数学建模短学期7Word格式.docx
《数学建模短学期7Word格式.docx》由会员分享,可在线阅读,更多相关《数学建模短学期7Word格式.docx(23页珍藏版)》请在冰豆网上搜索。
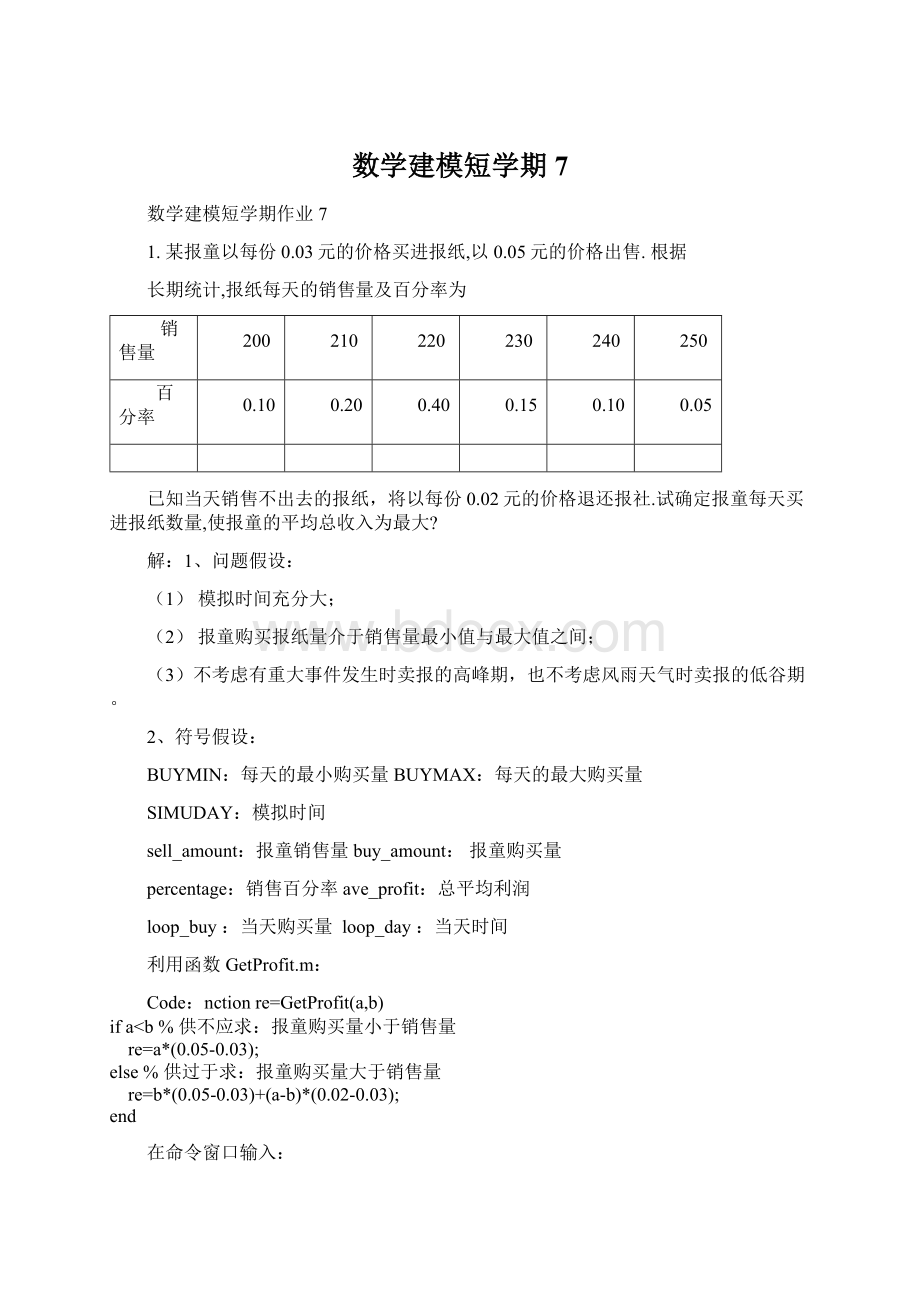
forloop_buy=BUYMIN:
BUYMAX
sum_profit=0;
forloop_day=1:
SIMUDAY
index=find(percentage>
=rand);
%产生随机数,用于决定当天的销售量
sum_profit=sum_profit+GetProfit(loop_buy,sell_amount(index
(1)));
end
buy_amount=[buy_amount,loop_buy];
%循环嵌套
ave_profit=[ave_profit,sum_profit/SIMUDAY];
%循环嵌套
buy_amount
(1)=[];
%第一个元素置空
ave_profit
(1)=[];
[val,id]=max(ave_profit)
%显示最大平均收入val
buy=buy_amount(id)
%显示在平均收入最大情况下的每天的购买量buy
xlabel='
每天的购买量'
;
ylabel='
平均利润'
plot(buy_amount,ave_profit,'
*:
'
);
得:
该结果说明当报童每天买进报纸数量为220,报童的平均总收入为最大,且最大为4.2801。
毕
2、混凝土的抗压强度随养护时间的延长而增加,现将一批混凝土作成12个试块,记录了养护日期x(日)及抗压强度y(kg/cm2)的数据:
养护时间x
2
3
4
5
7
9
12
14
17
21
28
56
抗压强度y
35
42
47
53
59
65
68
73
76
82
86
99
试求
型回归方程.
利用matlab拟合工具箱,可找出x与y的函数关系:
x=0.2995*exp(0.05278*y)
(1)
曲线和散点图基本拟合,转化
(1)式:
y=22.843+18.947*lnx
3、在研究化学动力学反应过程中,建立了一个反应速度和反应物含量的数学模型,形式为
其中
是未知参数,
是三种反应物(氢,n戊烷,异构戊烷)的含量,y是反应速度.今测得一组数据如下表,试由此确定参数
,并给出置信区间.其中
的参考值为(1,0.05,0.02,0.1,2).
序号
反应速度y
氢x1
n戊烷x2
异构戊烷x3
1
8.55
470
300
10
3.79
285
80
4.82
120
0.02
2.75
6
14.39
100
190
2.54
8
4.35
13.00
54
8.50
11
11.32
13
3.13
code:
clc;
x1=[470285470470470100100470100100100285285]'
x2=[3008030080801908019030030080300190]'
x3=[1010120120101065655412012010120]'
x=[x1x2x3];
y=[8.553.794.820.022.7514.392.544.3513.008.500.0511.323.13]'
f=@(beta,x)(beta
(1).*x(:
2)-(1/beta(5)).*x(:
3)).*((1+beta
(2).*x(:
1)+beta(3).*x(:
2)+beta(4).*x(:
3))).^(-1);
beta0=[10.050.020.12]'
opt=optimset('
TolFun'
1e-3,'
TolX'
1e-3);
[beta,bint]=nlinfit(x,y,f,beta0,opt)
运行:
即得到beta的拟合值及95%的置信区间
4、某人记录了21天中每天使用空调器的时间和使用烘干器的次数,并监测电表以计算出每天的耗电量,数据见下表,试研究耗电量(KWH)与空调器使用小时数(AC)和烘干器使用次数(DRYER)之间的关系,建立并检验回归模型,诊断是否有异常点.
序号1234567891011
KWH3563661794799366948278
AC1.54.55.02.08.56.013.58.012.57.56.5
DRYER12203311123
序号12131415161718192021
KWH65777562854357336533
AC8.07.58.07.512.06.02.55.07.56.0
DRYER1221103010
由于空调、烘干器的工功率为定值,故耗电量应与空调器使用小时数(AC)和烘干器(DRYER)之间的关系应符合线性关系,则做如下假设:
设每日耗电量为y,空调器使用小时数(AC)为
,烘干器使用次数(DRYER)为
则:
code:
y=[356366179479936694827865777562854357336533]'
x1=[1.54.5528.5613.5812.57.56.587.587.51262.557.56]'
x2=[122033111231221103010]'
x=[ones(21,1)x1x2];
[b,bint,r,rint,stats]=regress(y,x)
rcoplot(r,rint)
s=(r'
*r)^0.5
运行后结果:
由此图可看出异常点为最后一点,则删除最后一点重新做线性回归:
y=[3563661794799366948278657775628543573365]'
x1=[1.54.5528.5613.5812.57.56.587.587.51262.557.5]'
x2=[12203311123122110301]'
x=[ones(20,1)x1x2];
去除异样点之前,线性模型为
;
剩余标准差为:
s=16.6964;
去除异样点之后,线性模型为
s=14.3300;
由此可明显看出去除异常点后的回归模型更为准确。
5、Logistic增长曲线模型和Gompertz增长曲线模型是计量经济学等学科中的两个常用模型,可以用来拟合销售量的增长趋势.记Logistic增长曲线模型为
,
记Gompertz增长曲线模型为
.这两个模型中L的经济学意义都是销售量的上限,下表中给出的是某地区高压锅销售量(单位:
万台),
表7—4某地区高压锅销量(单位:
万台)
年份
t
y
1981
0
43.65
1988
1238.75
1982
1
109.86
1989
1560.00
1983
2
187.21
1990
1834.29
1984
3
312.67
1991
2199.00
1985
4
496.58
1992
2438.89
1986
5
707.65
1993
2737.71
1987
960.25
1994
为给出此两模型的拟合结果,请考虑以下问题:
(1)两曲线模型是一个可线性化的模型吗?
如果给定L=3000,是否是一个可线性化的
模型,如果是,试用线性化模型给出参数a,b和k的估计值;
(2)利用
(1)中所得到的a和k的估计值和L=3000作为Logistic模型的拟合初值,对
Logistic模型做非线性回归;
(3)取初值
,拟合Gompertz模型,并与Logistic模型的结果进行比较.
(1)由图表,假设y和t满足线性关系,所以建立线性模型,设y-at+b
利用最小二乘法确定a,b的具体值,并根据a,b的值拟合高压锅的销售情况,与原数据进行比较。
MATLAB的程序实现如下:
y=[43.65109.86187.21312.67496.58707.65960.251238.751560.001824.292199.002438.892737.71];
t=0:
12;
p=polyfit(t,y,1);
yy=polyval(p,t,1)
plot(t,y,'
*'
t,yy)
画出原数据与拟合曲线:
线性模型
的误差分析
预测的标准误差为:
.=157.2915
模型y=ax+b分析
从图形及标准误差可以看出,线性模型虽然简单,但误差太大。
并且当
时
,而高压锅销售量是有限的,也就是说高压锅的销售量是一个有限的数,不可能是一个无限大的。
所以,用线性模型不能完全反映高压锅的销售情况。
必须寻找一个更好的模型去分析高压锅的销售情况。
(2)用Matlab对Logistic模型做非线性回归
Code:
L=3000;
y1=log(L./y-1);
p=polyfit(t,y1,1);
k=-p
(1);
a=exp(p
(2));
yy=L./(1+a*exp(-k*t));
t,yy);
拟合Logistic模型,画出拟合图形:
(3)用Matlab拟合Gompertz模型
Matlab程序如下
y1=log(log(y/L));
a=polyfit(t,y1,1);
b=-exp(a
(2));
k=-a
(1);
yy=L*exp(-b*exp(-k*t));
画出Gompertz模型并与原数据比较:
6、财政收入预测问题:
财政收入与国民收入、工业总产值、农业总产值、总人口、就业人口、固定资产投资等因素有关。
下表列出了1952-1981年的原始数据,试构造预测模型。
年份
国民收入(亿元)
工业总产值(亿元)
农业总产值(亿元)
总人口(万人)
就业人口(万人)
固定资产投资(亿元)
财政收入(亿元)
1952
598
349
461
57482
20729
44
184
1953
586
455
475
58796
21364
89
216
1954
707
520
491
60266
21832
97
248
1955
737
558
529
61465
22328
98
254
1956
825
715
556
62828
23018
150
268
1957
837
798
575
64653
23711
139
286
1958
1028
1235
65994
26600
256
357
1959
1114
1681
509
67207
26173
338
444
1960
1079
1870
66207
25880
380
506
1961
757
1156
434
65859
25590
138
271
1962
677
964
67295
25110
66
1963
779
1046
514
69172
26640
85
266
1964
943
1250
584
70499
27736
129
323
1965
1152
1581
632
72538
28670
175
393
1966
1322
1911
687
74542
29805
212
466
1967
1249
1647
697
76368
30814
156
352
1968
1187
1565
680
78534
31915
127
303
1969
1372
2101
688
80671
33225
207
447
1970
1638
2747
767
82992
34432
312
564
1971
1780
3156
790
85229
35620
355
638
1972
1833
3365
789
87177
35854
354
658
1973
1978
3684
855
89211
36652
374
691
1974
3696
891
90859
37369
655
1975
2121
4254
932
92421
38168
462
692
1976
2052
4309
955
93717
38834
443
657
1977
2189
4925
971
94974
39377
454
723
2475
5590
1058
96259
39856
550
922
1979
2702
6065
1150
97542
40581
890
1980
2791
6592
1194
98705
41896
568
826
1981
2927
6862
1273
100072
73280
496
810
财政收入:
y;
国民收入:
x1;
工业总产值:
x2;
农业总产值:
x3;
总人口:
x4;
就业人口:
x5;
固定资产投资:
x6;
回归系数:
β0、β1、β2、β3、β4、β5、β6;
随即误差:
ε
由表格中的数据关系得出y与6因素具有以下关系:
y=β0+β1x1+β2x2+β3x3+β4x4+β5x5+β6x6+ε.将表格中数据存入Excel中:
book1.xlsx。
>
A=xlsread('
book1.xlsx'
x=[ones(30,1)A(:
2:
7)];
y=A(:
8);
[b,bint,r,rint,starts]=regress(y,x)
分析得:
由于第27和第29项是异常点,所以将其剔除。
于是,将剩下的数据进行逐步回归分析
A=xlsread('
x=A(:
7);
stepwise(x,y)
从图中分析得出,去掉x2、x4、x6,剩下x1、x3、x5(即国民收入、农业总产值、就业人口),也就是在X中的x1、x2、x3。
再进行多元线性回归分析:
X=[ones(28,1)A(:
2)A(:
4)A(:
6)];
[b,bint,r,rint,stats]=regress(y,X);
则点估计及估计区间为:
b=
267.0695
0.5963
-0.7021
-0.0043
bint=
219.0182315.1208
0.53660.6560
-0.8861-0.5180
-0.0062-0.0024
r=
-25.9119
25.8326
-1.0529
15.8930
-0.6267
26.5690
12.3779
-16.2460
19.7153
-31.5560
-7.9812
11.0557
24.1712
7.3031
22.4789
-36.5851
-55.7652
-10.7718
8.3220
18.9577
7.6684
4.0103
-12.5430
-19.6119
5.5755
3.4750
-4.5221
9.7683
rint=
-67.796515.9728
-15.625967.2911
-44.775242.6694
-26.681358.4673
-43.941342.6879
-14.691867.8298
-31.682256.4380
-56.313623.8215
-13.638953.0695
-71.16798.0558
-51.108535.1461
-32.280854.3922
-18.553866.8963
-37.185351.7914
-21.076766.0345
-77.72384.5535
-92.4110-19.1194
-55.085833.5423
-36.000452.6444
-24.054761.9701
-35.218750.5555
-39.102947.1235
-55.794530.7084
-61.727322.5035
-37.171348.3222
-39.174746.1247
-40.365731.3215
-3.217922.7544
stats=
0.9901800.19050466.5820
由于β0,即常数项的区间范围较大,于是将其剔除,于是,将参数估计值代入模型得到,
y=0.5963x1-0.7021x3-0.0043x5.
使用rstool命令得到交互式画面:
rstool(X(:
4),y,'
linear'
)
图中的x1、x2、x3分别是国民收入、农业总产值、就业人口,用的数据是1965年的。
于是,财政收入的预测函数为y=0.5963x1-0.7021x3-0.0043x5,也可从上图中输入x1、x2、x3的值得出下一年的预测值。
 升级会员
升级会员 