OpenCV的基础光学字符识别Basic OCR in OpenCVWord文档格式.docx
《OpenCV的基础光学字符识别Basic OCR in OpenCVWord文档格式.docx》由会员分享,可在线阅读,更多相关《OpenCV的基础光学字符识别Basic OCR in OpenCVWord文档格式.docx(12页珍藏版)》请在冰豆网上搜索。
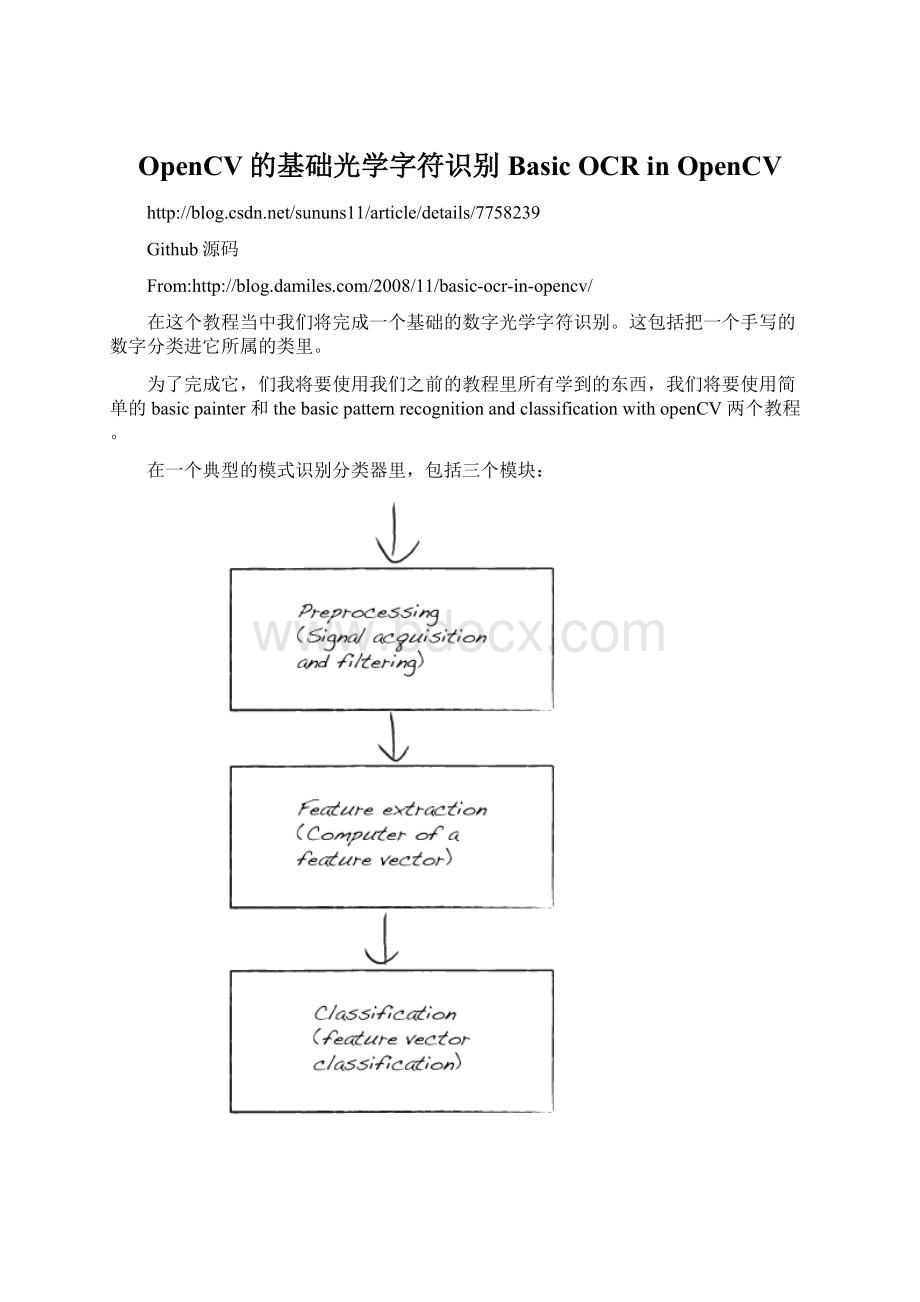
在这个模块我们转换我们处理后的图像为一个特征向量以便于分类,它可能是像素矩阵转换成向量或者获取轮廓编码链的数据表示。
分类模块获取特征向量,并训练我们的系统或者说使用一个分类方法(比如knn)把输入的特征向量分类。
这个基础光学字符识别的流程图如下:
现在我们有由图片组成的一个训练集和一个测试集来训练和测试我们的分类器(knn)。
我们有1000张手写数字的图片,每个数字100张。
我们使用每个数字的50张图片来训练,另外50张来测试我们的系统。
接下来我们要做的第一个工作就是对所有训练集的图片预处理,为了完成它我们创建一个预处理函数。
在这个函数中,我们输入一张图片和我们想要它在处理后得到的新的长和宽,这个函数讲返回一个标准大小的带有边框的图片。
你可以看到更多清楚的处理流程:
预处理代码:
voidfindX(IplImage*imgSrc,int*min,int*max){
inti;
intminFound=0;
CvMatdata;
CvScalarmaxVal=cvRealScalar(imgSrc->
width*255);
CvScalarval=cvRealScalar(0);
//Foreachcolsum,ifsum<
width*255thenwefindthemin
//thencontinuetoendtosearchthemax,ifsum<
width*255thenisnewmax
for(i=0;
i<
imgSrc->
width;
i++){
cvGetCol(imgSrc,&
data,i);
val=cvSum(&
data);
if(val.val[0]<
maxVal.val[0]){
*max=i;
if(!
minFound){
*min=i;
minFound=1;
}
voidfindY(IplImage*imgSrc,int*min,int*max){
height;
cvGetRow(imgSrc,&
*max=i;
CvRectfindBB(IplImage*imgSrc){
CvRectaux;
intxmin,xmax,ymin,ymax;
xmin=xmax=ymin=ymax=0;
findX(imgSrc,&
xmin,&
xmax);
findY(imgSrc,&
ymin,&
ymax);
aux=cvRect(xmin,ymin,xmax-xmin,ymax-ymin);
//printf("
BB:
%d,%d-%d,%d\n"
aux.x,aux.y,aux.width,aux.height);
returnaux;
IplImagepreprocessing(IplImage*imgSrc,intnew_width,intnew_height){
IplImage*result;
IplImage*scaledResult;
CvMatdataA;
CvRectbb;
//boundingbox
CvRectbba;
//boundinbboxmaintainaspectratio
//Findboundingbox
bb=findBB(imgSrc);
//Getboundingboxdataandnowithaspectratio,thexandycanbecorrupted
cvGetSubRect(imgSrc,&
data,cvRect(bb.x,bb.y,bb.width,bb.height));
//Createimagewiththisdatawithwidthandheightwithaspectratio1
//thenwegethighestsizebetwenwidthandheightofourboundingbox
intsize=(bb.width>
bb.height)?
bb.width:
bb.height;
result=cvCreateImage(cvSize(size,size),8,1);
cvSet(result,CV_RGB(255,255,255),NULL);
//Copydedataincenterofimage
intx=(int)floor((float)(size-bb.width)/2.0f);
inty=(int)floor((float)(size-bb.height)/2.0f);
cvGetSubRect(result,&
dataA,cvRect(x,y,bb.width,bb.height));
cvCopy(&
data,&
dataA,NULL);
//Scaleresult
scaledResult=cvCreateImage(cvSize(new_width,new_height),8,1);
cvResize(result,scaledResult,CV_INTER_NN);
//Returnprocesseddata
return*scaledResult;
我们使用basicOCR类的getData函数来创建训练数据和训练类,这个函数获取所有在OCR文件夹下的图片来创建训练数据,OCR文件夹中的每个类是一个文件夹,其中每个文件都是名为cnn.pbm的pbm文件,c是类(0,1,...,9)中的一个,nn是图片的编号(00,01,...,99)。
我们得到的每张图片都是预处理过的了,然后他们将转换成特征向量里的数据以便我们使用。
basicOCR.cpp获取数据代码:
voidbasicOCR:
:
getData()
{
IplImage*src_image;
IplImageprs_image;
CvMatrow,data;
charfile[255];
inti,j;
for(i=0;
classes;
for(j=0;
j<
train_samples;
j++){
//Loadfile
if(j<
10)
sprintf(file,"
%s%d/%d0%d.pbm"
file_path,i,i,j);
else
%s%d/%d%d.pbm"
src_image=cvLoadImage(file,0);
src_image){
printf("
Error:
Cantloadimage%s\n"
file);
//exit(-1);
//processfile
prs_image=preprocessing(src_image,size,size);
//Setclasslabel
cvGetRow(trainClasses,&
row,i*train_samples+j);
cvSet(&
row,cvRealScalar(i));
//Setdata
cvGetRow(trainData,&
IplImage*img=cvCreateImage(cvSize(size,size),IPL_DEPTH_32F,1);
//convert8bitsimageto32floatimage
cvConvertScale(&
prs_image,img,0.0039215,0);
cvGetSubRect(img,&
data,cvRect(0,0,size,size));
CvMatrow_header,*row1;
//convertdatamatrixsizexsizetovecor
row1=cvReshape(&
row_header,0,1);
cvCopy(row1,&
row,NULL);
在处理并且得到训练数据和类以后我们用我们的模型训练这些数据,在这个例子中我们用knn方法:
knn=newCvKNearest(trainData,trainClasses,0,false,K);
现在我们可以测试我们的模型了,并且我们可以使用测试的结果来和其它我们使用的方法比较,又或者我们减小图片大小等等。
这里是在我们的basicOCR类里创建的一个函数,测试函数。
这个函数获取其它500个样本并且用我们选择的方法分类,再检验得到的结果。
test(){
interror=0;
inttestCount=0;
for(j=50;
50+train_samples;
Err
 升级会员
升级会员 