用Excel完成专业化数据统计分析工作Word格式.docx
《用Excel完成专业化数据统计分析工作Word格式.docx》由会员分享,可在线阅读,更多相关《用Excel完成专业化数据统计分析工作Word格式.docx(27页珍藏版)》请在冰豆网上搜索。
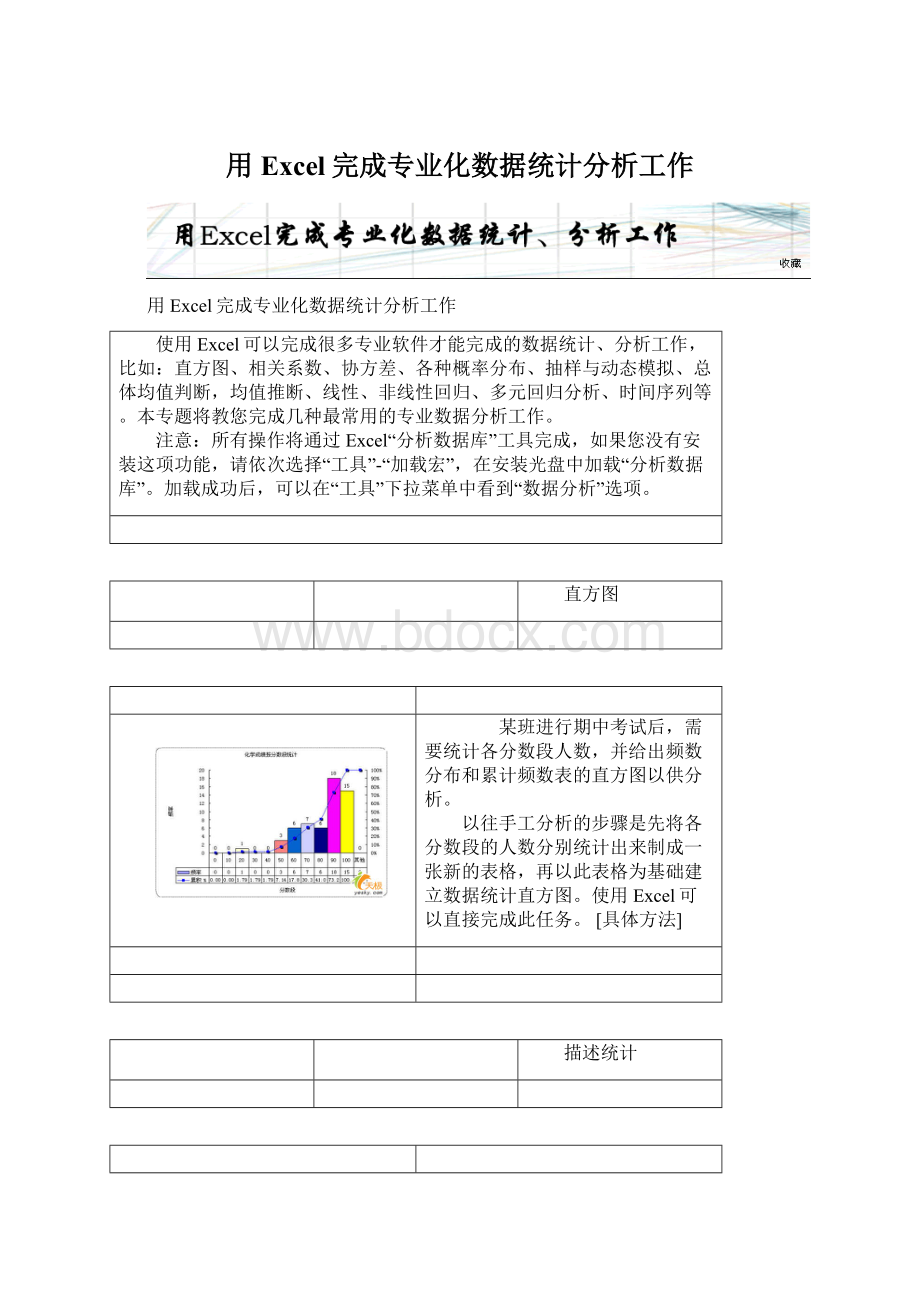
用于判断两个测量值变量的变化是否相关,即,一个变量的较大值是否与另一个变量的较大值相关联(正相关);
或者一个变量的较小值是否与另一个变量的较大值相关联(负相关);
还是两个变量中的值互不关联(相关系数近似于零)。
抽样分析工具
抽样分析工具以数据源区域为总体,从而为其创建一个样本。
当总体太大而不能进行处理或绘制时,可以选用具有代表性的样本。
如果确认数据源区域中的数据是周期性的,还可以对一个周期中特定时间段中的数值进行采样。
也可以采用随机抽样,满足用户保证抽样的代表性的要求。
移动平均
移动平均就是对一系列变化的数据按照指定的数据数量依次求取平均,并以此作为数据变化的趋势供分析人员参考。
移动平均在生活中也不乏见,气象意义上的四季界定就是移动平均最好的应用。
我们来看怎么用Excel完成移动平均的统计工作。
[具体方法]
回归分析
溶液浓度正比对应于色谱仪器中的峰面积,现欲建立不同浓度下对应峰面积的标准曲线以供测试未知样品的实际浓度。
已知8组对应数据,建立标准曲线,并且对此曲线进行评价,给出残差等分析数据。
这是一个很典型的线性拟合问题,手工计算就是采用最小二乘法求出拟合直线的待定参数,同时可以得出R的值,也就是相关系数的大小。
在Excel中,可以采用先绘图再添加趋势线的方法完成前两步的要求。
具体操作:
1用Excel做数据分析——直方图
注:
本功能需要使用Excel扩展功能,如果您的Excel尚未安装数据分析,请依次选择“工具”-“加载宏”,在安装光盘中加载“分析数据库”。
实例1
某班级期中考试进行后,需要统计各分数段人数,并给出频数分布和累计频数表的直方图以供分析。
使用Excel中的“数据分析”功能可以直接完成此任务。
操作步骤
1.打开原始数据表格,制作本实例的原始数据要求单列,确认数据的范围。
本实例为化学成绩,故数据范围确定为0-100。
2.在右侧输入数据接受序列。
所谓“数据接受序列”,就是分段统计的数据间隔,该区域包含一组可选的用来定义接收区域的边界值。
这些值应当按升序排列。
在本实例中,就是以多少分数段作为统计的单元。
可采用拖动的方法生成,也可以按照需要自行设置。
本实例采用10分一个分数统计单元。
3.选择“工具”-“数据分析”-“直方图”后,出现属性设置框,依次选择:
输入区域:
原始数据区域;
接受区域:
数据接受序列;
如果选择“输出区域”,则新对象直接插入当前表格中;
选中“柏拉图”,此复选框可在输出表中按降序来显示数据;
若选择“累计百分率”,则会在直方图上叠加累计频率曲线;
4.输入完毕后,则可立即生成相应的直方图,这张图还需要比较大的调整。
主要是:
横纵坐标的标题、柱型图的间隔以及各种数据的字体、字号等等。
为了达到柱型图之间无缝的紧密排列,需要将“数据系列格式”中的“选项”中“分类间距”调整为“0”。
其余细节,请双击要调整的对象按照常规方法进行调整,这里不再赘述。
调整后的直方图参考如下
2、用Excel做数据分析——描述统计
样本数据分布区间、标准差等都是描述样本数据范围及波动大小的统计量,统计标准差需要得到样本均值,计算较为繁琐。
注:
1.打开原始数据表格,制作本实例的原始数据无特殊要求,只要满足行或列中为同一属性数值即可。
2.选择“工具”-“数据分析”-“描述统计”后,出现属性设置框,依次选择:
原始数据区域,可以选中多个行或列,注意选择相应的分组方式;
如果数据有标志,注意勾选“标志位于第一行”;
如果输入区域没有标志项,该复选框将被清除,Excel将在输出表中生成适宜的数据标志;
输出区域可以选择本表、新工作表或是新工作簿;
汇总统计:
包括有平均值、标准误差(相对于平均值)、中值、众数、标准偏差、方差、峰值、偏斜度、极差、最小值、最大值、总和、总个数、最大值、最小值和置信度等相关项目。
其中:
中值:
排序后位于中间的数据的值;
众数:
出现次数最多的值;
峰值:
衡量数据分布起伏变化的指标,以正态分布为基准,比其平缓时值为正,反之则为负;
偏斜度:
衡量数据峰值偏移的指数,根据峰值在均值左侧或者右侧分别为正值或负值;
极差:
最大值与最小值的差。
第K大(小)值:
输出表的某一行中包含每个数据区域中的第k个最大(小)值。
平均数置信度:
数值95%可用来计算在显著性水平为5%时的平均值置信度。
结果示例如下(本实例演示了双列数据的描述统计结果):
成绩
学习时间
平均
78.64285714
62.91428571
标准误差
2.408241878
1.926593502
中位数
85
68
众数
98
78.4
标准差
18.02163202
14.41730562
方差
324.7792208
207.8587013
峰度
1.464424408
偏度
-1.130551511
-1.13055151
区域
最小值
15
12
最大值
100
80
求和
4404
3523.2
观测数
56
最大
(1)
最小
(1)
置信度(95.0%)
4.826224539
3.860979631
3用Excel做数据分析——排位与百分比排位
排序操作是Excel的基本操作,Excel“数据分析”中的“排位与百分比排位”可以使这个工作简化,直接输出报表。
注:
1.打开原始数据表格,制作本实例的原始数据无特殊要求,只要满足行或列中为同一属性数值即可。
2.选择“工具”-“数据分析”-“描述统计”后,出现属性设置框,依次选择;
输入区域:
选择数据区域,如果有数据标志,注意同时勾选下方“标志位于第一行”;
分组方式:
指示输入区域中的数据是按行还是按列考虑,请根据原数据格式选择;
输出区域可以选择本表、新工作表组或是新工作簿。
3.点击“确定”即可看到生成的报表。
可以看到,此时生成一个四列的新表格,其中“点”是指排序后原数据的序数,在本实例中对应与学号,这也是很实用的一个序列;
“成绩”即为排序后的数据系列;
“排位”采取重复数据占用同一位置的统计方法;
“百分比”是按照降序排列的,为了得到真正的“百分比排位”,还需要稍微作一下调整。
4.在“百分比”列的下一列输入“百分排名”,在第一个单元格中输入公式“=1-G3(对应于‘百分排名’)”,回车。
选中该单元格,向下拖动直至填充完毕。
这样就达到了显示百分比排名的目的。
完成的报表实例如下图所示。
4用Excel做数据分析——相关系数与协方差
相关系数是描述两个测量值变量之间的离散程度的指标。
用于判断两个测量值变量的变化是否相关,即,一个变量的较大值是否与另一个变量的较大值相关联(正相关);
设(X,Y)为二元随机变量,那么:
为随机变量X与Y的相关系数。
p是度量随机变量X与Y之间线性相关密切程度的数字特征。
1.打开原始数据表格,制作本实例的原始数据需要满足两组或两组以上的数据,结果将给出其中任意两项的相关系数。
2.选择“工具”-“数据分析”-“描述统计”后,出现属性设置框,依次选择:
选择数据区域,注意需要满足至少两组数据。
如果有数据标志,注意同时勾选下方“标志位于第一行”;
输出区域可以选择本表、新工作表组或是新工作簿;
可以看到,在相应区域生成了一个3×
3的矩阵,数据项目的交叉处就是其相关系数。
显然,数据与本身是完全相关的,相关系数在对角线上显示为1;
两组数据间在矩阵上有两个位置,它们是相同的,故右上侧重复部分不显示数据。
左下侧相应位置分别是温度与压力A、B和两组压力数据间的相关系数。
从数据统计结论可以看出,温度与压力A、B的相关性分别达到了0.95和0.94,这说明它们呈现良好的正相关性,而两组压力数据间的相关性达到了0.998,这说明在不同反应器内的相同条件下反应一致性很好,可以忽略因为更换反应器造成的系统误差。
协方差的统计与相关系数的活的方法相似,统计结果同样返回一个输出表和一个矩阵,分别表示每对测量值变量之间的相关系数和协方差。
不同之处在于相关系数的取值在-1和+1之间,而协方差没有限定的取值范围。
相关系数和协方差都是描述两个变量离散程度的指标。
5用Excel做数据分析——抽样分析工具
抽样分析工具以数据源区域为总体,从而为其创建一个样本。
如果确认数据源区域中的数据是周期性的,还可以对一个周期中特定时间段中的数值进行采样。
本功能需要使用Excel扩展功能,如果您的Excel尚未安装数据分析,请依次选择“工具”-“加载宏”,在安装光盘的支持下加载“数据分析库”。
加载成功后,可以在工具的下拉菜单中看到“数据分析”选项。
操作步骤:
实例中显示的是学生学号。
2.选择“工具”—“数据分析”—“抽样”后,出现对话框,依次选择:
把原始总体数据放在此区域中,数据类型不限,数值型或者文本型均可;
抽样方法:
有间隔和随机两种。
间隔抽样需要输入周期间隔,输入区域中位于间隔点处的数值以及此后每一个间隔点处的数值将被复制到输出列中。
当到达输入区域的末尾时,抽样将停止。
(在本例题中没有采用);
随机抽样是指直接输入样本数,电脑自行进行抽样,不用受间隔的规律限制;
样本数:
在此输入需要在输出列中显示需要抽取总体中数据的个数。
每个数值是从输入区域中的随机位置上抽取出来的,请注意:
任何数值都可以被多次抽取!
所以抽样所得数据实际上会有可能小于所需数量。
本文末尾给出了一种处理方法;
输出区域:
在此输入对输出表左上角单元格的引用。
所有数据均将写在该单元格下方的单列里。
如果选择的是“周期”,则输出表中数值的个数等于输入区域中数值的个数除以“间隔”。
如果选择的是“随机”,则输出表中数值的个数等于“样本数”;
3.然后单击确定就可以显示结果了(这是电脑自行随机抽样的结果)。
需要说明的情况:
由于随机抽样时总体中的每个数据都可以被多次抽取,所以在样本中的数据一般都会有重复现象,解决此问题有待于程序的完善。
可以使用“筛选”功能对所得数据进行筛选。
选中样本数据列,依次执行“数据”-“筛选”-“高级筛选”,如下图所示。
最后的样本结果如下图所示,请您根据经验适当调整在数据样本选取时的数量设置,以使最终所得样本数量不少于所需数量。
6用Excel做数据分析——移动平均
移动平均就是对一系列变化的数据按照指定的数据数量依次求取平均,并以此作为数据变化的趋势供分析人员参考。
本功能需要使用Excel扩展功能,如果您的Excel尚未安装数据分析,请依次选择“工具”-“加载宏”,在安装光盘支持下加载“分析数据库”。
1.打开原始数据表格,制作本实例的原始数据要求单列,请确认数据的类型。
本实例为压力随时间变化成对数据,在数据分析时仅采用压力数据列。
需要注意的是,因为平均值的求取需要一定的数据量,那么就要求原始数据量不少于求取平均值的个数,在Excel中规定数据量不少于4。
2.选择“工具”-“数据分析”-“直方图”后,出现属性设置框,依次选择:
如果有数据标签可以选择“标志位于第一行”;
输出区域:
移动平均数值显示区域;
间隔:
指定使用几组数据来得出平均值;
图表输出;
原始数据和移动平均数值会以图表的形式来显示,以供比较;
标准误差:
实际数据与预测数据(移动平均数据)的标准差,用以显示预测与实际值的差距。
数字越小则表明预测情况越好。
3.输入完毕后,则可立即生成相应的数据和图表。
从生成的图表上可以看出很多信息。
根据要求,生成的移动平均数值在9:
02时已经达到了15.55MPa,也就是说,包含本次数据在内的四个数据前就已经达到了15MPa,那么说明在8分钟前,也就是8:
56时,系统进入反应阶段;
采用同样的分析方法可以知道,反映阶段结束于9:
10,反应阶段时间区间为8:
56-9:
10,共持续14分钟。
单击其中一个单元格“D6”,可以看出它是“B3-B6”的平均值,而单元格“E11”则是“SQRT(SUMXMY2(B6:
B9,D6:
D9)/4)”,它的意思是B6-B9,D6-D9对应数据的差的平方的平均值再取平方根,也就是数组的标准差。
7用Excel做数据分析——回归分析
在数据分析中,对于成对成组数据的拟合是经常遇到的,涉及到的任务有线性描述,趋势预测和残差分析等等。
很多专业读者遇见此类问题时往往寻求专业软件,比如在化工中经常用到的Origin和数学中常见的MATLAB等等。
它们虽很专业,但其实使用Excel就完全够用了。
我们已经知道在Excel自带的数据库中已有线性拟合工具,但是它还稍显单薄,今天我们来尝试使用较为专业的拟合工具来对此类数据进行处理。
加载成功后,可以在“工具”下拉菜单中看到“数据分析”选项
实例某溶液浓度正比对应于色谱仪器中的峰面积,现欲建立不同浓度下对应峰面积的标准曲线以供测试未知样品的实际浓度。
选择成对的数据列,将它们使用“X、Y散点图”制成散点图。
在数据点上单击右键,选择“添加趋势线”-“线性”,并在选项标签中要求给出公式和相关系数等,可以得到拟合的直线。
由图中可知,拟合的直线是y=15620x+6606.1,R2的值为0.9994。
因为R2>
0.99,所以这是一个线性特征非常明显的实验模型,即说明拟合直线能够以大于99.99%地解释、涵盖了实测数据,具有很好的一般性,可以作为标准工作曲线用于其他未知浓度溶液的测量。
为了进一步使用更多的指标来描述这一个模型,我们使用数据分析中的“回归”工具来详细分析这组数据。
在选项卡中显然详细多了,注意选择X、Y对应的数据列。
“常数为零”就是指明该模型是严格的正比例模型,本例确实是这样,因为在浓度为零时相应峰面积肯定为零。
先前得出的回归方程虽然拟合程度相当高,但是在x=0时,仍然有对应的数值,这显然是一个可笑的结论。
所以我们选择“常数为零”。
“回归”工具为我们提供了三张图,分别是残差图、线性拟合图和正态概率图。
重点来看残差图和线性拟合图。
在线性拟合图中可以看到,不但有根据要求生成的数据点,而且还有经过拟和处理的预测数据点,拟合直线的参数会在数据表格中详细显示。
本实例旨在提供更多信息以起到抛砖引玉的作用,由于涉及到过多的专业术语,请各位读者根据实际,在具体使用中另行参考各项参数,此不再对更多细节作进一步解释。
残差图是有关于世纪之与预测值之间差距的图表,如果残差图中的散点在中州上下两侧零乱分布,那么拟合直线就是合理的,否则就需要重新处理。
更多的信息在生成的表格中,详细的参数项目完全可以满足回归分析的各项要求。
下图提供的是拟合直线的得回归分析中方差、标准差等各项信息。
 升级会员
升级会员 