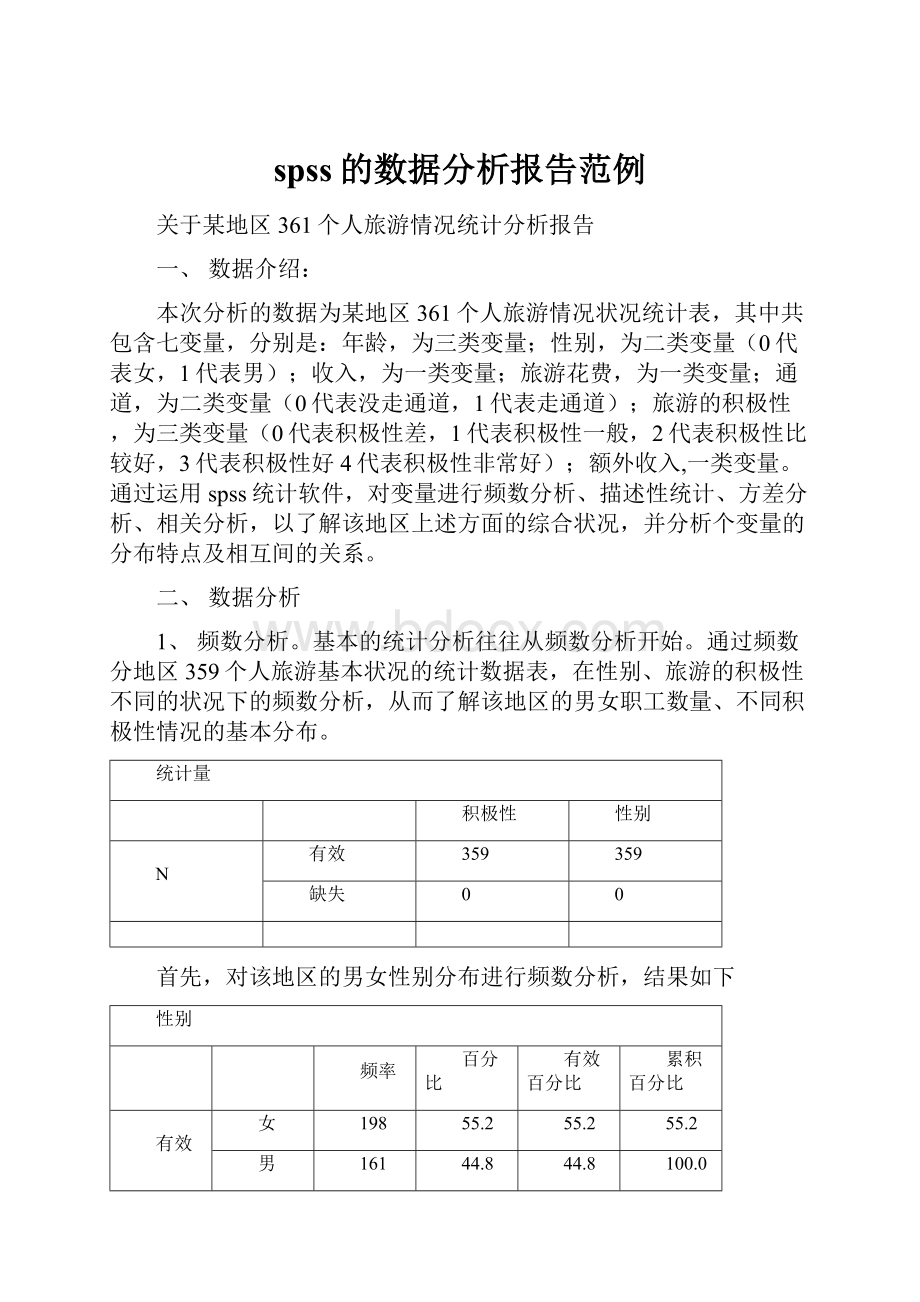
其次对原有数据中的积极性进行频数分析,结果如下表:
其次对原有数据中的是否进通道进行频数分析,结果如下表:
Statistics
通道
Valid
Missing
Frequency
Percent
ValidPercent
CumulativePercent
没走通道
293
81.6
66
18.4
Total
这说明,在该地区被调查的359个人中,有没走通道的占81.6%,占绝大多数。
上表及其直方图说明,被调查的359个人中,对与旅游积极性差的组频数最高的,为171人数的47.6%,其次为积极性一般和比较好的,占比例都为22.0%,积性为好的和非常好的比例比较低,分别为24人和6人,占总体的比例为6.7%和1.7%。
2、描述统计分析。
再通过简单的频数统计分析了解了职工在性别和受教育水平上的总体分布状况后,我们还需要对数据中的其他变量特征有更为精确的认识,这就需要通过计算基本描述统计的方法来实现。
下面就对各个变量进行描述统计分析,得到它们的均值、标准差、片度峰度等数据,以进一步把我数据的集中趋势和离散趋势。
描述统计量
极小值
极大值
均值
标准差
方差
偏度
峰度
标准误
收入
7.426
6250.000
1032.93021
762.523942
581442.762
1.790
.129
6.869
.257
旅游花费
21
1006
116.41
130.716
17086.704
3.145
13.401
有效的N(列表状态)
如表所示,以起始工资为例读取分析结果,359个人中收入最小值为7.426¥,最大值为6250.00000¥,平均1032.9302¥,标准差为762.5239¥
偏度系数和峰度系数分别为1.790和6.869。
其他数据依此读取,则该表表明该地区旅游花费的详细分布状况。
3、探索性数据分析
(1)交叉分析。
通过频数分析能够掌握单个变量的数据分布情况,但是在实际分析中,不仅要了解单个变量的分布特征,还要分析多个变量不同取值下的分布,掌握多个变量的联合分布特征,进而分析变量之间的相互影响和关系。
就本数据而言,需要了解现工资与性别、年龄、受教育水平、起始工资、本单位工作经历、以前工作经历、职务等级的交叉分析。
现以现工资与职务等级的列联表分析为例,读取数据(下面数据分析表为截取的一部分):
Count
性别*积极性交叉制表
计数
96
47
41
12
2
75
32
38
4
上联表及BarChart涉及两个变量,即性别与积极性的二维交叉,反映了在不同的性别对于旅游积极性分布情况。
上表中,性别成为行向量,积极性列向量。
(2)性别与收入的探索性分析
CaseProcessingSummary
Cases
100.0%
.0%
Descriptives
Statistic
Std.Error
Mean
1005.28562
49.514796
95%ConfidenceIntervalforMean
LowerBound
907.63853
UpperBound
1102.93272
5%TrimmedMean
957.92011
Median
937.50000
Variance
485439.577
Std.Deviation
696.734940
Minimum
Maximum
3125.000
Range
3117.574
InterquartileRange
937.563
Skewness
.896
.173
Kurtosis
.310
.344
1066.92791
65.993219
936.59779
1197.25802
986.95497
701171.907
837.360082
58.630
6191.370
718.750
2.370
.191
10.166
.380
Stem-and-LeafPlots
收入Stem-and-LeafPlotfor
性别=女
FrequencyStem&
Leaf
13.001.0000000001111
4.001.7777
5.001.88888
.002.
4.002.5555
1.002.6
2.002.88
3.00Extremes(>
=3000)
Stemwidth:
1000.000
Eachleaf:
1case(s)
性别=男
13.001.0000000000011
2.001.77
6.001.888889
6.002.000111
12.00Extremes(>
=2351)
结果分析如下
收入
女男
平均数1005.285621066.92791
均数的95%可信区间(907.63853,1102.93272)(936.59779,1197.25802)
5%的调整均数957.92011986.95497
中位数937.50000937.50000
标准差696.734940837.360082
标准差485439.577701171.907
最小值7.42658.630
最大值3125.0006250.000
极差3117.5746191.370
四分位数间距937.563718.750
偏度系数2.3702.370
峰度系数.31010.166
(3)p-p图分析
Age
结果分析
年龄在正态p-p图的散点近似成一条直线,无趋势正态p-p图的散点均匀分布在直线y=0的上下,故可认为本资料服从正态分布
4、相关分析。
相关分析是分析客观事物之间关系的数量分析法,明确客观事
之间有怎样的关系对理解和运用相关分析是极其重要的。
函数关系是指两事物之间的一种一一对应的关系,即当一个变量X取一定值时,另一个变量函数Y可以根据确定的函数取一定的值。
另一种普遍存在的关系是统计关系。
统计关系是指两事物之间的一种非一一对应的关系,即当一个变量X取一定值时,另一个变量Y无法根据确定的函数取一定的值。
统计关系可分为线性关系和非线性关系。
事物之间的函数关系比较容易分析和测度,而事物之间的统计关系却不像函数关系那样直接,但确实普遍存在,并且有的关系强有的关系弱,程度各有差异。
如何测度事物之间的统计关系的强弱是人们关注的问题。
相关分析正是一种简单易行的测度事物之间统计关系的有效工具。
Correlations
额外收入
PearsonCorrelation
1
.140**
.853**
Sig.(2-tailed)
.008
.000
.183**
**.Correlationissignificantatthe0.01level(2-tailed).
上表是对本次分析数据中,旅游花费、收入、、额外收入的相关分析,表中相关系数旁边有两个星号(**)的,表示显著性水平为0.01时,仍拒绝原假设。
一个星号(*)表示显著性水平为0.05是仍拒绝原假设。
先以现旅游花费这一变量与其他变量的相关性为例分析,由上表可知,旅游花费与额外收入的相关性最大,
5.回归分析
有相关性分析可得收入,旅游花费呈线性相关,因此作回归分析
VariablesEntered/Removedb
Model
VariablesEntered
VariablesRemoved
Method
收入a
.
Enter
a.Allrequestedvariablesentered.
b.DependentVariable:
旅游花费
ModelSummaryb
R
RSquare
AdjustedRSquare
Std.ErroroftheEstimate
.140a
.020
.017
129.604
a.Predictors:
(Constant),收入
ANOVAb
SumofSquares
df
MeanSquare
F
Sig.
Regression
120443.809
7.170
.008a
Residual
5996596.239
357
16797.188
6117040.048
358
Coefficientsa
UnstandardizedCoefficients
StandardizedCoefficients
t
B
Beta
(Constant)
91.563
11.528
7.943
.024
.009
.140
2.678
a.DependentVariable:
ResidualsStatisticsa
PredictedValue
91.74
241.90
18.342
Std.PredictedValue
-1.345
6.842
1.000
StandardErrorofPredictedValue
6.840
47.362
9.048
3.426
AdjustedPredictedValue
92.09
271.79
116.53
19.018
-193.904
891.785
129.423
Std.Residual
-1.496
6.881
.999
Stud.Residual
-1.607
6.891
1.002
DeletedResidual
-223.789
894.316
-.117
130.229
Stud.DeletedResidual
-1.611
7.390
.004
1.025
Mahal.Distance
46.811
.997
2.955
Cook'
sDistance
.199
.003
.015
CenteredLeverageValue
.131
Charts
由上图可知回归方程:
y=91.563+0.024(x1),(P(Sig=0.000)<
0.01)
即旅游花费=91.563+0.024*收入(p<
6单样本T检验
首先对现工资的分布做正态性检验,结果如下:
由上图可知,现工资的分布可近似看作符合正态分布,现推断现工资变量的平均值是否为$3,000,0,因此可采取单样本t检验来进行分析。
分析如下:
One-SampleStatistics
单个样本统计量
均值的标准误
40.244474
单个样本检验
检验值=0
Sig.(双侧)
均值差值
差分的95%置信区间
下限
上限
25.666
1032.930214
953.78493
1112.07550
由One-SampleStatistics可知,359个被调查的人中收入平均值1032.93021
,标准差为762.523942,均值标准误差为40.244474。
图表One-SampleTest中,第二列是t统计量的观测值为25.666;
第三列是自由度为358(n-1);
第四列是t统计量观测值的双尾概率值;
第五列是样本均值和检验值的差;
第六列和第七列是总体均值与原假设值差的95%的置信区间为(953.78493,1112.07550)。
该问题的t值等于25.666对应的临界置信水平为0,远远小于设置的0.05,因此拒绝原假设,表明该地区被调查的359名人中收入与1032.93021
存在显著差异。
7,独立样本t检验
T-Test
GroupStatistics
Std.ErrorMean
126.09
149.533
10.627
104.51
102.187
8.053
IndependentSamplesTest
Levene'
sTestforEqualityofVariances
t-testforEqualityofMeans
95%ConfidenceIntervaloftheDifference
MeanDifference
Std.ErrorDifference
Lower
Upper
Equalvariancesassumed
6.302
.013
1.559
.120
21.580
13.844
-5.647
48.806
Equalvariancesnotassumed
1.618
347.241
.106
13.334
-4.645
47.805
得到两组的均数(mean)分别为198和161
独立样本t检验,取的t值1.559与Sig为0.120p>
0..05
旅游花费不成显著性差异,由图中可知旅行的旅游花费较高。
学号:
姓名:
班级:
 升级会员
升级会员 