大数据集群配置过程hadoop篇文档格式.docx
《大数据集群配置过程hadoop篇文档格式.docx》由会员分享,可在线阅读,更多相关《大数据集群配置过程hadoop篇文档格式.docx(19页珍藏版)》请在冰豆网上搜索。
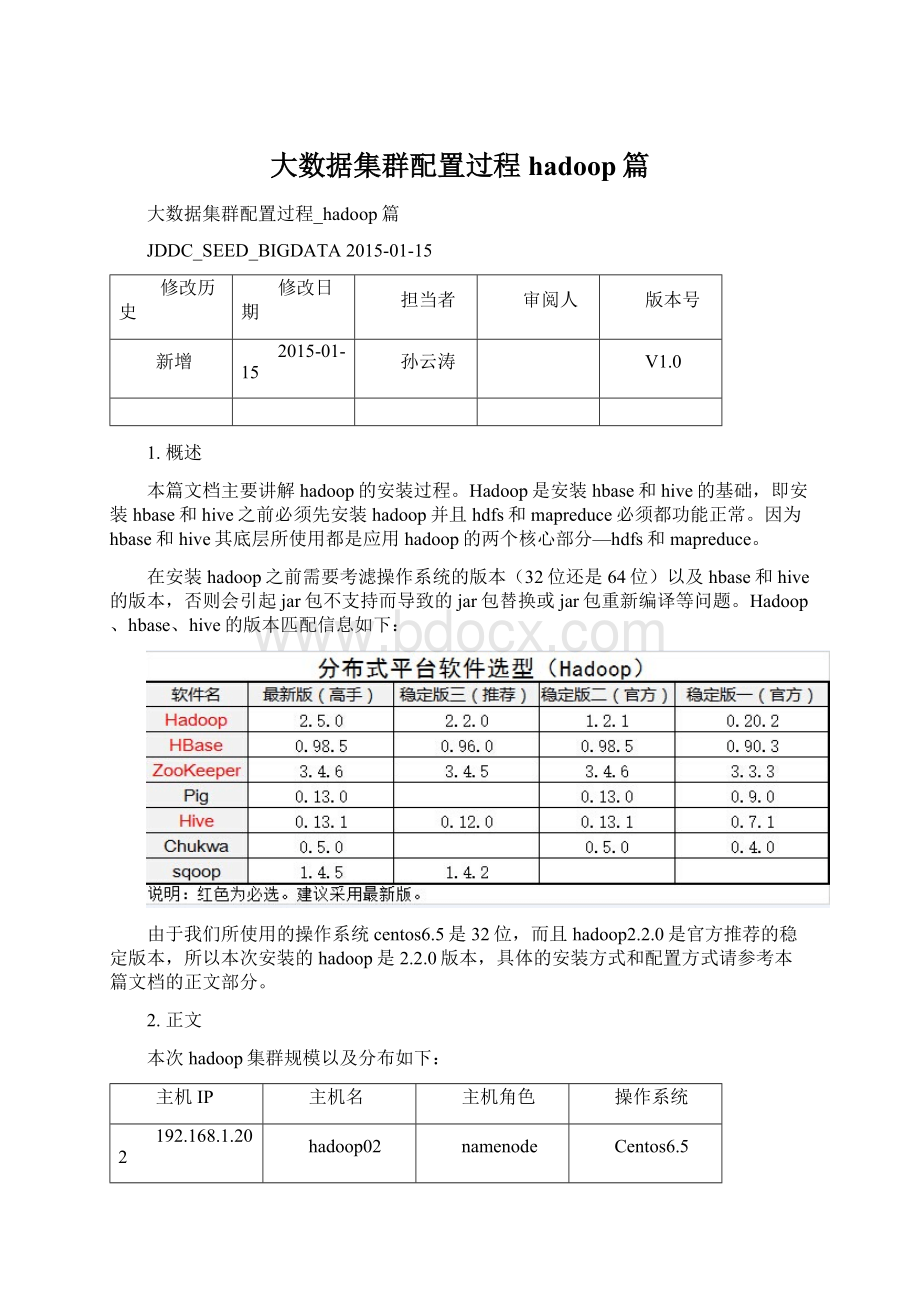
Centos6.5
192.168.1.201
hadoop01
datanode
192.168.1.203
hadoop03
192.168.1.204
hadoop04
注意:
datanode的数量要求是奇数,否则后继安装hbase时会报错。
2.1操作系统安装
每台主机都安装centos6.5,安装时可以用desktop方式进行安装,但是安装完成之后需要把启动模式改命令行模式,然后重新启动每台主机。
修改启动模式需要修改/etc/inittab这个文件
把id后面的数字改成3
2.2配置网络
Hadoop集群中的第个主机节点需要配置成静态IP,配置IP时需要修改/etc/sysconfig/network-scripts/ifcfg-eth0这个文件,修改内容如下(以namenode的文件为例)
修改完成之后,需要运行servicenetworkrestart这个命令。
其它各个datanode主机也需要按同样的方式对网络进行配置,三个datanode的IP分别为:
192.168.1.201;
192.168.1.203;
192.168.1.204。
网络配置完成之后要通过ping命令确认各主机之间是否能访问。
2.3修改主机名
由于hadoop集群,特别是hbase集群在各节点在通信过程中直接使用IP会出现问题,所以集群中每个节点主机要配置一个固定的主机名。
1)修改/etc/sysconfig/network这个文件
Namenode节点:
Datanode节点1:
Datanode节点2:
Datanode节点3:
2)修改/etc/hosts文件
注意默认127.0.0.1localhost后面会有其它内容,建意删掉,否则hadoop集群能正常启动运行,但使用hbase时会出现访问拒绝的情况。
在namenode节点上修改完成/ect/hosts这个文件之后可以通过scp命令复制到各个datanode节点上。
Scp命令示例:
scp/etc/hosts192.168.1.201:
/etc
scp/etc/hosts192.168.1.203:
scp/etc/hosts192.168.1.204:
2.4配置ssh无密码登陆
1)在namenode节点上执行命令ssh-keygen-trsa之后一路回车,查看刚生成的无密码钥对:
cd.ssh后执行ll
2、把id_rsa.pub追加到授权的key里面去。
执行命令cat~/.ssh/id_rsa.pub>
>
~/.ssh/authorized_keys
3、修改权限:
执行chmod600~/.ssh/authorized_keys
4、确保cat/etc/ssh/sshd_config中存在如下内容
RSAAuthenticationyes
PubkeyAuthenticationyes
AuthorizedKeysFile.ssh/authorized_keys
如需修改,则在修改后执行重启SSH服务命令使其生效:
servicesshdrestart
5、将公钥复制到所有的datanode节点上
scp~/.ssh/id_rsa.pub192.168.1.201:
~/
scp~/.ssh/id_rsa.pub192.168.1.203:
scp~/.ssh/id_rsa.pub192.168.1.204:
通过scp进行远程复制过程中会要求输入各节点的主机登录密码。
6、在各datanode节点上创建.ssh文件夹:
mkdir~/.ssh然后执行chmod700~/.ssh(若文件夹以存在则不需要创建)
7、在各datanode节点上,将公钥追加到授权文件authorized_keys执行命令:
cat~/id_rsa.pub>
~/.ssh/authorized_keys然后执行chmod600~/.ssh/authorized_keys
8、在各datanode节点上确保cat/etc/ssh/sshd_config中存在如下内容
9、重新启动各个节点(包括namenode和datanode)
10、各个节点全部重新启动完成之后需要验证一下ssh无密码登录是否成功(在namenode结点上验证)
从上面的截图可以看出在namenode节点通过ssh命令登录其它节点时不再需要输入密码。
如果ssh无密码登录配置完成之后,有哪个节点进行过系统重新安装,需要在namenode节点上,把/root/.ssh/known_hosts这个文件中把重新安装过系统的结点的信息删掉,然后重新通过ssh命令进行连接,否则会报“主机指纹无法识别的”的异常
例如:
hadoop01这个节点系统重新安装过后,当公钥复制完成和授权配完成之后,需要在namenode结点上把/root/.ssh/known_hosts文件中的hadoop01相关的信息删除掉。
2.5安装JDK
安装的JDK需要与操作系统相匹配,例如centos6.5是32位的操作系统,所以安装的JDK也应该是32位的JDK。
本次安装的JDK版本是jdk-8u25-linux-i586.rpm,参考下载地址是
JDK下载之后,进行安装,各个节点都需要安装,而且安装路径和/etc/profile中的配置每个节点要求一至(/etc/profile可以在namenode节点进行配置,然后通过scp命令向其它节点复制)
JDK安装目录
JDK安装包放到指定目录下,由于是RPM包所以通过rpm–ivh命令进行安装
rpm-ivhjdk-8u25-linux-i586.rpm
rpm命令运行完成之后在/usr/java目录下会生成jdk1.8.0_25这个目录
修改/etc/profile这个文件
新增内容如下:
exportJAVA_HOME=/usr/java/jdk1.8.0_25/
exportJRE_HOME=/usr/java/jdk1.8.0_25/jre
exportCLASS_PATH=.:
$CLASS_PATH:
$JAVA_HOME/lib:
$JRE_HOME/lib
exportPATH=$PATH:
$JAVA_HOME/bin:
$JRE_HOME/bin
profile修改之后,需要重启机器,重启之后通过java–version验证JDK是否安装成功
2.6关闭防火墙并停止一些服务
如果不关闭防火墙并停止一些服务在运行mapreduce时会出现“访问拒绝”错误。
注意,集群中每个节点(包括namenode和各个datanode)的防火墙都需要关闭。
在各个节点中执行以命令:
vim/etc/sysconfig/selinux
SELINUX=enforcing
↓
SELINUX=disabled
forSERVICESinabrtdacpidavahi-daemoncpuspeedhaldaemonmdmonitormessagebusudev-post;
dochkconfig${SERVICES}off;
done
2.7安装以及配置hadoop
1)创建hadoop用户以及相关的工作目录
使用root登陆所有机器后,所有的机器都创建hadoop用户
useraddhadoop
passwdhadoop
此时在/home/下就会生成一个hadoop目录,目录路径为/home/hadoop
创建相关的目录
定义需要数据及目录的存放路径
定义代码及工具存放的路径
mkdir-p/home/hadoop/source
定义数据节点存放的路径到跟目录下的hadoop文件夹,这里是数据节点存放目录需要有足够的空间存放
mkdir-p/hadoop/hdfs
mkdir-p/hadoop/tmp
mkdir-p/hadoop/log
设置可写权限
chmod-R755/hadoop
2)安装配置hadoop
声明:
Hadoop的安装与配置可以先在namenode节点上进行,然后把配置完成之后hadoop包和profile文件用scp命令同步到各个datanode节点上,而且各个datanode上不需要对配置好的hadoop包和profile进行任何修改。
本次hadoop使用的安装包:
hadoop-2.2.0.tar.gz,参考下载地址http:
//ftp.riken.jp/net/apache/hadoop/common/
下载之后放置在/home/hadoop/source下,并过通过tar命令进行解压
tar–zxvfhadoop-2.2.0.tar.gz
解压之后创建联接(联接需要在各个节点上独立创建)
cd/home/hadoop
ln-s/home/hadoop/source/hadoop-2.2.0/./hadoop
在/etc/profile文件中追加一些内容
exportHADOOP_HOME=/home/hadoop/hadoop
exportHADOOP_COMMON_HOME=$HADOOP_HOME
exportHADOOP_HDFS_HOME=$HADOOP_HOME
exportHADOOP_MAPRED_HOME=$HADOOP_HOME
exportHADOOP_YARN_HOME=$HADOOP_HOME
exportHADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
$HADOOP_HOME/bin:
$HADOOP_HOME/sbin:
$HADOOP_HOME/lib
exportHADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
进入到/home/hadoop/source/hadoop-2.2.0/etc/hadoop目录下对下面几个文件进行修改
core-site.xml文件中在<
configuration>
<
/configuration>
内追加以下内容:
property>
name>
hadoop.tmp.dir<
/name>
value>
/hadoop/tmp<
/value>
description>
Abaseforothertemporarydirectories.<
/description>
/property>
fs.default.name<
hdfs:
//hadoop02:
9000<
hadoop.proxyuser.root.hosts<
hadoop02<
hadoop.proxyuser.root.groups<
*<
hdfs-site.xml文件中在<
dfs.replication<
3<
dfs.namenode.name.dir<
file:
/hadoop/hdfs/name<
final>
true<
/final>
dfs.federation.nameservice.id<
ns1<
dfs.namenode.backup.address.ns1<
hadoop02:
50100<
dfs.namenode.backup.http-address.ns1<
50105<
dfs.federation.nameservices<
dfs.namenode.rpc-address.ns1<
dfs.namenode.rpc-address.ns2<
dfs.namenode.http-address.ns1<
23001<
dfs.namenode.http-address.ns2<
13001<
dfs.dataname.data.dir<
/hadoop/hdfs/data<
dfs.namenode.secondary.http-address.ns1<
23002<
dfs.namenode.secondary.http-address.ns2<
23003<
hadoop-env.sh文件中修改以下内容
exportJAVA_HOME=/usr/java/jdk1.8.0_25
注:
这里的JAVA_HOME需要与/etc/profile里的JAVA_HOME配置一样。
yarn-site.xml文件中在<
yarn.resourcemanager.address<
18040<
yarn.resourcemanager.scheduler.address<
18030<
yarn.resourcemanager.webapp.address<
18088<
yarn.resourcemanager.resource-tracker.address<
18025<
yarn.resourcemanager.admin.address<
18141<
yarn.nodemanager.aux-services<
mapreduce.shuffle<
mapred-site.xml文件中在<
mapred.job.tracker<
9001<
mapred.map.java.opts<
-Xmx1024m<
mapred.child.java.opts<
如果没有mapred-site.xml文件,可以根据mapred-site.xml.template复制出一个。
修改slaves文件
这里写的几个主机名都是datanode节点的主机名
上述几个文件修改完成之后,hadoop包和/etc/profile文件通过scp命令复制到各个datanode上
scp-r/home/hadoop/source/hadoop-2.2.0hadoop01:
/home/hadoop/source/
scp-r/home/hadoop/source/hadoop-2.2.0hadoop03:
scp-r/home/hadoop/source/hadoop-2.2.0hadoop04:
scp/etc/profilehadoop01:
/etc/profile
scp/etc/profilehadoop03:
scp/etc/profilehadoop04:
由于/etc/profile进行了修改,各个节点需要重新启动一下。
2.8验证hadoop集群
1)格式化namenode
在namenode节点执行以下命令
hadoopnamenode–format
2)启动hadoop集群
start-all.sh
3)查看进程
jps
在datanode节点执行以下命令
hadoop2.2.0以前的版本进程中还会有nodemanager进程,但2.2.0版本中没有这个进程也不影响hdfs和mapreduce的运行。
4)验证hdfs
hadoopfs-lshdfs:
9000/
5)验证mapreduce
hadoopfs-put/home/hadoop/hadoop/*.txthdfs:
9000/input
cd/home/hadoop/hadoop/share/hadoop/mapreduce
hadoopjarhadoop-mapreduce-examples-2.2.0.jarwordcounthdfs:
9000/inputhdfs:
9000/output
执行hadoopfs-lshdfs:
执行hadoopfs-cathdfs:
9000/output/part-r-00000
出现上述各个截屏中显示的内容,说明hadoop集群已经配置成功。
3.补充说明
3.1hadoop的启动与停止
start-all.sh启动所有的Hadoop守护进程。
包括NameNode、SecondaryNameNode、DataNode、JobTracker、TaskTrack
stop-all.sh停止所有的Hadoop守护进程。
start-dfs.sh启动HadoopHDFS守护进程NameNode、Secondar
 升级会员
升级会员 