中国科学院大学现代信息检索课后习题答案Word格式文档下载.docx
《中国科学院大学现代信息检索课后习题答案Word格式文档下载.docx》由会员分享,可在线阅读,更多相关《中国科学院大学现代信息检索课后习题答案Word格式文档下载.docx(22页珍藏版)》请在冰豆网上搜索。
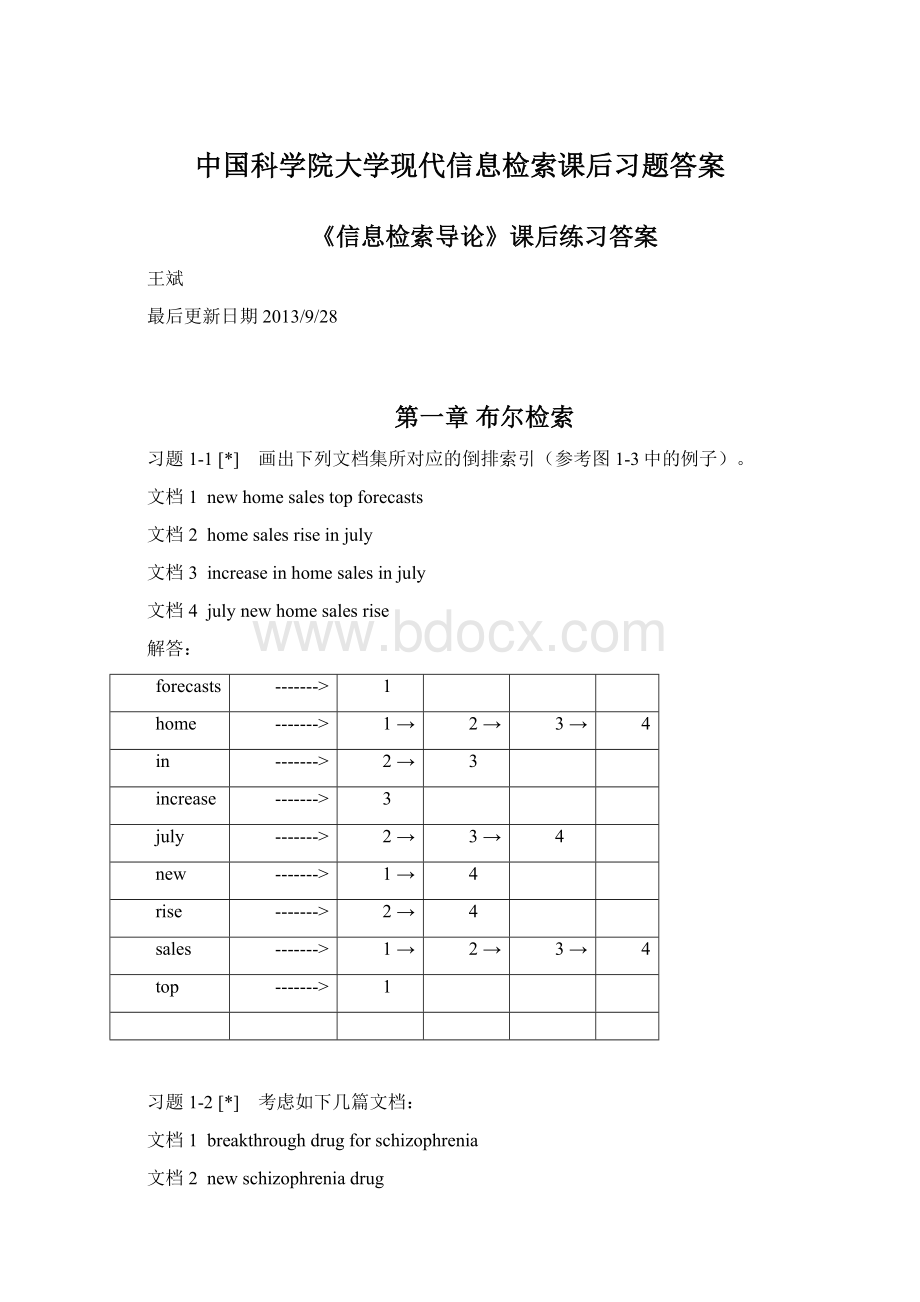
3
increase
july
new
rise
sales
2→
top
习题1-2[*] 考虑如下几篇文档:
文档1breakthroughdrugforschizophrenia
文档2newschizophreniadrug
文档3newapproachfortreatmentofschizophrenia
文档4newhopesforschizophreniapatients
a.画出文档集对应的词项—文档矩阵;
文档1
文档2
文档3
文档4
approach
breakthrough
drug
for
hopes
of
patients
schizophrenia
treatment
b.画出该文档集的倒排索引(参考图1-3中的例子)。
参考a。
习题1-3[*] 对于习题1-2中的文档集,如果给定如下查询,那么返回的结果是什么?
a.schizophreniaANDdrug
{文档1,文档2}
b.forANDNOT(drugORapproach)
{文档4}
习题1-4[*]对于如下查询,能否仍然在O(x+y)次内完成?
其中x和y分别是Brutus和Caesar所对应的倒排记录表长度。
如果不能的话,那么我们能达到的时间复杂度是多少?
a.BrutusANDNOTCaesar
b.BrutusORNOTCaesar
a.可以在O(x+y)次内完成。
通过集合的减操作即可。
具体做法参考习题1-11。
b.不能。
不可以在O(x+y)次内完成。
因为NOTCaesar的倒排记录表需要提取其他所有词项对应的倒排记录表。
所以需要遍历几乎全体倒排记录表,于是时间复杂度即为所有倒排记录表的长度的和N,即O(N)或者说O(x+N-y)。
习题1-5[*]将倒排记录表合并算法推广到任意布尔查询表达式,其时间复杂度是多少?
比如,对于查询
c.(BrutusORCaesar)ANDNOT(AntonyORCleopatra)
我们能在线性时间内完成合并吗?
这里的线性是针对什么来说的?
我们还能对此加以改进吗?
时间复杂度为O(qN),其中q为表达式中词项的个数,N为所有倒排记录表长度之和。
也就是说可以在词项个数q及所有倒排记录表长度N的线性时间内完成合并。
由于任意布尔表达式处理算法复杂度的上界为O(N),所以上述复杂度无法进一步改进。
习题1-6[**] 假定我们使用分配律来改写有关AND和OR的查询表达式。
a.通过分配律将习题1-5中的查询写成析取范式;
b.改写之后的查询的处理过程比原始查询处理过程的效率高还是低?
c.上述结果对任何查询通用还是依赖于文档集的内容和词本身?
a.析取范式为:
(BrutusAndNotAnthonyAndNotCleopatra)OR(CaesarANDNOTAnthonyANDNOTCleopatra)
b.这里的析取范式处理比前面的合取范式更有效。
这是因为这里先进行AND操作(括号内),得到的倒排记录表都不大,再进行OR操作效率就不会很低。
而前面需要先进行OR操作,得到的中间倒排记录表会更大一些。
c.上述结果不一定对,比如两个罕见词A和B构成的查询(AORB)ANDNOT(HONGORKONG),假设HONGKONG一起出现很频繁。
此时合取方式可能处理起来更高效。
如果在析取范式中仅有词项的非操作时,b中结果
不对。
习题1-7[*] 请推荐如下查询的处理次序。
d.(tangerineORtrees)AND(marmaladeORskies)AND(kaleidoscopeOReyes)
其中,每个词项对应的倒排记录表的长度分别如下:
词项倒排记录表长度
eyes213312
kaleidoscope87009
marmalade107913
skies271658
tangerine46653
trees316812
由于:
(tangerineORtrees)→46653+316812=363465
(marmaladeORskies)→107913+271658=379571
(kaleidoscopeOReyes)→87009+213312=30321
所以推荐处理次序为:
(kaleidoscopeOReyes)AND(tangerineORtrees)AND(marmaladeORskies)
习题1-8[*]对于查询
e.friendsANDromansAND(NOTcountrymen)
如何利用countrymen的文档频率来估计最佳的查询处理次序?
特别地,提出一种在确定查询顺序时对逻辑非进行处理的方法。
令friends、romans和countrymen的文档频率分别为x、y、z。
如果z极高,则将N-z作为NOTcountrymen的长度估计值,然后按照x、y、N-z从小到大合并。
如果z极低,则按照x、y、z从小到大合并。
习题1-9[**] 对于逻辑与构成的查询,按照倒排记录表从小到大的处理次序是不是一定是最优的?
如果是,请给出解释;
如果不是,请给出反例。
不一定。
比如三个长度分别为x,y,z的倒排记录表进行合并,其中x>
y>
z,如果x和y的交集为空集,那么有可能先合并x、y效率更高。
习题1-10[**] 对于查询xORy,按照图1-6的方式,给出一个合并算法。
1answer<
-()
2whilep1!
=NILandp2!
=NIL
3doifdocID(p1)=docID(p2)
4thenADD(answer,docID(p1))
5p1<
-next(p1)
6p2<
-next(p2)
7elseifdocID(p1)<
docID(p2)
8thenADD(answer,docID(p1))
9p1<
10elseADD(answer,docID(p2))
11p2<
12ifp1!
=NIL//x还有剩余
13thenwhilep1!
=NILdoADD(answer,docID(p1))
14elsewhilep2!
=NILdoADD(answer,docID(p2))
15return(answer)
习题1-11[*]如何处理查询xANDNOTy?
为什么原始的处理方法非常耗时?
给出一个针对该查询的高效合并算法。
由于NOTy几乎要遍历所有倒排表,因此如果采用列举倒排表的方式非常耗时。
可以采用两个有序集合求减的方式处理xANDNOTy。
算法如下:
Meger(p1,p2)
1answer()
3doifdocID(p1)=docID(p2)
4thenp1←next(p1)
5p2←next(p2)
6elseifdocID(p1)<
7thenADD(answer,docID(p1))
8p1←next(p1)
9elseADD(answer,docID(p2))
10p2←next(p2)
11ifp1!
12thenwhilep1!
13return(answer)
习题1-12[*] 利用Westlaw系统的语法构造一个查询,通过它可以找到professor、teacher或lecturer中的任意一个词,并且该词和动词explain在一个句子中出现,其中explain以某种形式出现。
professorteacherlecturer/sexplain!
习题1-13[*] 在一些商用搜索引擎上试用布尔查询,比如,选择一个词(如burglar),然后将如下查询提交给搜索引擎
(i)burglar;
(ii)burglarANDburglar;
(iii)burglarORburglar。
对照搜索引擎返回的总数和排名靠前的文档,这些结果是否满足布尔逻辑的意义?
对于大多数搜索引擎来说,它们往往不满足。
你明白这是为什么吗?
如果采用其他词语,结论又如何?
比如以下查询
(i)knight;
(ii)conquer;
(iii)knightORconquer。
第二章词汇表和倒排记录表
习题2-1[*] 请判断如下说法是否正确。
a.在布尔检索系统中,进行词干还原从不降低正确率。
b.在布尔检索系统中,进行词干还原从不降低召回率。
c.词干还原会增加词项词典的大小。
d.词干还原应该在构建索引时调用,而不应在查询处理时调用。
a错b对c错d错
习题2-7[*] 考虑利用如下带有跳表指针的倒排记录表
和一个中间结果表(如下所示,不存在跳表指针)进行合并操作。
3 5 89 95 97 99 100 101
采用图2-10所示的倒排记录表合并算法,请问:
a.跳表指针实际跳转的次数是多少(也就是说,指针p1的下一步将跳到skip(p1))?
一次,24—>
75
b.当两个表进行合并时,倒排记录之间的比较次数是多少?
【如下答案不一定正确,有人利用程序计算需要21次,需要回到算法,本小题不扣分,下面不考虑重新比较同意对数字】
18次:
<
3,3>
<
5,5>
9,89>
15,89>
<
24,89>
75,89>
92,89>
81,89>
84,89>
89,89>
92,95>
115,95>
96,95>
96,97>
 升级会员
升级会员 