张伟豪SPSS培训视频7笔记T检验和方差检验Word文档格式.docx
《张伟豪SPSS培训视频7笔记T检验和方差检验Word文档格式.docx》由会员分享,可在线阅读,更多相关《张伟豪SPSS培训视频7笔记T检验和方差检验Word文档格式.docx(31页珍藏版)》请在冰豆网上搜索。
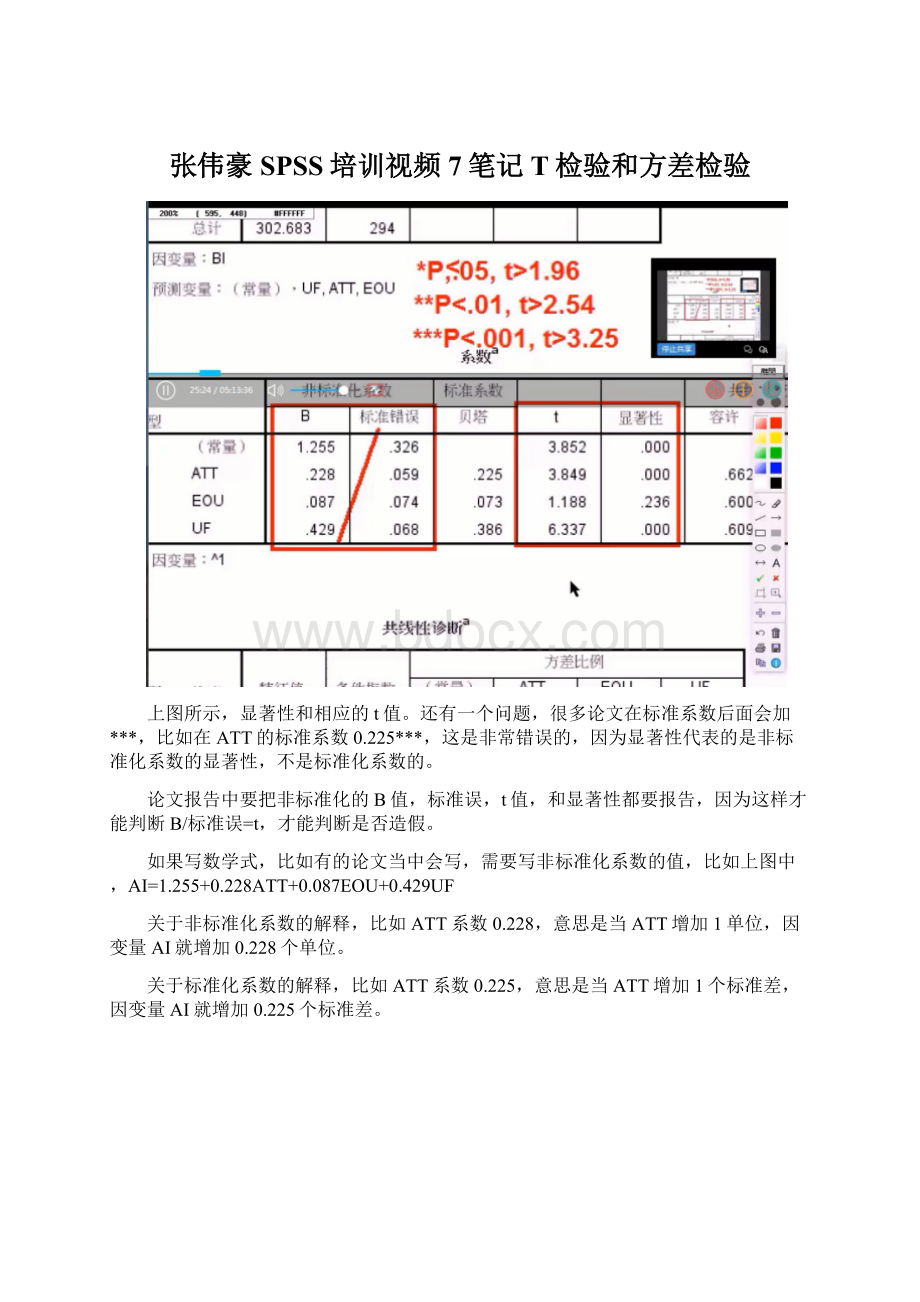
2、贝塔值的平方会高于R方,正常情况下贝塔值的平方是不会高于R方的。
容许(容差)的计算方法,比如ATT的容许,是把ATT作为因变量,其他两个自变量对它进行解释,如果有共线性的话,相关性就会比较高,那么R方也会比较大,1-R方,就是容许量,因此容许量比较小,就说明有共线性,而VIF是容许的导数,容许量比较小,它的导数就会比较大,就是有共线性。
上图中的常量是不用解释的,因为它的大小无所谓,不会有影响,显不显著也没关系。
在回归分析的方法下拉菜单中,有以上几种方法,分别是什么意思呢?
输入法表示,我们几个自变量对因变量是有假设的,假设他们之间有相关关系,然后再做回归。
因为输入法不论变量之间显著不显著,都会跑出结果来。
这种叫做验证式研究。
逐步法是将后退法和前进法合并起来的方法,什么是前进法什么是后退法呢?
后退法指的是将不重要的都扔掉,留下重要的。
比如捡漂亮石头,我把所有石头都放到袋子里,然后将不漂亮的扔掉,剩下漂亮的,这叫做后退法。
前进法指的是将重要的一个个捡进来,捡到不重要的就停止。
比如捡石头的袋子是空的,我把最漂亮的石头捡进来,然后再捡第二漂亮的,一直捡到不漂亮的为止。
这叫做前进法。
逐步法就是将前进法和后退法合并起来。
逐步法是在有很多自变量,不知道里面哪些自变量对因变量有影响,因此也就没有假设,需要通过逐步法进行筛选,剩下有影响的自变量。
这种叫做探索式研究。
通常大多数的逻辑思回归都会用逐步法,因为没有假设。
路径分析应该如何做?
如上图,里面有三个因变量,分别是有用性、态度、行为意图。
这样就需要做三次回归
第一个回归是自变量EOU(易用性),因变量UF(有用性)
第二个回归是自变量是EOU(易用性)和UF(有用性),因变量是ATT(态度)
第三个回归是自变量是UF(有用性)和ATT(态度),因变量是BI(行为意图)
然后把三次回归的分析结果综合为一张表,路径分析就完成了。
最后可以把路径分析结果写入模型中,先写非标准化系数,后面可以加***,然后下面括号写(标准误,标准化系数),因为这样别人才可以通过非标准化系数和标准误相除,算出是否真的显著。
均值检定中,所有因变量dependent,都必须是连续变量,自变量必须是一个
T检验自变量是二分类变量binary,例如是或否,男或女
单变量方差分析one-wayANOVA自变量是三类以上分类变量category,比如学历、年龄等,并且只能有一个自变量。
如果放入好几个自变量,SPSS会一个一个跑完。
双变量方差分析two-wayANOVA自变量也是三类以上分类变量,但是有两个自变量,控制变量必须是分类变量
共变量方差分析ANCOVA自变量是二分类变量或者分类变量,控制变量必须是连续的
回归的自变量必须是连续的,如果是分类变量,需要转换为虚拟变量(哑变量)dummy
先来介绍t检验
H0永远放的是没有显著差异的假设,要不要拒绝要看情况而定。
一般我们常用到的是独立样本t检验和成对样本t检验,如何区分呢?
两群样本不重复为独立样本——比如上图,实验组和控制组服药前血压进行鉴定,看看有没有差异,因为是两个不同(不重复)样本,因此属于独立样本t检验。
我们希望服药前是没有差异的,因此希望不拒绝H0。
服药后两组再进行检验,也是不同的两组样本,因此也是独立样本t检验,这时我们希望服药后两组应该有差异,这样药物才是有效的,因此希望拒绝h0.
两群样本重复为成对样本——比如上图,实验组服药前和服药后进行检验,因为是同一组(重复)样本,因此属于成对样本t检验。
我们希望服药前和服药后有差异,这样药物才是有效的。
控制组服药前和服药后进行检验,因为也是同一组(重复)样本,因此也属于成对样本t检验。
我们希望控制组服药前和服药后没有差异,这样才能证明安慰剂没有起到心里安慰作用。
具体操作如下
表格设定了pre1测试前水平,after测试后水平,control分为实验组1,控制组2。
先做实验组和控制组进行测试前后是否有差异,所以采用独立样本t检验。
选择分析——比较均值——独立样本t检验,将pre1和after选入检验变量中,control选入分组变量中,定义组选为1和2,确定
结果显示,第一行显著性是不显著的,说明控制组和实验组在测试前没有明显差异,样本是没有问题的。
第二行显著性,测试前是不显著的,测试后是显著的,说明药物确实起了作用。
但是并没有显示出测试后的差异是只有实验组有差异,还是实验组和控制组都出现了差异,如果都出现了差异那就说明安慰剂也起作用了,所以需要再检验控制组有没有出现差异。
再做成对样本t检验。
选择数据——拆分文件,
选择比较组选项,将control选进去,意思是进行分组分析。
如果不进行拆分文件,那做出来的结果是两个组的人都有,没有分开。
然后选择分析——比较均值——配对样本t检验,将pre1和after选进去,确定
结果显示,实验组1,显著性是显著的,控制组2,显著性是不显著的。
符合预期结果,说明控制组没有受到安慰剂影响。
上边这个表,配对样本相关性,指的是实验组1,相关系数0.687,显著性显著,说明实验组在测试前后的相关性比较高。
控制组2,相关系数0.410,显著性不显著,说明控制组在测试前后的相关性比较低,虽然0.410比较高了,但是因为样本只有10个,太少,所以还是不显著,如果样本多一些,比如100个,可能就显著了。
现在来做ANOVA检验
如上图,media媒体有1234四种,我们要看看这四种媒体在影响力influence、吸引力attractive、信任trust三个值中的差异。
选择分析——比较均值——单因素ANOVA,把三个变量放入因变量列表,把四种媒体media放入因子(自变量)框,选择事后多重比较选项,勾选其中的scheffe和tukey选项,然后确定
先看ANOVA表,影响力和信任的显著性是显著的,吸引力不显著,说明四种媒体在影响力和信任方面是有差异的,在吸引力方面是没有差异的。
但是这个表不能看出四中媒体谁和谁有差异。
需要看时候检验。
先查看turkeyHSD,发现上图中红框是有差异的,两个红框指的是相同的两个媒体。
说明1平面媒体和3网络媒体的影响力是有差异的,差异多少呢?
看第一列平均差I-J为-10.76,也就是说网络媒体比平面媒体高10.76.
再看信任的TurkeyHSD,上图中红框都是显著的,解释方法同上。
在回归分析中,如果自变量是分类变量,因为要求回归分析的自变量必须是连续变量,因此就需要转成哑变量才可以计算。
首先来看如何转换
现在要把学历school这个分类变量转换为哑变量,学历从小学到大学一共有12334四类,
现在在白纸上画下来,四个分类要以其中一个为基准,把国中以下作为基准,那它的三个值都是0,其他三个如上图所示,有一个值为1,其他为0.
利用转换为新变量功能,把2转换为1,其他都是0,设置一个新值
把3转换为1,其他都是0,设置一个新值
把4转为1,其他都是0,设置一个新值
这样就出现3个新值
如果像性别这样只有1和0,那就不用转,直接就是哑变量,如果是三个分类变量,要转为2个哑变量,4个分类变量,要转为3个哑变量,以此类推。
然后做一个试验看看有什么规律。
现在以性别为自变量做一个独立样本T检验,随便找一个SQ作为因变量,代入运行
结果显示没有显著差异,p值为0.248,右边的平均差是-0.10066
现在再拿性别和SQ做回归,分别代入,运行
结果显示,显著性同样是0.248,回归系数也是0.101(刚才是-0.10066,四舍五入一样,而且那是女减男,这是男减女,所以一个是正一个是负)
这说明什么呢?
回归分析估计的结果是斜率的差异,但是如果自变量转为哑变量后,就和T检验一样,估计出来的就是均值的差异了。
下面再以相同的方式证明一下,使用刚才学历转换的哑变量进行运算
使用单因子方差检验,把school学历放入自变量,因变量还是使用SQ
然后在使用回归做分析,只不过自变量不能再放入原来的school,而要放入转换完的哑变量,如上图,运行
可以看到,回归的显著性是0.023
而单因子方差分析的显著性也是0.023,
在edu1中的回归系数是-0.583,解释为,高中对服务品质的看法,减去基准组也就是国中以下对服务品质的看法。
是负值,那就是国中组的看法高于高中组。
再看方差分析的结果,国中组减去高中组的平均差也是0.58333,是一样的。
这就再一次证明,用哑变量跑出来的回归结果是均值的差异,而不是斜率的差异。
这也是为什么控制变量必须是连续变量,因为控制变量测算的是斜率的差异,而不是均值的差异,因此比如性别、年龄等不能作为控制变量,这就是原因。
但是有一个差异,就是虽然回归系数和方差分析的平均差是一致的,但是显著性却不一样,回归的显著性明显比方差分析的显著。
什么原因呢?
主要是因为方差分析是把分类变量每个组分别来计算,而回归是将所有转换为哑变量的分类变量一起来计算,因此比较容易显著。
给我们的启示:
如果在写论文中,方差分析或者t检验的结果不显著,就可以把分类变量转换为哑变量,用回归来代替,这样就比较容易显著了。
这样比较出来的就是均值差异,比如上图,是以国中为基准组,比较高中和国中、大学和国中、研究所和国中的均值差异。
那如果要比较大学和高中的差异怎么办呢?
必须回到开始,将高中设为基准组,才可以逐个比较。
另:
如果方差分析时,方差是不齐性的,那就可以勾选红框中的G-H进行运算。
(具体含义不太清楚)
方差检验一般是三个以上的分类变量做自变量,两个分类变量就用T检验,但是两个分类变量也可以用方差检验,而且结果和T检验是一样的。
另外,方差检验其实就是独立样本T检验的拓展,比较两个不同组的分类变量用T检验,比较多个不同组的分类变量就用方差分析。
那么,比较同一组的两次测试结果用配对样本T检验,它的拓展(也就是比较同一组的多次测试结果)用什么方法呢?
如下
选择分析——一般线性模型——重复测量,
打开后,你需要重复比较几次,就填入几,这样就可以运算了(具体操作省略)。
 升级会员
升级会员 