人工智能导论实验指导书.docx
《人工智能导论实验指导书.docx》由会员分享,可在线阅读,更多相关《人工智能导论实验指导书.docx(20页珍藏版)》请在冰豆网上搜索。
人工智能导论实验指导书
实验一感知器的MATLAB仿真
感知器(Pereceptron)是一种特殊的神经网络模型,是由美国心理学家
F.Rosenblatt于1958年提出的,一层为输入层,另一层具有计算单元,感知
器特别适合于简单的模式分类问题,也可用于基于模式分类的学习控制和多模态控制中。
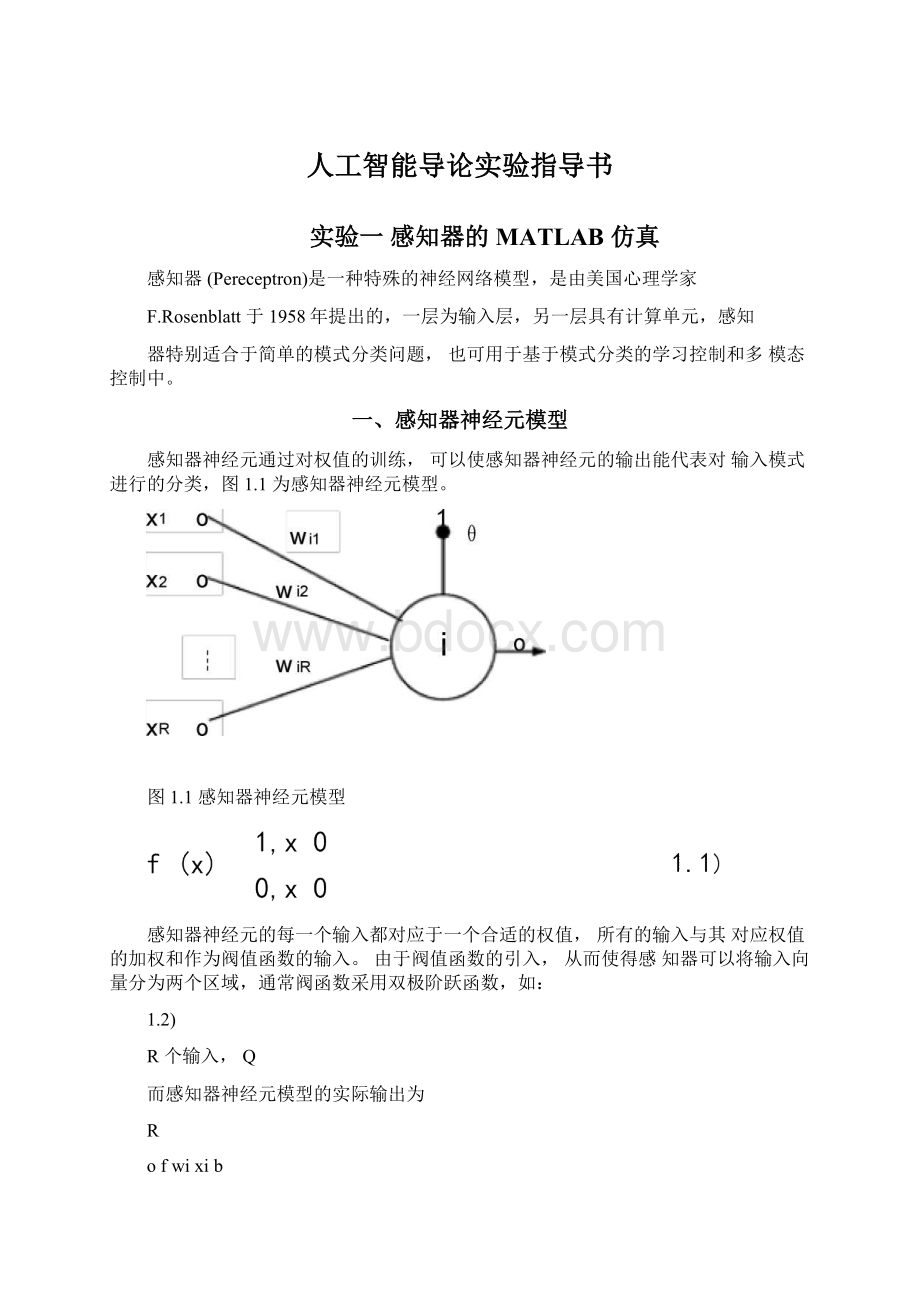
一、感知器神经元模型
感知器神经元通过对权值的训练,可以使感知器神经元的输出能代表对输入模式进行的分类,图1.1为感知器神经元模型。
图1.1感知器神经元模型
感知器神经元的每一个输入都对应于一个合适的权值,所有的输入与其对应权值的加权和作为阀值函数的输入。
由于阀值函数的引入,从而使得感知器可以将输入向量分为两个区域,通常阀函数采用双极阶跃函数,如:
1.2)
R个输入,Q
而感知器神经元模型的实际输出为
R
ofwixib
i1
其中b为阀值
、感知器的网络结构
图1.2所描述的是一个简单的感知器网络结构,输入层有个输出,通过权值wij与s个感知器神经元连接组成的感知器神经网络。
S×1
图1.2感知器神经网络结构
根据网络结构,可以写出感知器处理单元对其输入的加权和操作,即:
Rniwijpj
j1
(1.3)
而其输出ai为
ai=f(ni+bi)
(1.4)
由式2.1易知
1nibi
0
ai
(1.5)
0nibi
0
则当输入ni+bi大于等于0,即有ni≥-bi时,感知器的输出为1;否则输出为0。
上面所述的单层感知器神经网络是不可能解决线性不可分的输入向量分类问题,也不能推广到一般的前向网络中去。
为解决这一问题,我们可以设计多层感知器神经网络以实现任意形状的划分。
图1.3描述了一个双层感知器神经网络。
其工作方式与单层感知器网络一样,只不过是增加了一层而已,具体的内容这里不做讨论。
图1.3感知器神经网络结构
三、感知器神经网络的学习规则
感知器的学习规则主要是通过调整网络层的权值和阀值以便能够地网络的输入向量进行正确的分类。
如图1.2所示的输入向量P、输出和量a和目标向量为t的感知器神经网络,感知器的学习规则是根据以下输出矢量a可能出现的几种情况未进行参与调整的:
1)如果第i个神经元的输出是正确的,即有ai=t1,则与第i个神经元联接的权值和阀值保持不变。
2)如果第i个神经元的输出是不正确,应该有两种情况。
i)实际输出为0,而理想输出为1,即有ai=0,而ti=1,则所有的输入j对权值和阀值进行调整,修正值Δw1j=pj,Δbj=1。
ii)实际输出为1,而期望输出为0,即有ai=1,而ti=0,则对所有的输入j进行权值和阀值调整,Δw1j=-pj,Δbi=-1。
基于感知器误差e=t-a,感知器学习规则可望写为:
Δw1j=ei·pj
可以证明当前输入样本来自线性可分的模式时,上述学习算法在有限步同收敛,这时所得的权值能对所有样本正确分类,这一结论被称为感知器收敛定理。
四、感知器神经网络的训练
要使前向神经网络模型实现某种功能,必须对它进行训练,让它逐步学会要做的事情,并把所学到的知识记忆在网络的权值中。
感知器神经网络的训练是采用由一组样本组成的集合来进行。
在训练期间,将这些样本重复输入,通过调整权值使感知器的输出达到所要求的理想输出。
感知器的训练主要是反复对感知器神经网络进行仿真和学习,最终得到最优的网络阀值和权值。
我们可以用以下方法训练网络:
1)确定我们所解决的问题的输入向量P、目标向量t,并确定各向量
的维数,以及网络结构大小、神经元数目。
假定我们采用图2.2的网络结构。
2)初始化:
权值向量w和阀值向量b分别赋予[-1,+1]之间的随机值,并且给出训练的最大次数。
3)根据输入向量P、最新权值向量w和阀值向量b,计算网络输出向量a。
4)检查感知器输出向量与目标向量是否一致,或者是否达到了最大的训练次数,如果是则结束训练,否则转入(5)。
5)根据感知器学习规则调查权向量,并返回3)。
五、重要的感知器神经网络函数的使用方法
对于感知器的初始化、训练、仿真,在MATLABP神经网络工具箱中
分别提供了init(),trainp()和sim()函数。
1.初始化函数init()
感知器初始化函数init()可得到R个输入,S个神经元数的感知器层的权值和阀值,其调用格式为:
[w,b]=init(R,S)
另外,也可以利用输入向量P和目标向量t来初始化。
[w,b]=init(p,t)
在介绍trainp()函数前,让我们先介绍一下训练的控制参数tp。
tp=[disp_freqmax_epoch]
其中disp_freq指定两次显示间训练次数,缺省值为1;map_epoch指定训练的最大次数,缺省值为100。
2.训练函数trainp()
调用训练函数trainp()函数后又得到新的权值矩阵,阀值向量以及误差te。
trainp()函数所需要的输入变量为:
输入向量P、目标向量t以及网络的初始权值和阀值,训练的控制参数tp。
调用格式为:
[w,b,te]=trainp(w,b,p,t,tp)
由于函数trainp()并不能保证感知器网络所得到的网络权值和阀值达到要求。
因此,在训练完后,要用下列验证语句验证一下。
a=sim(p,w,b);
ifall(a==t),disp(′Itworks!
′),end
假如网络不能成功运行,就可以继续运用trainp()函数对网络进行训练。
经足够的训练后,网络仍达不到要求,那么就应当认真分析一下,感知器网络是否适合于这个问题。
3.仿真函数sim()
sim()函数主要用于计算网络输出。
它的调用比较简单。
a=sim(p,w,b)
六、感知器神经网络应用举例
为了便于消化与理解感知器神经网络的四个问题,下面将给出一个具体的问题进行分析,问题的描述如下:
两种蠓虫Af和Apf已由生物学家W.L.Grogan与w.w.Wirth(1981)根据它们触角长度和翼长中以区分。
见表1.1中9Af蠓和6只Apf蠓的数据。
根据给出的触角长度和翼长可识别出一只标本是Af还是Apf。
1.给定一只Af或者Apf族的蒙,你如何正确地区分它属于哪一族?
2.将你的方法用于触角长和翼中分别为(1.24,1.80)、(1.28,1.84)、
(1.40,2.04)的三个标本
表1.1
Af
触重长
1.24
1.36
1.38
1.378
1.38
1.40
1.48
1.54
1.56
翼长
1.72
1.74
1.64
1.82
1.90
1.70
1.70
1.82
2.08
Apf
触角长
1.14
1.18
1.20
1.26
1.28
1.30
翼长
1.78
1.96
1.86
2.00
2.00
1.96
输入向量为:
p=[1.241.361.381.3781.381.401.481.541.561.141.181.201.261.28
1.30;1.721.741.641.821.901.701.701.822.081.781.961.862.002.001.96]目标向量为:
t=[111111111000000]VectorstobeClassified
图形显示,目标值1对应的用+”、目标值0对应的用“o”来
为解决该问题,利用函数newp构造输入量在[0,2.5]之间的感知器神经网络模型:
net=newp([02.5;02.5],1)
初始化网络:
图1.4样本图形显示
net=init(net)
利用函数adapt调整网络的权值和阀值,直到误差为0时训练结束:
[net,y,e]=adapt(net,p,t)训练结束后可得如图1.5的分类方式,可见感知器网络将样本正确地分成两类:
VectorstobeClassified
)2(P
2
感知器网络训练结束后,问题:
p1=[1.24;1.80]
a1=sim(net,p1)
p2=[1.28;1.84]
a2=sim(net,p2)p3=[1.40;2.04]a3=sim(net,p3)网络仿真结果为:
a1=0a2=0a3=0
实验二线性神经网络的MATLAB实现
线性神经网络是最简单的一种神经元网络,由一个或多个线性神经元构成。
1959年,美国工程师B.widrow和M.Hoft提出自适应线性元件(Adaptivelinearelement,简称Adaline)是线性神经网络的最早典型代表。
它是感知器的变化形式,尤其在修正权矢量的方法上进行了改进,不仅提高了训练收敛速度,而且提高了训练精度。
线性神经网络与感知器神经网络的主要不同之处在于其每个神经元的传递函数为线性函数,它允许输出任意值,而不是象感知器中只能输出0或1。
此外,线性神经网络一般采用Widrow-Hoff(简称W-H)学习规则或者最小场方差(LeastmeanSquare,简称LMS)规则来调整网络的权值和阀值。
线性神经网络的主要用途是线性逼近一个函数表达式,具有联想功能。
另外,它还适用于信号处理滤波、预测、模式识别和控制等方面。
一、线性神经元模型
线性神经元可以训练学习一个与之对应的输入/输出函数关系,或线性逼近任意一个非线性函数,但它不能产生任何非线性的计算特性。
图2.1描述了一个具有R个输入的由纯线性函数组成的线性神经元。
其输入与输出之间
图2.1线性神经元模型由于线性神经网络中神经元的传递函数为线性函数,是简单的比例关系:
a=g(w*p,b)
其中函数g(x)为线性函数。
二、线性神经网络结构
如图2.2描述了一个由S个神经元相并联形成一层网络,这种网络也称为Madaline网络。
图2.2线性神经元网络
W-H学习规则只能训练单层的线性神经网络,但这并不是什么严重问题。
因为对线性神经网络而言,完全可以设计出一个性能完全相当的单层线性神经网络。
三、线性神经学习网络的学习规则
前面我们提到过,线性神经网络采用W-H学习规则。
W-H学习规
则是Widrow是Hoft提出的用来求得权值和阀值的修正值的学习规则。
首先要定义一个线性网络的输出误差函数:
2.1
11
E(w,b)=(t―a)2=(t―w*p)2
22
由式2.1可看出,线性网络具有抛物线型误差函数所形成的误差表面。
所以只有一个误差最小值。
通过W-H学习规则来计算权值和偏差的变化,
E(w,b)的梯
并使网络的误差平方和最小化,总能够训练一个网络的误差趋于最小值。
这可通过沿着相对于误差平方和最速下降方向连续调整网络的权值和阀值来实现。
根据梯度下降法,权矢量的修正值正比于当前位置上
度,对于第i输出节点为:
或表示为:
bii2.4
这里δi定义为第i个输出节点的误差:
δi=ti―ai2.5式2.3称为W-H学习规则。
W-H学习规则的权值变化量正比于网络的输出误差及网络的输入向量。
它不需求导数,所以算法简单,又具有收敛速度快和精度高的优点。
式2.3中的称为学习率,学习率的选取可以适当防止学习过程中产生振荡,提高收敛速度和精度。
四、线性神经网络训练
首先给线性神经网络提供输入向量P,计算线性网络层的输出向量a,
并求得误差e=t―a;
然后比较输出的误差平方和是否小于期望的误差平方和,如果是,则停止训练;否则,采用W-H规则调整权值和阀值,反复进行。
如果经过训练网络不能达到期望目标,可以继续对网络进行训练。
经过足够的训练后,网络还是达不到要求。
那么就仔细地分析一下,所要解决的问题,是否适合于线性神经网络。
五、重要线性神经网络函数的使用方法
在MATLAB神经网络工具箱中提供了基于线性神经网络的初始化函数initlin()、设计函数solvelin()、仿真函数simulin()以及训练函数trainwh和adaptwh。
下面我们将分别介绍多种函数的使用方法。
1.初始化函数initlin()
函数initlin()对线性神经网络初始化时,将权值和阀值取为绝对值很小的数。
其使用格式
[w,b]=initlin(R,S)
R为输入数,S为神经元数。
另外,R和S也可用输入向量P和目标向量t来代替,即[w,b]=initlin(p,t)
2.设计函数solvelin()
与大多数其它神经网络不同,只要已知其输入向量P和目标向量t,就
可以直接设计出线性神经网络使得线性神经网络的权值矩阵误差最小。
其调用命令如下:
[w,b]=solvelin(p,t);
3.仿真函数simulin()
函数simulin()可得到线性网络层的输出a=simulin(p,w,b)
其中a为输出向量,b为阀值向量
4.训练函数trainwh和adaptwh()线性神经网络的训练函数有两种:
trainwh()和adaptwh()。
其中函数trainwh可以对线性神经网络进行离线训练;而函数adaptwh()可以对线性神经网络进行在线自适应训练。
利用trainwh()函数可以得到网络的权矩阵w,阀值向量b,实际训练次数te以及训练过程中网络的误差平方和lr。
[w,b,te,lr]=trainwh(w,b,p,t,tp)输入变量中训练参数tp为:
·tp
(1)指定两次更新显示间的训练次数,其缺省值为25;
·tp
(2)指定训练的最大次数,其缺省值为100;
·tp(3)指定误差平方和指标,其缺省值为0.02;
·tp(4)指定学习速率,其缺省值可由maxlinlr()函数(此函数主要用于计算采用W-H规则训练线性网络的最大的稳定的分辨率)得到。
而利用函数adaptwh()可以得到网络的输出a、误差e、权值矩阵w和阀值向量b。
[a,e,w,b]=adaptwh(w,b,p,t,lr)
输入变量lr为学习速率,学习速率lr为可选参数,其缺省值为1.0。
另外,函数maxlinlr()的调用格式为:
lr=maxlinlr(p);
六、线性神经网络的应用举例
为了理解线性神经网络的理论及其应用问题,下面给出一个实际问题进
行分析,设计一个线性神经网络,用于信号仿真及信号预测。
首先输入信号样本为:
time=1:
0.0025:
5;p=sin(sin(time)*time*10);目标信号为:
t=p*2+2;图形显示样本信号的规律为:
plot(time,p,time,t,'---')title(‘InputandTargetSignals')xlabel(‘Time')ylabel(‘Input__Target__')
3.5
TnputandTargetSignals4
352515052100._tegraT__tupnI
图2.3样本信号
利用输入样本信号和理想输出进行线性神经网络初始化:
[w,b]=initlin(p,t)然后利用函数adaptwh对构造的网络进行训练,lr=0.01;[a,e,w,b]=adaptwh(w,b,p,t,lr)其中lr为学习率,a为网络的输出,e为误差。
仿真结果与目标信号对比分析:
plot(time,a,time,t,‘--')title(‘OutputandTargetSignals')
xlabel(‘Time');
ylabel(‘Output__Target__')
图2.4仿真结果与目标信号对比分析误差分析:
plot(time,e)
holdon;plot([min(time)max(time)],[00],':
r')xlabel('Time');ylabel('Error')
图2.5误差分析
实验三BP神经网络的MATLAB实现
感知器神经网络模型和线性神经网络模型虽然对人工神经网络的发展起了很大的作用,它们的出现也曾掀起了人们研究神经网络的热潮。
但它们有许多不足之处。
人们也曾因此失去了对神经网络研究的信心,但rumelhart、mcclellard和他们的同事洞悉到网络信息处理的重要性,并致力于研究并行分布信息处理方法,探索人类认知的微结构,于1985年发展了BP网络的学习算法。
从而给人工神经网络增添了活力,使其得以全面迅速地恢复发展起来。
BP网络是一种多层前馈神经网络,其神经元的激励函数为S型函数,因此输出量为0到1之间的连续量,它可以实现从输入到输出的任意的非线性映射。
由于其权值的调整是利用实际输出与期望输出之差,对网络的各层连接权由后向前逐层进行校正的计算方法,故而称为反向传播(Back-Propogation)学习算法,简称为BP算法。
BP算法主要是利用输入、输出样本集进行相应训练,使网络达到给定的输入输出映射函数关系。
算法常分为两个阶段:
第一阶段(正向计算过程)由样本选取信息从输入层经隐含层逐层计算各单元的输出值;第二阶段(误差反向传播过程)由输出层计算误差并逐层向前算出隐含层各单元的误差,并以此修正前一层权值。
BP网络主要用于函数逼近、模式识别、分类以及数据压缩等方面。
一、BP网络的网络结构
3.1所示的是一个具有R个输入
BP网络通常至少有一个隐含层,如图和一个隐含层的神经网络模型。
隐含层
PoW1
R×Q
S1×R
1oB1
S1×1
图3.1具有一个隐含层的BP网络结构
感知器与线性神经元的主要差别在于激励函数上:
前者是二值型的,而后者是线性的。
BP网络除了在多层网络上与已介绍过的模型有不同外,其
主要差别也表现在激励函数上。
图3.2所示的两种S型激励函数的图形,可以看到f(·)是连续可微的单调递增函数,这种激励函数的输出特性比较软,其输出状态的取值范围为[0,1]或者[-1,+1],其硬度可以由参数λ来调节。
函数的输入输出关系表达式如下所示:
图3.2sigmoid型函数图形
对于多层网络,这种激励函数所划分的区域不再是线性划分,而是由一个非线性的超平面组成的区域。
因为S型函数具有非线性的大系数功能。
它可以把输入从负无穷到正无穷大的信号变换成-1到+1之间输出,所以采用S型函数可以实现从输入到输出的非线性映射。
二、BP网络学习规则
BP网络最为核心的部分便是网络的学习规则。
用BP算法训练网络时有两种方式:
一种是每输入一样本修改一次权值;另一种是批处理方式,即使组成一个训练周期的全部样本都依次输入后计算总的平均误差。
这里我们主要探讨的是后一种方式。
下面我们给出两层网络结构示意简图4.3,并以此探讨BP算法。
BP网络的学习过程主要由以下四部分组成:
1)输入样本顺传播
输入样本传播也就是样本由输入层经中间层向输出层传播计算。
这一过程主要是
输入样本求出它所对应的实际输出。
①隐含层中第i个神经元的输出为
R
a1if1w1ijpjb1i
j1
i1,2,,s1
(3.1)
②
输出层中第
k个神经元的输出为:
a2k
S1
2w2kia1ib2k,
i1
i1,2,s2
(3.2)
其中f1(·),f2(·)分别为隐含层的激励函数。
2)输出误差逆传播在第一步的样本顺传播计算中我们得到了网络的实际输出值,当这些实际的输出值与期望输出值不一样时,或者说其误差大于所限定的数值时,就要对网络进行校正。
首先,定义误差函数
122
E(w,b)=(tka2k)2(3.3)
2k1
其次,给出权值的变化
①输出层的权值变化
从第i个输入到第k个输出的权值为:
从第j个输入到第
i个输出的权值为:
wij
Ew1ij
ijpj0
1(η为学习系数)
(3.7)
其中:
ijeif1
(3.8)
s2
eikiw2ki
k1
(3.9)
由此可以看出:
①调整是与误差成正比,即误差越大调整的幅度就越大。
②调整量与输入值大小成比例,在这次学习过程中就显得越活跃,所以与其相连的权值的调整幅度就应该越大,③调整是与学习系数成正比。
通常学习系数在0.1~0.8之间,为使整个学习过程加快,又不会引起振荡,可采用变学习率的方法,即在学习初期取较大的学习系数随着学习过程的进行逐渐减小其值。
最后,将输出误差由输出层经中间层传向输入层,逐层进行校正。
3)循环记忆训练为使网络的输出误差尽可能的小,对于BP网络输入的每一组训练样本,一般要经过数百次甚至上万次的反复循环记忆训练,才能使网络记住这一样本模式。
这种循环记忆训练实际上就是反复重复上面介绍的输入模式正向传播和输出误差逆传播过程。
4)学习结束的检验
当每次循环记忆结束后,都要进行学习是否结束的检验。
检验的目的主要是检查输出误差是否已经符合要求。
如果小到了允许的程度,就可以结束整个学习过程,否则还要进行循环训练。
三、BP网络的训练
对BP网络进行训练时,首先要提供一组训练样本,其中每个样本由输入样本和输出对组成。
当网络的所有实际输出与其理想输出一致时,表明训练结束。
否则,通过修正权值,使网络的实际输出与理想输出一致。
实际上针对不同具体情况,BP网络的训练有相应的学习规则,即不同的最优化算法,沿减少理想输出与实际输出之间误差的原则,实现BP网络的函数逼近、向量分类和模式识别。
以图3.3为例来说明BP网络训练的主要过程。
图3.3含一个隐含层的BP网络结构
首先:
网络初始化,构造合理的网络结构(这里我们采用图
 升级会员
升级会员 