HIVE安装使用说明.docx
《HIVE安装使用说明.docx》由会员分享,可在线阅读,更多相关《HIVE安装使用说明.docx(14页珍藏版)》请在冰豆网上搜索。
HIVE安装使用说明
HIVE安装使用说明
一、Hive简介
1.1.Hive是什么
Hadoop作为分布式运算的基础架构设施,统计分析需要采用MapReduce编写程序后,放到Hadoop集群中进行统计分析计算,使用起来较为不便,Hive产品采用类似SQL的语句快速实现简单的MapReduce统计,很大程度降低了Hadoop的学习使用成本。
Hive是基于Hadoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供基础的SQL查询功能,可以将SQL语句转换为MapReduce任务运行,而不必开发专门的MapReduce应用,十分适合数据仓库的统计分析。
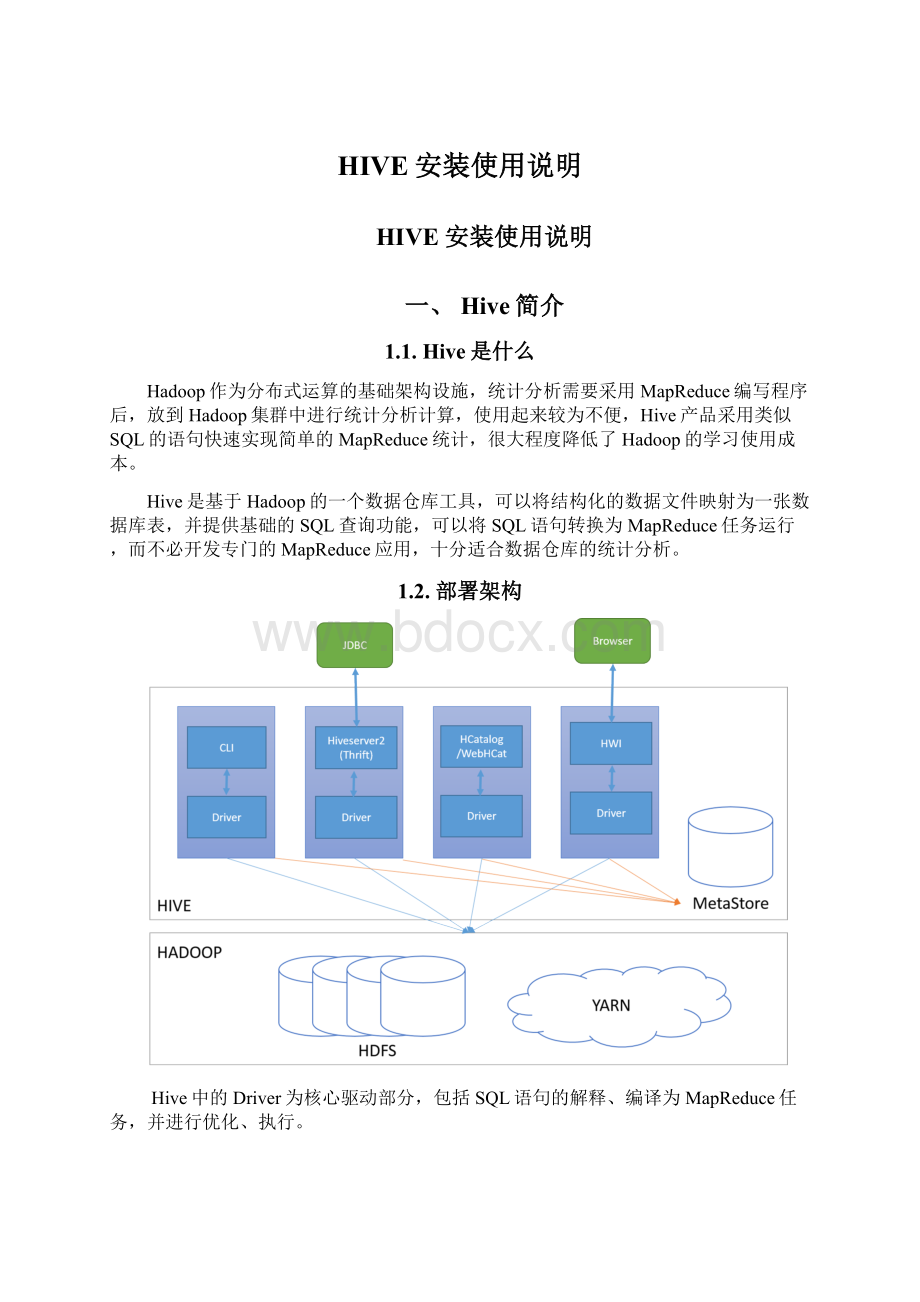
1.2.部署架构
Hive中的Driver为核心驱动部分,包括SQL语句的解释、编译为MapReduce任务,并进行优化、执行。
Hive用户访问包括4种运行和访问方式,一是CLI客户端;二是HiveServer2和Beeline方式;三是HCatalog/WebHCat方式;四是HWI方式。
其中CLI、Beeline均为控制台命令行操作模式,区别在于CLI只能操作本地Hive服务,而Beeline可以通过JDBC连接远程服务。
HiveServer2为采用Thrift提供的远程调用接口,并提供标准的JDBC连接访问方式。
HCatalog是Hadoop的元数据和数据表的管理系统,WebHCat则提供一条Restful的HCatalog远程访问接口,HCatalog的使用目前资料很少,尚未充分了解。
HWI是HiveWebInterface的简称,可以理解为CLI的WEB访问方式,因当前安装介质中未找到HWI对应的WAR文件,未能进行使用学习。
Hive在运行过程中,还需要提供MetaStore提供对元数据(包括表结构、表与数据文件的关系等)的保存,Hive提供三种形式的MetaStore:
一是内嵌Derby方式,该方式一般用演示环境的搭建;二是采用第三方数据库进行保存,例如常用的MySQL等;三是远程接口方式,及由Hive自身提供远程服务,供其他Hive应用使用。
在本安装示例中采用的第二种方式进行安装部署。
备注:
在本文后续的安装和说明中,所有示例均以HiverServer2、Beeline方式进行。
另:
因Hive在查询时性能较差,后期拟计划采用SPARK或Presto进行替代,因此本安装手册不对Hive的集群方案进行描述。
1.3.环境说明
本安装示例在Ubuntu14.04.3的虚拟器中进行安装,并提前安装配置Hadoop。
机器名
IP地址
安装软件
启用服务
hdfs1
10.68.19.184
Hive
Hadoop
hdfs2
10.68.19.182
Hadoop
hdfs3
10.68.19.183
MySQL
Hadoop
二、MySQL安装配置
2.1.MySQL安装
登录到hdfs3中,安装MySQL服务器。
$sudoapt-getinstallmysql-server
修改my.cfg的配置文件
$sudovi/etc/mysql/my.cfg
修改内容如下:
bind-address =10.68.19.183
:
wq
重新启动mysql服务
$sudoservicemysqlrestart
2.2.创建Hive需要的数据库和用户
$mysql-uroot-p
依次输入以下命令:
#创建hive用户
insertintomysql.user(Host,User,Password)values("localhost","hive",password("hive"));
#创建数据库
createdatabasehive;
#授权
grantallonhive.*tohive@'%'identifiedby'hive';
grantallonhive.*tohive@'localhost'identifiedby'hive';
flushprivileges;
#退出
exit
三、Hive安装
3.1.下载Hive
从官网(http:
//hive.apache.org/downloads.html)上下载最新的稳定版本地址,并上传到服务器上。
本安装示例采用的版本为apache-hive-1.2.1-bin.tar.gz。
3.2.解压并配置环境变量
解压安装文件到/opt目录
$tar-zxvfapache-hive-1.2.1-bin.tar.gz-C/opt
修改环境变量
$sudovi/etc/profile
修改如下内容
exportHIVE_HOME=/opt/hive-1.2.1
exportPATH="$JAVA_HOME/bin:
$HADOOP_HOME/bin:
$HIVE_HOME/bin:
$PATH"
:
wq
启用配置
$source/etc/profile
3.3.修改配置文件
$cd$HIVE_HOME
$cpconf/hive-default.xml.templateconf/hive-site.xml
$viconf/hive-site.xml
修改以下内容的值
javax.jdo.option.ConnectionURL
jdbc:
mysql:
//10.68.19.183:
3306/hive
JDBCconnectstringforaJDBCmetastore
javax.jdo.option.ConnectionDriverName
com.mysql.jdbc.Driver
DriverclassnameforaJDBCmetastore
javax.jdo.option.ConnectionPassword
hive
passwordtouseagainstmetastoredatabase
javax.jdo.option.ConnectionUserName
hive
Usernametouseagainstmetastoredatabase
hive.exec.local.scratchdir
/data/hive/scratach
LocalscratchspaceforHivejobs
hive.downloaded.resources.dir
/data/hive/download
Temporarylocaldirectoryforaddedresourcesintheremotefilesystem.
hive.querylog.location
/data/hive/querylog
LocationofHiveruntimestructuredlogfile
hive.server2.logging.operation.log.location
/data/hive/operation_logs
Topleveldirectorywhereoperationlogsarestoredifloggingfunctionalityisenabled
...
3.4.创建需要的目录
$mkdir/data/hive
$mkdir/data/hive/scratach
$mkdir/data/hive/download
$mkdir/data/hive/querylog
$mkdir/data/hive/operation_logs
3.5.上传MySQL驱动
将mysql-connector-java-5.1.36.jar上传到$HIVE_HOME/lib目录下。
3.6.启动
$hiveserver2
3.7.基本操作验证
$beeline
!
connectjdbc:
hive2:
//hdfs1:
10000
输入当前用户名,密码为空
或者直接输入
$./bin/beeline–ujdbc:
hive2:
//hdfs1:
10000
#查看当前数据库
showdatabases;
#查看所有表
showtables;
#创建表
createtableusers(user_idint,fnamestring,lnamestring);
#插入数据
INSERTINTOusers(user_id,fname,lname)VALUES(1,'john','smith');
INSERTINTOusers(user_id,fname,lname)VALUES(2,'john','doe');
INSERTINTOusers(user_id,fname,lname)VALUES(3,'john','smith');
#查询数据
select*fromuserslimit2;
selectcount
(1)fromusers;
3.8.数据导入示例
示例场景说明:
先将输入导入到tmp_sell_day_corp_cig,再将数据写入sell_day_corp_cig中。
创建表
createtabletmp_sell_day_corp_cig
(
sell_dstring,
cig_codestring,
stat_codestring,
statyearsmallint,
halfyearsmallint,
quartersmallint,
statmonthsmallint,
stattendaysmallint,
statdatesmallint,
cig_provincestrin
 升级会员
升级会员 