质量直方图与排列图法描述Word文件下载.docx
《质量直方图与排列图法描述Word文件下载.docx》由会员分享,可在线阅读,更多相关《质量直方图与排列图法描述Word文件下载.docx(21页珍藏版)》请在冰豆网上搜索。
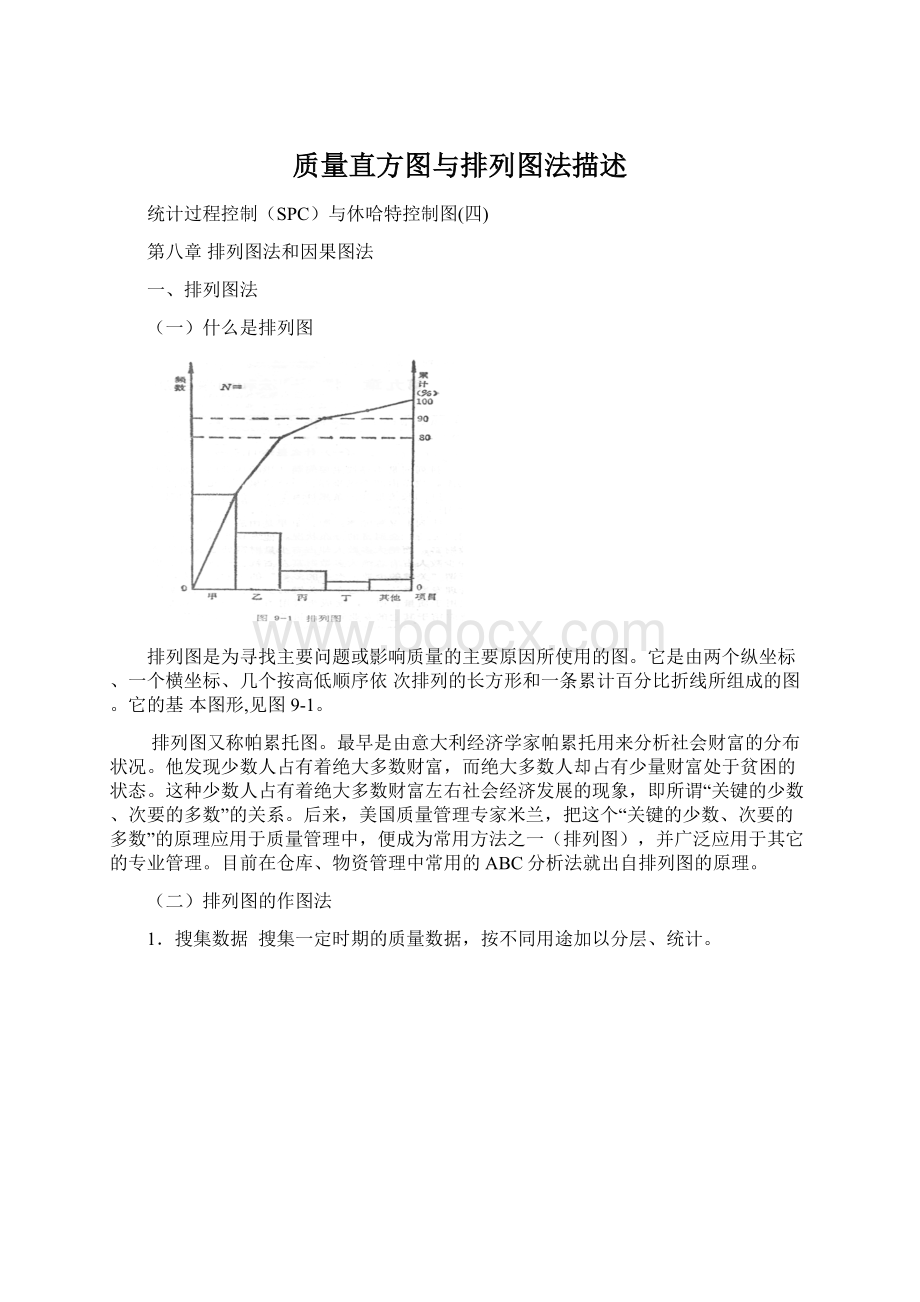
绘制排列图的目的在于从诸多的问题中寻找主要问题并以图形的方法直观地表示出来。
通常把问题分为三类,A类属于主要或关键问题,在累计百分比0~80%左右;
B类属于次要问题,在累计百分比80~90%左右;
C类属于一般问题,在累计百分比90~100%左右。
在实际应用中,切不可机械地按80%来确定主要问题。
它只是根据“关键的少数、次要的多数”的原则,给以一定的划分围而言。
A、B、C三类应结合具体情况来选定。
主要问题项目(A类),可以用划线及“A”表示,如图9-3所示(虚线一定通过累计百分比折线上的某一点);
或用阴影线表示,如图9-2;
或用文字叙述来表示,如图9-4。
在排列图上,一般只分析标注主要问题(A类)即可。
(四)排列图法在应用中注意的事项
1.主要项目以一至二个为宜,过多时,就失去了画排列图找主要问题的意义。
如果出现主要项目过多的情况,就应考虑重新分层排列。
2.“其它”项应放置在最后。
3.图形应完整应该注意避免机械地按80%划分主次问题;
应该注明标题栏以及在图上标注总频数N、各坐标点的累计百分比、各项目的频数、左右纵坐标的名称、计量单位等。
绘制排列图可以通过图形,直观地找到主要问题。
但当问题的项目较少,主次问题已十分明显时,也可以用统计表代替画图。
为了更有效地分析问题和多方面采取措施,往往可以对一组数据采用不同的分层来绘制排列图。
如图9-3和图9-4所示是以某厂1~6月份工伤事故的频次,按事故类别和事故发生的部门,分别绘制的排列图。
三、其它常用的图表
在质量管理活动中,还有一些常用的简易方法。
(一)折线图
折线图常用来表示质量特性数据的波动情况青况,如图9-8。
作图简单,看起来直观。
(二)柱状圄
柱状图常用来表示不同时期或同一期不同情况的对比,如图9-9。
(三)饼分图
饼分图常用来表示一个系统中各部分所占的比率,如图9-10,表示某厂1988年QC小组成员结构的组成。
第九章直方图法
一、
什么是直方图
直方图是通过对数据的加工整理,从而分析和掌握质量数据的分布状况和估算工序不合格频率的一种方法。
将全部数据分成若干组,以组距为底边,以该组距相应的频数为高,按比例而构成若干矩形,即位直方图,其基本形势见图10-1。
为什么要使用直方图呢?
以前我们描述质量情况虽说已经有一级品率、平均尺寸或平均含量等统计数据,但是只有这些统计数据还不完善,不能充分说明问题。
例如,下面两组数据是5次抽测两个班组控制冷却温度的数据:
甲班:
5、5、6、7、7(℃)
乙班:
2、4、6、8、10(℃)
如果计算两组数据的平均值,用
来表示,则
甲=6℃,
乙=6℃。
两班的
是一样的,可是很明显,两班的控制水平是不一样的。
甲班控制得较稳定,集中在5~7℃之间,最大与最小相差2℃。
即极差R甲=7-5=2(℃)。
而乙班的温度波动较大,R乙=10-2=8(℃)。
可以说两班数据的分散程度不一样。
再看另外两组数据:
3、3、4、5、5(℃)
7、7、8、9、9(℃)
这两个班的温度控制都比较稳定R丙=5-3=2℃,R丁=9-7=2℃。
但两班的平均温度不一样,X丙=4℃,X丁=8℃。
可见在分析质量情况时只看平均值或只看分散程度都是片面的,要综合起来看分布。
直方图法就是用以帮助我们分析产品质量的分布状况。
它的用途十分广泛,常用于定期报告质量状况、分析质量分散原因、测量工序能力、估计工序不合格品率等。
二、
直方图的作法
举一个实际例子来说明。
某工厂生产的产品,重量标准要求在1000~1050克之间(1000),为了分析产品的重量分布状况,搜集一段时间生产的产品100个,测定重量得到100个数据,作一直方图。
作直方图有三大步骤:
;
作频数分布表;
画直方图;
进行有关计算。
下面逐步讨论。
(一)
(一)
作频敏分布表
频数就是出现的次数。
将数据按大小顺序分组排列反映各组频数的统计表,称为频数分布表。
频数分布表可以把大量的原始数据综合起来,比较直观、形象的形式表示分布的状况,并为作图提供依据。
具体作法按下述步骤。
1..搜集数据将搜集到的数据填入数据表。
作直方图的数据要大于50个,否则反映分布的误差太大。
本例搜集了100个。
为了简化计算,数据表中每个测量值(x)只列出波动围的数值。
x值如表10-1所示。
表10-1中的数字均缩去1000克,例如43代表的测量值是1043克,34代表的测量值是1034克,......依此类推。
2.计算极差(R)表10-1中,最大值Xmax=48,最小值Xmiu=1,R=Xmax-Xmiu=48-1=47
3.适当分组(k)组数的确定要适当。
组数太少会掩盖各组的变化情况,引起较大的计算误差;
组数太多则会造成各组的高度参差不齐,影响数据分布规律的明显性,反而难以看清分布的状况,而且计算工作量大。
组数k的确定可以参考组数选用表,见表10-2。
本例:
取k=10
4.确定组距(h)组距用字母h表示,h=极差(R)/组数(k),一般取测量单位的整数倍以便于分组。
本例h=R/k=47/10=4.7≈5
5.确定各组界限为了避免出现数据值与组的边界值重合而造成频数计算困难的问题,组的边界值单位应取最小测量单位的1/2,也就是把数据的位数向后移动一位,并取数值为5。
例如个位数为0.5;
小数一位数(0.1)为0.05;
小数二位数(0.01)为0.005。
(本例表10-1中所有数据的最小位数为个位数,因此1/2最小测量单位是1/2X1=O.5)。
分组的围应能把数据表中最大值和最小值包括在。
第一组的下限为:
最小值=
本例第一组下限为:
Xmin-
=1-
=0.5
第一组上界限值为下界限值加上组距
0.5+5=5.5
第二组的下界限值就是第一组的上界限值。
第一组的上界限值加上组距就是第二组的上界限值。
照此类推,定出各组的组界。
6.编制频数分布表频数分布袤的表头设计见表10-3。
(1)填入组顺序号及上述已计算好的组界。
(2)计算各组组中值并填入表中。
各组的组中值为:
X中=
例如,第二组组中值为
实际上组的组中值加上组距就是下一组的组中值。
(3)
统计各组频数。
统计时可在频数栏里划记号。
这一步骤很容易出差错,所以要注意力集中。
统计后立即算出总数Σf,看是否与数据总个数N相等。
频数分布表暂时先做到这里,其他栏目以后再填。
(二)画直方图
(1)先画纵坐标,再画横坐标。
纵坐标表示频数。
定纵坐标刻度时,考虑的原则是把频数中最大值定在适当的高度。
本例中频数最大为27,我们就取适当高度定为30。
原点为0,均匀标出中间各值。
(2)横坐标表示质量特性。
定横坐标刻度时要同时考虑最大、最小值及规格围(公差)都应含在坐标值。
本例中Xmax=48,Xmin=1,规格下限TL为0,上限TU为50,因而坐标值围应包括从0至50(克)。
在横坐标上画出规格线,规格下限与频数坐标轴间稍留一些距离,以方便看图。
(3)以组距为底,频数为高,画出各组的直方形。
(4)
在图上标图名,记入搜集数据的时间和其他必要的记录。
总频数N、统计特征值
与s是直方图上的重要数据,一定要标出,见图10-2。
三、
直方图的观察分析
直方图能够比较形象、直观地反映产品质量的分布状况。
使用直方图主要就是通过对图形的观察和分析来判断生产过程是否稳定,预测生产过程的不合格品率。
观察的方法是:
对图形的形状进行观察;
对照规格标准(公差)进行比较。
(一)对图形形状的观察分析
看图形应着眼于直方图的整个形状。
实践中画出的图形常见一些参差不齐的形状,不必计较。
常见的直方图典型形状(图10-3)有以下几种:
1.正常型又称对称型,见图10-3(a)。
它的特点是中:
间高、两边低,呈左右基本对称。
这说明工序处于稳定状态。
2.孤岛型在远离主分布的地方出现小的直方形,犹如孤岛,见图10-3(b)。
孤岛的存在向我们揭示:
短时间有异常因素在起作用,使加工条件起了变化。
例如原料混杂、操作疏忽、短时间有不熟练的工人替班或测量工具有误差等。
3.偏向型直方形的顶峰偏向一侧,所以也叫偏坡形,见图10-3(c)。
计量值只控
制一侧界限时,常出现此现状。
有时也因加工习惯造成这样的分布,例如孔加工往往偏小,而轴加工往往偏大等。
4.双峰型这往往是由于把来自两个总体的数据混在一起作图所致,见图10-3(d)。
例如把两个工人加工的产品或两台设备加工的产品混为一批等。
这种情况应分别作图后再进行分析。
5.平顶型直方呈平顶形,见图13-3(e),往往是由于生产过程中有缓慢变化的因素在起作用所致。
例如刀具的磨损、操作者疲劳等。
应采取措施,控制该因素稳定地处于良好的水平上。
6.锯齿型这种类型的直方图,大量出现参差不齐,但整个图形的整体看起来还是中间高、两边低,左右基本对称,见图13-3(f)。
造成这种情况不是生产上的问题,主要是分组过多或测量仪器精度不够,读数有误等原因所致。
(二)对照规格标准进行分析比较
当工序处于稳定状态时(直方图为正常型),还需要进一步将直方图与规格标准进行比较,以判定工序满足标准要求的程度。
常见的典型直为图(图10-4)也有以下几种:
:
图中B是实际尺寸分布围;
T是规格标准围。
1.理想型B在T的中间,平均值也正好与规格中心重合,实际尺寸分布的两边距规格限有一定余量,约为T/8,见图13-4(a)。
2.偏向型虽然分布围落在规格界限之,但分布中心偏离规格中心,故有超差的可能,说明控制有倾向性,见图13-4(b)。
例如,机械工人主观上认为外径大了可以返工,小了就要报废,于是就往大控制,应调整分布中心使之合理。
3.无富余型分布虽然落在规格围之,但完全没有余量,一不小心就会超差,见图14-4(c)。
必须采取措施,缩小分布的围。
4.能力富余型如见图14-4(d)所示,这种图形说明规格围过分大于实际尺寸分布围,质量过分满足标准的要求。
虽然不出不合格品,但是太不经济。
可以考虑改变工艺,放松加工精度或缩小规格围,或减少检验频次,以便有利于降低成本。
5.能力不足型实际分布尺寸的围太大,造成超差,见图14-4(e)。
这是由于质量波动太大,工序能力不足,出现了一定量不合格品。
应多方面采取措施,缩小分布围。
6.陡璧型如图14-4(f)所示,这是工序控制不好,实际尺寸分布过分地偏离规格中心,造成了超差或废品。
但在作图时,数据中己剔除了不合格品,所以没有超出规格线外的直方部分。
可能是初检时的误差或差错所致。
一、四、
直方图的定量描述
如果画出的直方图比较典型,我们对照以上各种典型图,那么便可以作出判断。
但是实践活动中画出来的图形多少有些参差不齐,或者不那么典型。
而且,由于日常的生产条件变化不太大,因此画出的图形较相似,往往从外形上难以观察分析,得出结论。
例如图10-5是用连续两个月生产数据画出的直方图,从外形上观察很难分清哪个图表示的生产状况更好些。
如果能用数据对直方图进行定量的描述,那么分析直方图就会更有把握些。
描述直方图的关键参数有两个,一个是平均值,另一个是标准偏差。
(一)平均值
的计算
平均值
的计算有两种方法:
1.算术法:
把所有的数都加起来除以总数。
用公式表示为:
=
用表10-1的数字为例,代入得
2.加权法利用频数表,再用加权法计算平均值。
可以有三种方法。
(1)可用公式:
计算。
式中:
fi为各组的频数:
X中i为各组的组中值。
用表10-3的数据为例代入得:
=(f1X中1+f2X中2+f3X中3+…+f4X中4)/100
因为这里应用了各组的组中值为代表值进行计算,所以这是一种近似的简算方法。
在工业生产中,其计算精度一般能满足要求。
(2)变换数法。
这是加权法的简易算法,可以利用频数分布表进行。
令频数最大的组的变换数u为0。
以表10-3为例,第六组频数最大,令其变换数u6=0。
然后向上为负值,依次递减1,即填入-1、-2、-3.......,向下为正值,依次递增1,即填入1、2、3......。
计算频数与变换数的乘积fiui及累加值Σfiui,填入表中。
f1u1=1×
(-5)=-5,
f2u2=3×
(-4)=-12
其余类推
Σfiui=(-5)+(-12)+(-18)+(-28)+(-19)+0+14+20+9+12=-27
的计算公式是:
=h
+x0
式中:
h是组距。
本例为5;
x0是令其变换数为0的那一组的组中值(即频数最大的组的组中值)。
本例为x0=x中6=28;
Σfi是各组频数的累加值。
本例为100;
Σfiui是各组fiui的累加值。
本例为-27。
用表10-3的数据代入:
+x0=5×
+28=26.6
(3)A...E法。
这是一种更简化的加权法,它的计算结果和变换数法得到的结果完全一样。
其优点是变乘、除为加、减,计算时也要应用频数分布表。
但用这个方法就不要计算u、fu、fu2值,只要计算第I、II列。
计算第I列,仍然先定频数最大的组为0,0上边那个数定为C,下边那个数定为A。
0上方分别从上而下依次将频数累加后填入。
表10-3中令第六组为0,在0上方自上而下计算累计频数。
例如第一组为1;
第二组为1+3=4;
第三组为4+6=10......。
0以下的数是自下而上计算累计频数,例如第10组为3;
第9组为3+3=6;
第8组为6+10=16......。
计算第II列。
第二列为第一列数据的累计数。
计算方法与第一列基本相同,但要先在第I列中为0的那个组再定一个0,且在上、下两组再各定一个0。
0的上方的那一组定为D;
0的下方的那个组定为B(表10-3)。
平均值的计算公式为:
=x0+h×
x0为第I列中令频数为0的那一组的组中值;
h为组距;
A、B、C、D为所指定的那些数值。
A=30、B=25、C=43、D=39;
=28+5×
(二)
标准偏差s的计算
虽然极差R也能反映分散程度,但是它只考虑数据最大值和最小值的影响,没有考虑其余中间数据分布的影响,因此极差反映实际情况的能力较差。
因此,在实际工作中,就有必要运用另一个较为准确反映分散程度的统计特征值,即标准偏差。
1.标准偏差的计算公式
s=
2.利用频数分布表计算先计算fiui2。
在频数分布表中把每组的uI×
fiuI,即得fiui2值,填入表格并计算各组的fiui2累加值Σfiui2。
f1u12=(-5)×
(-5)=25
f2u22=(-4)×
(-12)=48
……
Σfiui2=25+48+54+……+48=331
标准偏差的计算公式为:
s=h
N为数据总数。
用本例的数据代入得:
s=5×
=9.0
3.用A……E法计算计算公式为:
s=h×
E为第II列的累加数。
本例为97,用本例的数据代入得:
(三)直方图的定量表示
定量表示直方图的主要统计特征值(参数)是平均值
和标准偏差S。
直方图中,平均值
表示数据的分布中心位置,它与规格中心M越靠近越好。
直方图中,标准偏差s表示数据的分散程度。
标准偏差s决定了直方图图形的“胖瘦”。
s越大,图形越“胖”,说明数据的分散程度越大,说明这批产品的加工精度越差。
据此,再观察团10-5,我们就可以容易地注意到7月份和8月份这两个月的生产状况是有差异的:
8比
7更靠近规格中心10.25,表明控制得更合理;
S8比S7小,说明控制更严格,质量波动小。
因此,8月份生产的产品质量要更好些。
直方图与分布曲线
在第七章中,我们已经叙述了样本与总体的推断关系。
就是说,从总体中,随机抽取部分样本,通过测得样本的统计特征值来推断总体的质量状况。
对计量值数据来说,当生产处于控制状态时,通过从总体中,随机抽取样本测得的质量特性数据,可以计算出样本的平均值
、标准偏差S和画出直方图。
可以设想,随着抽取的样本数量不断增加,直方图的分组数也不断增多,组距不断减小,直方图形也就越来越密,继而得到连续的分布曲线。
这就是说,当生产处于稳定状态下,总体存在着一定的分布,且其统计特征值的参数是平均值为μ,标准偏差为σ;
然而从理论上说,μ和σ是无法精确计算的。
数理统计学的原理告诉我们:
当总体服从正态分布规律时,由随机抽取得到的样本质量数据,也服从正态分布规律,而且
具有:
样本的平均值
近似于总体的平均值μ;
样本的标准偏差S:
近似于总体的标准偏差σ。
因此在质量管理中,对于样本而言常以
、S来表示其统计特征值;
用来估计、推断总体的μ和σ(见图10一6)。
六、直方图法在应用中常见的错误和注意事项
(1)抽取的样本数量过小,将会产生较大误差,可信度低,也就失去统计的意义。
样本数应不少于50个。
(2)分组数k选用不当。
组数k选得偏大或偏小,都会造成对分布状态的判断有误。
(3)直方图一般适用于计量值数据,但在某些情况下也适用于计数值数据,这要依绘制直方图的目的而定。
(4)图形不完整,标注不齐全。
直方图上应标注:
公差围线、平均值
的位置(用点划线表示),
不能与公差中心位置M相混淆;
图的右上角标出N、
、S、Cp或Cpb的数值。
第十章散布图法
一、什么是散布图
散布图也叫相关图。
它是用来研究、判断两个变量之间相关关系的图。
我们经常会遇到这样一类问题:
两个变量之间是否有互相联系、互相影响的关系?
如果存在关系,那么这种关系是什么样的关系?
例如某些食品的水分含量与霉变;
热处理工艺中淬火温度与淬火硬度;
酿酒中酒药量与出酒率等等。
在对两个变量进行分析后,可以得出有无关系、什么样的关系以及二者之间所存在的相互间关系的规律的结论。
(一)两种不同的关系
当我们分析、研究两个有关系的变量问题时,常有两种不同的关系。
1.确定性的函数关系这种关系是两个变量之间存在着完全确定的函数关系。
例如圆的周长C和圆的直径D之间存在着C=π·
D的关系,只要知道圆的直径,就能精确地求出圆的周长;
或者知道圆的周长,就可求得圆的直径。
不管谁来计算,答案是唯一的。
这种变量间的关系是完全确定的关系。
2.非确定性的相关关系这种关系是非确定性的依赖或制约的关系。
例如儿童的年龄和体重之间虽有一定关系,但只能一般地说儿童年龄越大,体重也越重。
然而,并不是所有的同龄儿童,体重都相同。
在一些生活顾问手册中常可以见到用这样一个公式来表示儿童的年龄和体重之间的关系
儿童体重=年龄×
2+7(千克)
这是一个统计了很多中国儿童年龄和体重的数据后得到的推荐式。
虽然不是所有2周岁儿童的体重都是11千克,但总是在11千克左右。
我们把这种关系叫相关关系。
相关关系是可以借助统计技术来描述这种变量之间的关系。
散布图法就是解决这个问题的统计技术。
(三)
散布图的基本形式
散布图由一个纵坐标、一个横坐标、很多散布的点子组成。
图12一1是某零件在热处理中淬火温度与淬火硬度两个变量之间关系的散布图。
从散布图上的点子分布状况,可以观察分析出两个变量(x、y)之间是否有相关关系,以及关系的密切程度如何。
在质量管理活动中,我们可以运用散布图来判断各种因素对产品质量特性有无影响及影响程度的大小。
当两个变量相关程度很大时,则找出他们的关系式y=ax+b。
然后借助于这一关系式。
只需观察其中一个变量就可以推断出另一个变量,以达到简化和节约的目的。
还可以从控制一个变量,估计另一个变量的数值。
二、散布图的作图方法
举一个酒厂的实例来说明散布图的作图步骤。
(一)搜集数据
某酒厂为要判定中间产品酒醅中酸度含量和酒度两变量之间有无关系,以及存在什么关系,使用了散布图法。
作散布图的数据一般应搜集30组以上。
数据太少,相关就不太明显,因而会导致判断不准确;
数据太多:
计算的工作量就太大。
本例搜集了30组酒醅中酸度和对应酒度的数据填入数据表。
把酸度定为自变量x值,对应的酒度定为应变量y值(表12一1)。
(二)打点
先画纵坐标,再画横坐标。
横坐标为自变量,取值围应包括自变量数值(x值)的最大值与最小值,越往右取值越大。
本例中x值最小为0.5,最大为1.6,则横坐标值从0.4取到1.8为宜。
纵坐标为应变量,应包括应变量数值(Y值)的最大值与最小值,越往上取值越大。
本例中Y值最小是3.4,最大是6.8,则纵坐标值从3.0取到7.0为宜。
把数据表中的各组对应数据一一按坐标位置用坐标点表示出来。
如果碰上一组数据和另一组完全相同(本例的第3组和第
 升级会员
升级会员 