tiny语言的词法分析器c++课程设计报告Word下载.docx
《tiny语言的词法分析器c++课程设计报告Word下载.docx》由会员分享,可在线阅读,更多相关《tiny语言的词法分析器c++课程设计报告Word下载.docx(12页珍藏版)》请在冰豆网上搜索。
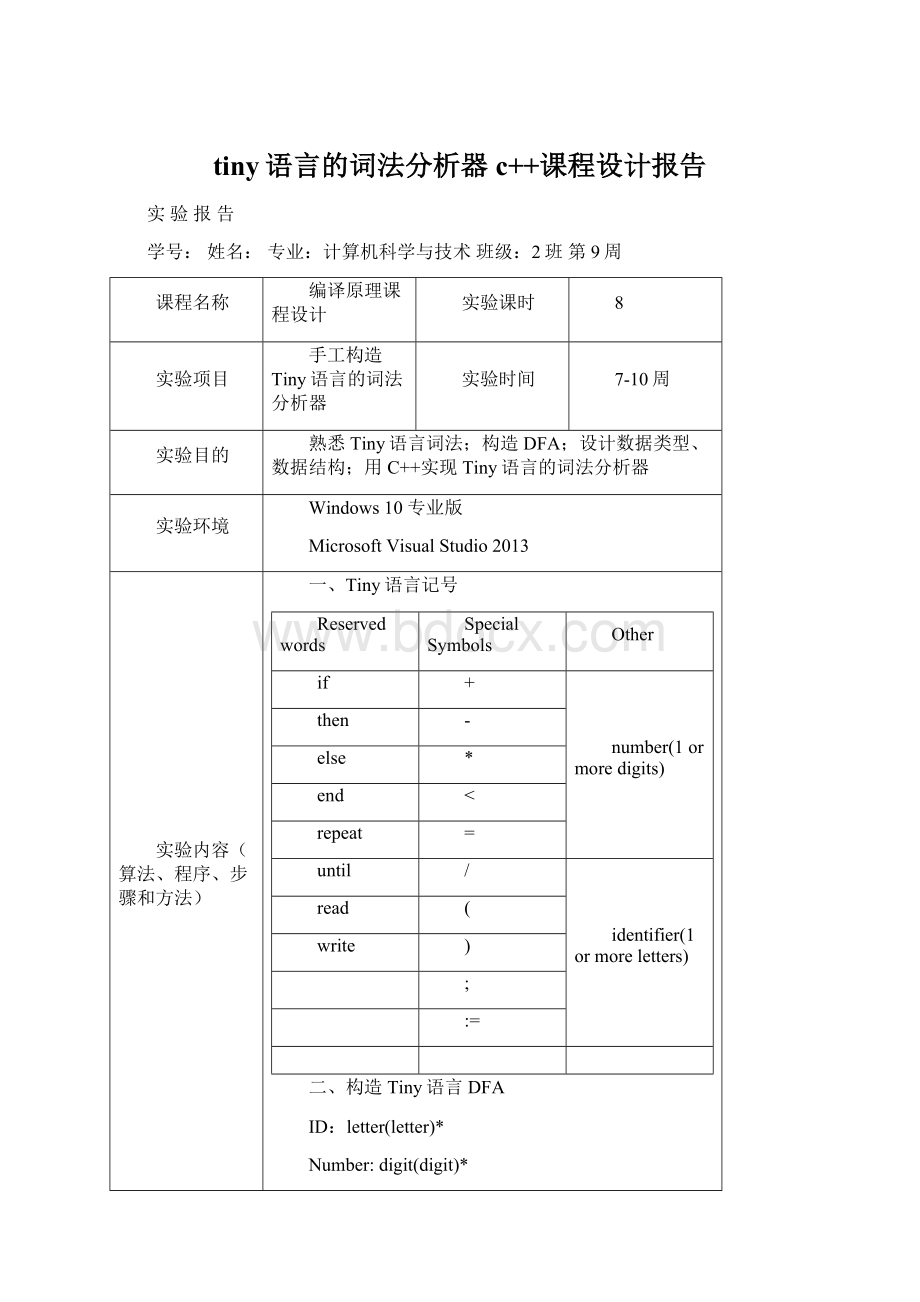
<
repeat
=
until
/
identifier(1ormoreletters)
read
(
write
)
;
:
二、构造Tiny语言DFA
ID:
letter(letter)*
Number:
digit(digit)*
三、根据DFA编写词法分析器
#include<
fstream>
string>
iostream>
usingnamespacestd;
staticintrowCounter=1;
//静态变量,用于存储行数
staticboolbracketExist=false;
//判断注释存在与否,false为不存在
classLex
{
public:
ofstreamoutput;
stringline="
"
Lex(stringinputLine)
{
line=inputLine;
scan(Trim(line));
rowCounter++;
}
stringTrim(string&
str)//函数用于去除每行前后空格
ints=("
\t"
);
inte=("
str=(s,e-s+1);
str+="
\0"
returnstr;
voidscan(stringinputLine)
ofstreamoutput;
("
ios:
app);
stringline=inputLine;
inti=0;
stringstr="
inttemp;
stringtoken="
output<
rowCounter<
"
<
line<
endl;
//输出每行
while(line[i]!
='
\0'
)//根据DFA扫描并判断
{
if(line[i]=='
{'
)//注释
{
bracketExist=true;
}
if(bracketExist==true)
output<
\t"
while(line[i]!
}'
{
output<
line[i];
//不处理,直接输出
if(line[i+1]!
=NULL)
{
i++;
}
else
break;
}
if(line[i]=='
)//注释结束
line[i]<
endl;
bracketExist=false;
if(bracketExist==false)
//数字
while(isdigit(line[i]))
temp=temp*10+line[i];
if(!
isdigit(line[i+1]))
output<
NUM,val="
temp-'
0'
=NULL&
&
temp=0;
//符号
while(!
(isdigit(line[i])||(line[i]>
a'
line[i]<
z'
)||(line[i]>
A'
Z'
)||line[i]=='
'
||line[i]=='
))
token=token+line[i];
if(isdigit(line[i+1])||(line[i+1]>
line[i+1]<
)||(line[i+1]>
)||line[i+1]=='
||line[i+1]=='
||line[i+1]==NULL)
if(isToken(token))
{
output<
token<
}
else
intj=0;
while(token[j]!
{
output<
token[j]<
j++;
}
continue;
token="
//字母
while((line[i]>
str=str+line[i];
((line[i+1]>
)))
if(isResearvedWord(str))//判断是否是保留字
ReversedWord:
str<
break;
ID,name="
str="
if(line[i+1]!
i++;
}
else
break;
if(line[i+1]==NULL)
'
break;
}
//清空,以备下一行读取
line="
str="
temp=0;
token="
();
boolisResearvedWord(strings)//存储保留字,并判断
stringreservedWord[8]={"
if"
"
then"
else"
end"
repeat"
until"
read"
write"
};
booljudge=false;
for(inti=0;
i<
8;
i++)
if(s==reservedWord[i])
judge=true;
returnjudge;
boolisToken(strings)//存储符号,并判断
stringtoken[10]={"
+"
-"
*"
/"
="
("
)"
10;
if(s==token[i])
};
intmain()
ifstreaminput;
("
stringline[50];
inti=0;
while(getline(input,line[i]))
//cout<
line[i]<
i++;
();
cout<
endl<
Readingsourcefilecompleted!
!
intj=0;
remove("
for(j=0;
j<
i;
j++)
Lexlex(line[j]);
Writingfilecompleted!
return0;
}
四、重要数据结构
stringline[]:
用于存储每一行的字符,并逐个读取分析。
stringtoken[]:
用于存储TINY语言的符号,并调用遍历进行判断。
stringreservedWord[]:
用于存储TINY语言的保留字,遍历进行判断,若为真,则输出Reservedword。
staticintrowCounter:
静态变量,存储行号,每创建一个类的实例便加一。
inttemp:
用于存储数字,并输出。
staticintbracketExist:
静态变量,标记注释是否存在。
stringtoken,str分别用于临时存储读取的符号的字母串。
五、算法总结
建立Lexclass,并读取每一行,创建Lex的实例,在Lex中处理。
先判断是否在注释范围内,若是,则输出注释内容,直至产生“}”字符。
若不在注释区内,则读取单个字符,根据DFA进行判断。
若为符号,则当下一个字符不是符号时输出;
若为数字,则继续往下读,直至下一个字符不是数字为止,输出。
若为字母,继续读取,直至下一个字符不是字母,把这一串字母和预先定义的保留字比对,若是,则输出“Reservedword”,若不是,则输出“ID,name=”字样。
一行处理完毕,便开始创建下一行实例,直至文件尾。
数据记录
和计算
Tiny测试程序
结论
(结果)
1:
{Sampleprogram
1:
2:
inTINYlanguage-
2:
3:
computesfactorial
3:
4:
4:
5:
readx;
{inputaninteger}
5:
ReversedWord:
read
ID,name=x
;
6:
if0<
xthen{don'
tcomputeifx<
=0}
6:
if
NUM,val=0
then
{don'
7:
fact:
=1;
7:
ID,name=fact
:
NUM,val=1
8:
repeat
8:
9:
=fact*x;
9:
*
10:
x:
=x-1;
10:
-
11:
untilx=0;
11:
until
=
12:
writefact{outputfactorialofx}
12:
write
{outputfactorialofx}
13:
end
13:
小结
顺利完成实验,熟悉了Tiny语言和其词法。
根据语言和词法规则,顺利构造DFA。
成功用C++语言,根据构造的DFA,实现了Tiny词法分析器。
增强了自己的编程能力和水平技巧,尝试了很多以前没有尝试过的方法学习到了新知识。
指导老师评议
成绩评定:
指导教师签名:
精心搜集整理,请按实际需求再行修改编辑,因文档各种差异排版需调整字体属性及大小
 升级会员
升级会员 