Oracle性能优化总结课件Word格式.docx
《Oracle性能优化总结课件Word格式.docx》由会员分享,可在线阅读,更多相关《Oracle性能优化总结课件Word格式.docx(8页珍藏版)》请在冰豆网上搜索。
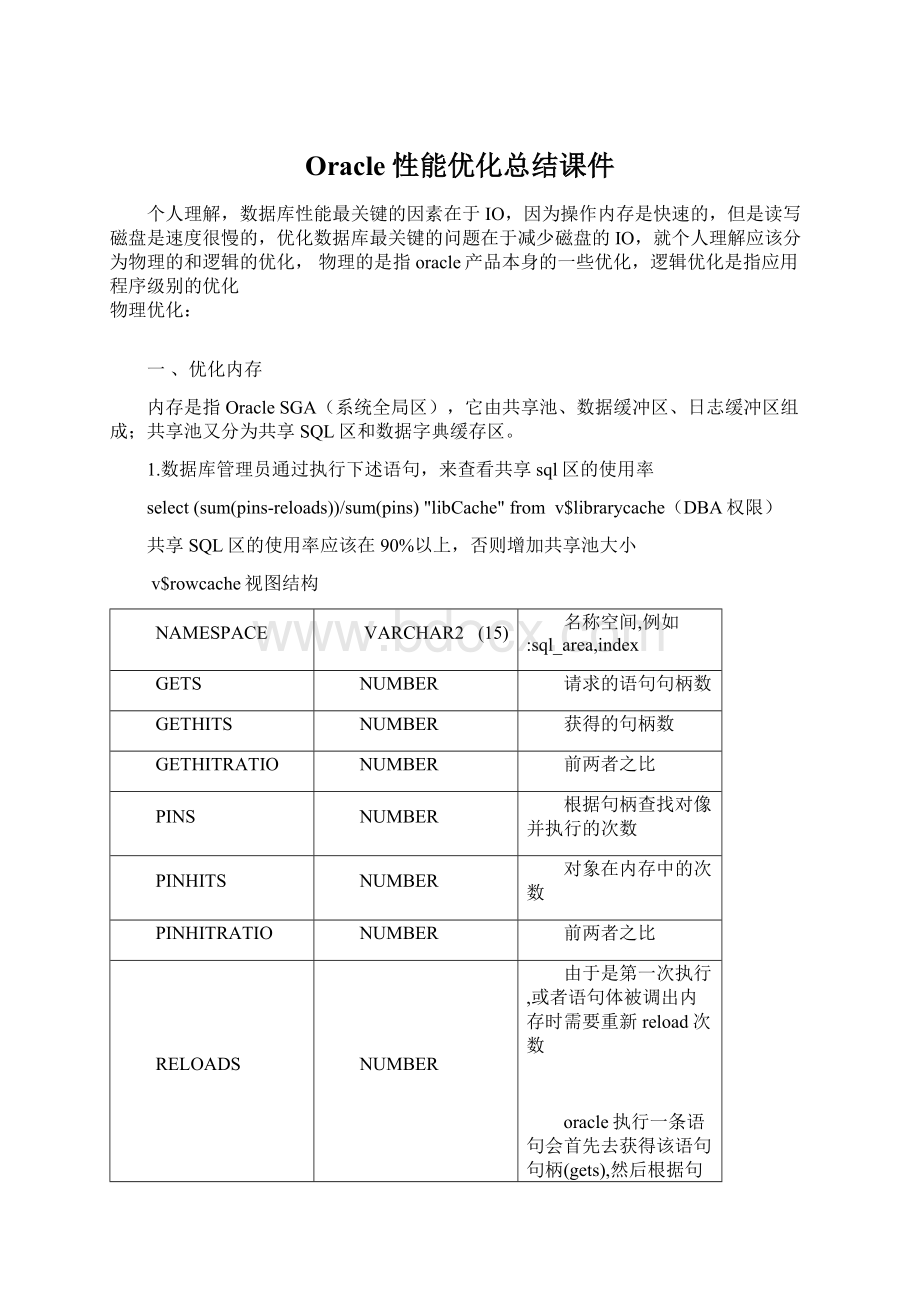
NUMBER
请求的语句句柄数
GETHITS
获得的句柄数
GETHITRATIO
前两者之比
PINS
根据句柄查找对像并执行的次数
PINHITS
对象在内存中的次数
PINHITRATIO
RELOADS
由于是第一次执行,或者语句体被调出内存时需要重新reload次数
oracle执行一条语句会首先去获得该语句句柄(gets),然后根据句柄查找对应的语句,对像(pins)执行,如果该语句体因为某些因为没有在内存中则需要重
载语句体(reloads)
所以reloads最好不要超过1%,sum(pinhits)/sum(pins)要达到95%以上.sum(gethits)/sum(gets)命中率也应在95%以上.
2.数据库管理员可以执行下述语句,查看数据字典缓冲区的使用率
(sum
(gets-getmisses-usage-fixed))/sum(gets)
Row
Cache"
v$rowcache(DBA权限)
数据字典缓冲区也应该在90%以上,否则增加共享池大小。
本视图显示数据字典缓存(也叫rowcache)的各项统计。
每一条记录包含不同类型的数据字典缓存数据统计,注意数据字典缓存有层次差别,因此同样的缓存名称可能不止一次出现
V$ROWCACHE视图结构
PARAMETER
缓存名
COUNT
缓存项总数
USAGE
包含有效数据的缓存项数
请求总数
GETMISSES
请求失败数
SCANS
扫描请求数
SCANMISSES
扫描请求失败次数
MODIFICATIONS
添加、修改、删除操作数
DLM_REQUESTS
DLM请求数
DLM_CONFLICTS
DLM冲突数
DLM_RELEASES
DLM释放数
3.管理员可以通过下述语句来查看数据缓冲区的使用情况
name,value
v$sysstat
where
name
in
('
db
block
gets'
'
consistent
physical
reads'
);
数据缓冲区使用命中率(physical
reads除以db
gets加consistent
gets之和)一定要小于10%,否则需要增加数据缓冲区大小
4.管理员可以通过执行下述语句,查看日志缓冲区的使用情况
selectname,valuefromv$sysstatwherenamein('
redoentries'
'
redologspacerequests'
)
根据查询出的结果可以计算出日志缓冲区的申请失败率:
requests除以entries
申请失败率应该解决与0,否则说明日志缓冲区开设太小,需要增加Oracle数据库的日志缓冲区
二、物理I/0的优化
1.在磁盘上建立数据文件前首先运行磁盘碎片整理程序
为了安全地整理磁盘碎片,需关闭打开数据文件的实例,并且停止服务。
如果有足够的连续磁盘空间建立数据文件,那么就容易避免数据文件产生碎片。
2.不要使用磁盘压缩(Oracle文件不支持磁盘压缩)
3.不要使用磁盘加密
加密像磁盘压缩一样加了一个处理层,降低磁盘读写速度。
如果担心自己的数据可能泄露,可以使用dbms_obfuscation包和labelsecurity选择性地加密数据的敏感部分
4.使用RAID
raid使用应注意:
选择硬件raid超过软件raid;
日志文件不要放在raid5卷上,因为raid5读性能高而写性能差;
把日志文件和归档日志放在与控制文件和数据文件分离的磁盘控制系统上
5.分离页面交换文件到多个磁盘物理卷
跨越至少两个磁盘建立两个页面文件。
可以建立四个页面文件并在性能上受益,确保所有页面文件的大小之和至少是物理内存的两倍。
三、cpu优化调整
1.cpu使用情况
一般unix操作系统,可以使用sar-u命令查看cpu的使用率;
NT操作系统的服务器,可以使用NT的性能管理器来查看CPU的使用率
出现CPU资源不足的情况很多:
SQL语句的重解析、低效率的SQL语句、锁冲突都会引起cpu资源不足
2.查看sql语句的解析情况
数据库管理员可以执行下述语句来查看SQL语句的解析情况:
select*fromv$sysstatwherenamein('
parsetimecpu'
parsetimeelapsed'
parsecount(hard)'
这里parse_time_cpu是系统服务时间,parse_time_elapsed是响应时间。
waite_time=parse_time_elapsed-parse_time_cpu
由此可以得到用户SQL语句平均解析等待时间:
用户SQL语句平均解析等待时间=waitetime/parsecount
数据库管理员还可以通过下述语句,查看低效率的SQL语句
selectbuffer_gets,executlons,sql_textfromv$sqlarea;
优化这些低效率的SQL语句也有助于提高CPU的利用率
3.查看Oracle数据库的冲突情况
数据库管理员可以通过v$system_event数据字典中的"
latchfree"
统计项查看Oracle数据库的冲突情况,如果没有冲突的话,latchfree查询出来没有结果。
如果冲突太大的话,数据库管理员可以降低spin_count参数值,来消除
4.cpu优化
取消屏幕保护、把系统配置为应用服务器、监视系统中消耗中断的硬件、保持最小的安全审计记录、在专门服务器上运行Oracle、禁止非必须的服务
四、网络配置优化
网络配置是性能调整的一项很重要的内容,而且很容易隐藏性能瓶颈
配置网卡使用最快和有效模式、删除不需要的网络协议、优化网络协议绑定顺序,为Oracle禁止或优化文件共享
五、使用CBO优化器
参见本目录CBD优化器
六、合理配置oracle实例参数
序号
参数名称
建议值
说明
1
log_chcckpoint_intcrval
2
log_checkpoint_timeout
3
parallcl_automatic_tuning
TRUE
4
OPEN_CURSORS
1024
5
Dml_locks
10000
6
MTS_servers
10
根据用户数量可适当调整,一般为用户数量的10%
7
cursor_sharing
SIMILAR
七、索引优化(减少IO)
如何某表的某个字段有主键约束和唯一性约束,则Oracle则会自动在相应的约束列上建议唯一索引。
数据库索引主要进行提高访问速度。
建设原则:
1、索引应该经常建在Where子句经常用到的列上。
如果某个大表经常使用某个字段进行查询,并且检索行数小于总表行数的5%。
则应该考虑。
2、对于两表连接的字段,应该建立索引。
经常在某表的一个字段进行OrderBy则也经过进行索引。
3、不应该在小表上建设索引。
优缺点:
索引主要进行提高数据的查询速度。
当进行DML时,会更新索引。
因此索引越多,则DML越慢,其需要维护索引。
因此在创建索引及DML需要权衡。
创建索引:
单一索引:
CreateIndex<
Index-Name>
On<
Table_Name>
(Column_Name);
复合索引:
CreateIndexi_deptno_jobonemp(deptno,job);
—>
在emp表的deptno、job列建立索引。
select*fromempwheredeptno=66andjob='
sals'
->
走索引。
select*fromempwheredeptno=66ORjob='
将进行全表扫描。
不走索引
select*fromempwheredeptno=66->
select*fromempwherejob='
进行全表扫描、不走索引。
如果在where子句中有OR操作符或单独引用Job列(索引列的后面列)则将不会走索引,将会进行全表扫描。
4.分析表与索引(analyze不会重建索引)
analyzetabletablenamecomputestatistics
等同于analyzetabletablenamecomputestatisticsfortableforallindexesforallcolumns
fortable的统计信息存在于视图:
user_tables、all_tables、dba_tables
forallindexes的统计信息存在于视图:
user_indexes、all_indexes、dba_indexes
forallcolumns的统计信息存在于视图:
user_tab_columns、all_tab_columns、dba_tab_columns
注:
分析表与索引见AnalyzeAllTable存储过程
5、一般来讲可以采用以下三种方式来手工分析索引。
analyzeindexidx_tvalidatestructure:
analyzeindexidx_tcomputestatistics:
analyzeindexidx_testimatestatisticssample10percent
1)analyzeindexidx_tvalidatestructure:
这段分析语句是用来分析索引的block中是否有坏块儿,那么根据分析我们可以得到索引的结构数据,这些数据会保留到
index_stats中,来判断这个索引是否需要rebuild.需要注意的是这样的分析是不会收集索引的统计信息的。
2)validatestructure有二种模式:
online,offline,一般来讲默认的方式是offline。
当以offline的模式analyze索引时,会对table加一个表级共享锁,
 升级会员
升级会员 