第七章软件作课件.docx
《第七章软件作课件.docx》由会员分享,可在线阅读,更多相关《第七章软件作课件.docx(19页珍藏版)》请在冰豆网上搜索。
第七章软件作课件
第七章软件操作课件
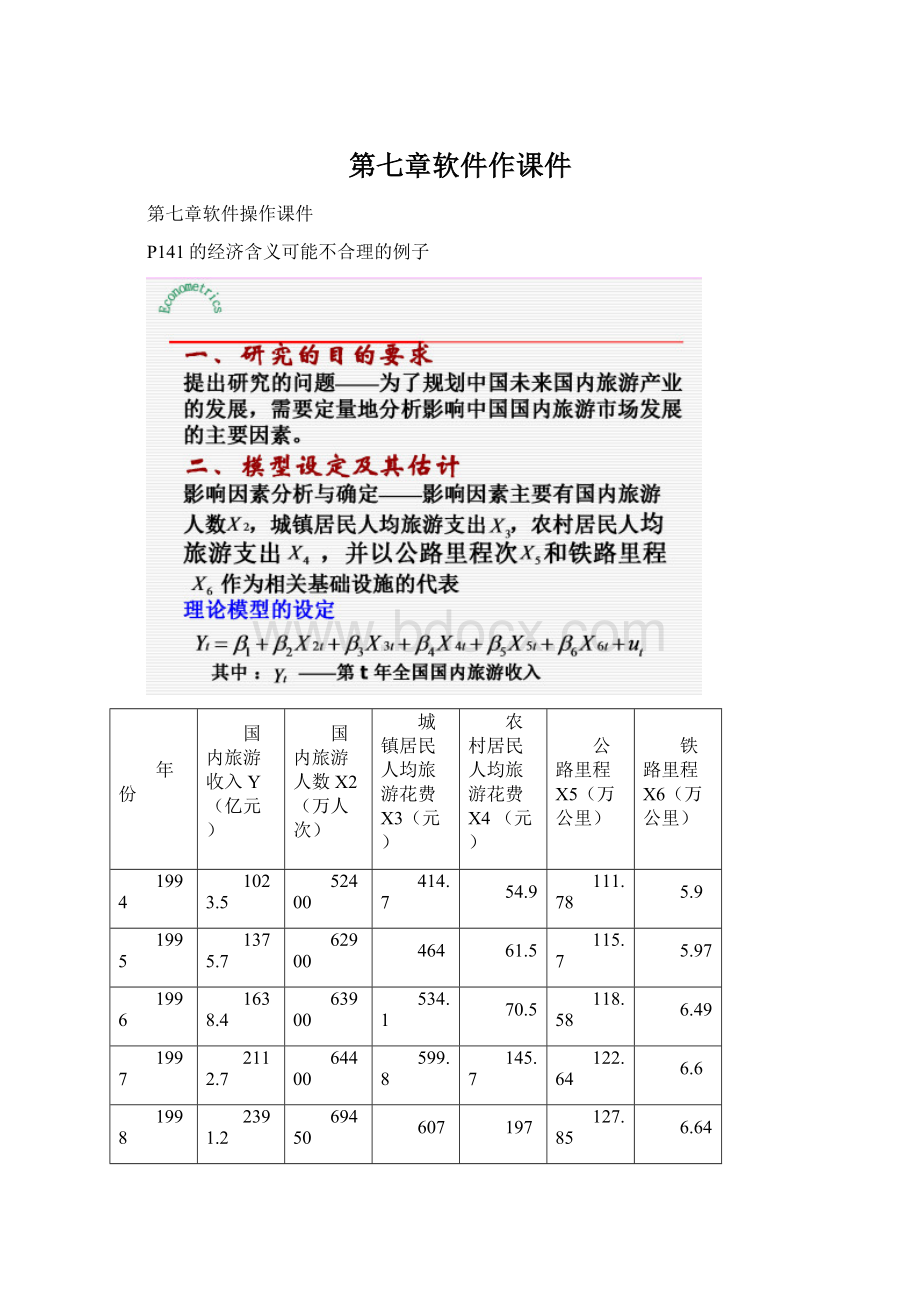
P141的经济含义可能不合理的例子
年份
国内旅游收入Y(亿元)
国内旅游人数X2(万人次)
城镇居民人均旅游花费X3(元)
农村居民人均旅游花费X4(元)
公路里程X5(万公里)
铁路里程X6(万公里)
1994
1023.5
52400
414.7
54.9
111.78
5.9
1995
1375.7
62900
464
61.5
115.7
5.97
1996
1638.4
63900
534.1
70.5
118.58
6.49
1997
2112.7
64400
599.8
145.7
122.64
6.6
1998
2391.2
69450
607
197
127.85
6.64
1999
2831.9
71900
614.8
249.5
135.17
6.74
2000
3175.5
74400
678.6
226.6
140.27
6.87
2001
3522.4
78400
708.3
212.7
169.8
7.01
2002
3878.4
87800
739.7
209.1
176.52
7.19
2003
3442.3
87000
684.9
200
180.98
7.3
2004
4710.7
110200
731.8
210.2
187.07
7.44
2005
5285.9
121200
737.1
227.6
193.05
7.54
2006
6229.74
139400
766.4
221.9
345.7
7.71
2007
7770.62
161000
906.9
222.5
358.37
7.8
P142侦察方法,数据使用table7-1.wf1,首先做简单相关系数
注意不能包含y,因为多重共线性是x之间有关系,而与y有关系才用来做解释变量的。
点击View菜单
得到
显然有很多大于0.8的相关系数,注意对角线全是1,因为变量自身的相关系数是1,而上下三角是一样的,因为相关系数与顺序无关,所以只看下三角即可。
而Excel做出来的相关系数则只有下三角。
如果在工具菜单中不见数据分析菜单,则要先加载宏,加载分析工具库
这样就在工具菜单可以看到数据分析了,
输入区域选定所有X,即解释变量,不要包含Y被解释变量。
得到
国内旅游人数X2(万人次)
城镇居民人均旅游花费X3(元)
农村居民人均旅游花费X4(元)
公路里程X5(万公里)
铁路里程X6(万公里)
国内旅游人数X2(万人次)
1
城镇居民人均旅游花费X3(元)
0.867192
1
农村居民人均旅游花费X4(元)
0.566024
0.811726
1
公路里程X5(万公里)
0.945539
0.805129
0.487669
1
铁路里程X6(万公里)
0.891303
0.956903
0.790144
0.812921
1
P146的VIF法,使用SPSS
点击统计量
共线性诊断勾选
然后确定,在输出窗口看到
系数a
模型
非标准化系数
标准系数
t
Sig.
共线性统计量
B
标准误差
试用版
容差
VIF
1
(常量)
-3.497
30.007
-.117
.910
x1
.125
.059
.380
2.119
.067
.115
8.716
x2
.074
.038
.823
1.945
.088
.021
48.411
x3
2.678
1.257
.508
2.130
.066
.065
15.418
x4
3.453
2.451
.537
1.409
.196
.025
39.281
x5
-4.491
2.215
-1.263
-2.028
.077
.010
105.035
a.因变量:
y
蓝色字体的即为VIF,可见有4个大于10的,即有严重多重共线性。
共线性诊断a
模型
维数
特征值
条件索引
方差比例
(常量)
x1
x2
x3
x4
x5
1
1
5.642
1.000
.00
.00
.00
.00
.00
.00
2
.337
4.093
.00
.00
.00
.00
.00
.00
3
.009
24.651
.01
.00
.16
.04
.48
.01
4
.007
27.764
.03
.00
.09
.68
.00
.01
5
.004
37.192
.10
.03
.27
.00
.15
.36
6
.001
92.160
.86
.97
.48
.27
.37
.62
a.因变量:
y
CI也有大于10的,也一样展示出多重共线性。
P147的逐步回归法,先每个x单独和y做一元回归,根据t检验通过和判定系数的最大化,选定x1最佳一元线性回归,然后x1为基础,加入其他一个变量,一起和y做二元线性回归,则可以发现x3加入是最好的,即二元回归以x1和x3最佳,然后以此两个变量为基础,加入其他x一起做三元回归,发现此时总有t检验不通过现象,则三元回归不合适,即x1和x3的二元回归是最终的最佳模型。
这些过程比较麻烦,可以用SPSS的逐步回归法,结果一样,但是快捷易用。
只要在回归的时候选择逐步回归法
系数a
模型
非标准化系数
标准系数
t
Sig.
共线性统计量
B
标准误差
试用版
容差
VIF
1
(常量)
-90.921
19.329
-4.704
.001
x1
.317
.026
.962
12.152
.000
1.000
1.000
2
(常量)
-39.795
25.016
-1.591
.140
x1
.212
.045
.642
4.670
.001
.222
4.513
x3
1.909
.724
.362
2.637
.023
.222
4.513
a.因变量:
y
在结果窗口就可以看到一元和二元回归最佳结果,最后到二元截止。
如果对于另外一个例题
年份
国内旅游收入Y(亿元)
国内旅游人数X2(万人次)
城镇居民人均旅游花费X3(元)
农村居民人均旅游花费X4(元)
公路里程X5(万公里)
铁路里程X6(万公里)
1994
1023.5
52400
414.7
54.9
111.78
5.9
1995
1375.7
62900
464
61.5
115.7
5.97
1996
1638.4
63900
534.1
70.5
118.58
6.49
1997
2112.7
64400
599.8
145.7
122.64
6.6
1998
2391.2
69450
607
197
127.85
6.64
1999
2831.9
71900
614.8
249.5
135.17
6.74
2000
3175.5
74400
678.6
226.6
140.27
6.87
2001
3522.4
78400
708.3
212.7
169.8
7.01
2002
3878.4
87800
739.7
209.1
176.52
7.19
2003
3442.3
87000
684.9
200
180.98
7.3
2004
4710.7
110200
731.8
210.2
187.07
7.44
2005
5285.9
121200
737.1
227.6
193.05
7.54
2006
6229.74
139400
766.4
221.9
345.7
7.71
2007
7770.62
161000
906.9
222.5
358.37
7.8
则可以做逐步回归如下
得到
系数a
模型
非标准化系数
标准系数
t
Sig.
B
标准误差
试用版
1
(常量)
-1700.756
303.462
-5.605
.000
x2
.059
.003
.982
18.249
.000
2
(常量)
-3489.548
265.127
-13.162
.000
x2
.041
.003
.684
15.263
.000
x3
5.143
.671
.344
7.666
.000
a.因变量:
y
但是如果在选项对话框修改
把前面的0.05改为0.08,即让x进入的标准改为只要其P值小于0.08就可以,而不必要小于0.05,则
则结果窗口中得到
系数a
模型
非标准化系数
标准系数
t
Sig.
B
标准误差
试用版
1
(常量)
-1700.756
303.462
-5.605
.000
x2
.059
.003
.982
18.249
.000
2
(常量)
-3489.548
265.127
-13.162
.000
x2
.041
.003
.684
15.263
.000
x3
5.143
.671
.344
7.666
.000
3
(常量)
-3136.713
295.921
-10.600
.000
x2
.044
.003
.727
16.042
.000
x3
3.666
.957
.245
3.831
.003
x4
2.179
1.103
.076
1.974
.077
a.因变量:
y
此时可以得到三元回归模型为最佳模型,因为x4的P值为0.077,小于0.08,但是大于0.05,所以,前面不能导入,这里可以导入x4。
另外要注意选项里面的两个概率标准,前面那个一定要小于后面那个,这样才能运行下去。
 升级会员
升级会员 