1使用kali进行信息收集.docx
《1使用kali进行信息收集.docx》由会员分享,可在线阅读,更多相关《1使用kali进行信息收集.docx(18页珍藏版)》请在冰豆网上搜索。
1使用kali进行信息收集
使用Kalilinux进行渗透
渗透测试即模拟黑客入侵的手段对目标网络进修安全测试,从而发现目标网络的漏洞,对目标网络进行安全加固与漏洞修复。
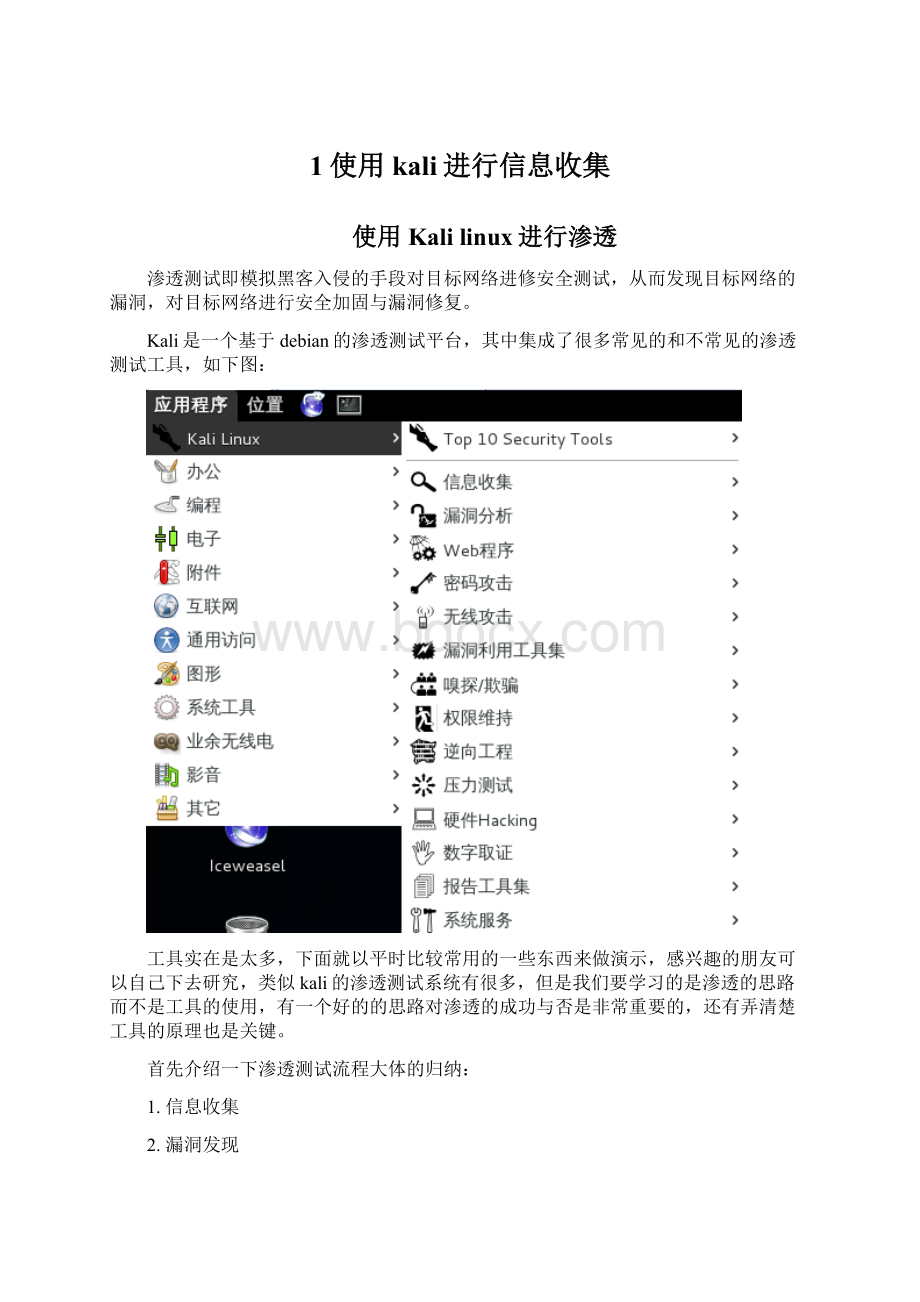
Kali是一个基于debian的渗透测试平台,其中集成了很多常见的和不常见的渗透测试工具,如下图:
工具实在是太多,下面就以平时比较常用的一些东西来做演示,感兴趣的朋友可以自己下去研究,类似kali的渗透测试系统有很多,但是我们要学习的是渗透的思路而不是工具的使用,有一个好的的思路对渗透的成功与否是非常重要的,还有弄清楚工具的原理也是关键。
首先介绍一下渗透测试流程大体的归纳:
1.信息收集
2.漏洞发现
3.漏洞利用
4.维持访问
这是我对于网络渗透常规手段的总结
1.信息收集
信息收集又分为被动信息收集和主动信息收集。
很多人不重视信息收集这一环节,其实信息收集对于渗透来说是非常重要的一步,收集的信息越详细对以后渗透测试的影响越大,毫不夸的说,信息的收集决定着渗透的成功与否。
1.1被动信息收集
被动信息收集也就是说不会与目标服务器做直接的交互、在不被目标系统察觉的情况下,通过搜索引擎、社交媒体等方式对目标外围的信息进行收集,例如:
的whois信息、DNS信息、管理员以及工作人员的个人信息等等。
1.1.1IP查询
想得到一个域名对应的IP地址,只要用ping命令ping一下域名就可以了:
当然,淘宝也使用了CDN,所以上面图片中得到的IP不是真实web服务器的IP地址,那么如何得到真实服务器的IP呢?
告诉大家个小窍门:
不妨把“”去掉,只ping下试试
结果不一样了吧?
因为一级域名没有被解析到cdn服务器上,很多使用了cdn服务器的站点都是这样。
1.1.2whois信息收集
在linux系统下有一个命令:
whois,可以查询目标域名的whois信息,用法很简单,如下图所示:
可以查询到域名以及域名注册人的相关信息,例如:
域名注册商、DNS服务器地址、联系、、、地址等。
也可以使用一些在线工具,如:
whois.chinaz./
1.1.3DNS信息收集
还可以用linux下的host命令去查询dns服务器,具体命令格式为:
host-tnsxxx.
例如对XX域名的dns服务器进行查询,如下图:
同样的用法,还可以查询a记录和mx记录:
Dnsenum是一款域名信息收集工具,很好很强大。
示例用法:
1.dnsenum--enumxxx.
可以看到dnsenum还对域传送漏洞进行了探测,并且尝试从谷歌获取域名,不过在国谷歌被墙大家是知道的,如果想用谷歌需要翻墙了...
2.dnsenum-fwords.txtxxx.
通过-f参数指定字典对目标域名的子域名进行暴力猜解。
更多用法请查看help。
1.1.4旁站查询
旁站也就是和目标处于同一服务器的站点,有些情况下,在对一个进行渗透时,发现安全性较高,久攻不下,那么我们就可以试着从旁站入手,等拿到一个旁站webshell看是否有权限跨目录,如果没有,继续提权拿到更高权限之后回头对目标进行渗透,可以用下面的方式收集旁站:
1.通过bing搜索引擎
使用IP:
%123.123.123.123格式搜索存在于目标ip上的站点,如下图:
这样便能够得到一些同服务器的其它站点。
也可以使用在线工具:
s.tool.chinaz./same
1.1.5C段查询
什么是C段?
每个IP都有四个段,如127.23.33.46,127为A段,23为B段,33为C段,46为D段。
在进行web渗透时,如果目标站点没有拿下,而旁站也一无所获,或者根本没有旁站,服务器也没有发现其它漏洞,怎么办呢?
我们可以通过渗透同一个C段的、提权拿下服务器,也就是尝试拿下D段1~254中的一台服务器,接着网渗透,思路就多了,比如:
ARP欺骗、嗅探?
那么,如何收集C段存在的站点呢?
之前有不少C段查询的工具,由于这些工具多数使用的bing接口,bing接口现在做了限制,需要申请api-key,所以很多工具都不能用了,如果要收集C段站点的话,可以用1.1.4中的方式挨个查询。
1.1.6GoogleHack
搜索引擎真的是个强大的东西,在挖掘信息时你也可以使用一些搜索引擎的语法,对目标的信息进行搜集,也会有一些意想不到的收获,可以用来查找站点敏感路径以及后台地址、查找某人信息、也可以用来搜集子域名等等,用处非常的多,只要自己去构造搜索语法。
网速问题无法开代理,所以访问不了谷歌,就不做演示了,大家可以自行XX去查找googlehack相关文章。
1.2主动信息收集
主动信息收集和被动信息收集相反,主动收集会与目标系统有直接的交互,从而得到目标系统相关的一些情报信息。
1.2.1发现主机
nmap是一个十分强大的网络扫描器,集成了许多插件,也可以自行开发。
下面的一些容我们就用nmap做演示。
首先,使用nmap扫描下网络存在多少台在线主机:
nmap-sP192.168.1.*/nmap-sP192.168.1.0/24
-sP参数和-sn作用相同,也可以把-sP替换为-sn,其含义是使用ping探测网络存活主机,不做端口扫描。
1.2.2端口扫描
-p参数可以指定要扫描目标主机的端口围,如,要扫描目标主机在端口围1~65535开放了哪些端口:
1.2.3指纹探测
指纹探测就是对目标主机的系统版本、服务版本、以及目标站点所用的CMS版本进行探测,为漏洞发现做铺垫。
-O参数可以对目标主机的系统以及其版本做探测:
这样我们就得到目标主机所运行的系统为windowsxp
如下图所示,可以看到目标主机开放了哪些端口,以及对应的服务。
我们还可以加上-sV参数来探测详细的服务版本号:
在对一台主机进行渗透时,服务的版本是很有必要搞清楚的,当知道了服务版本以后,就可以去判断该版本的服务存在哪些漏洞,从而尝试利用该漏洞。
Nmap的其他一些用法:
-A参数可以探测目标系统的系统版本、traceroute信息、还会调用一些脚本
可以看到,详细的服务版本信息、系统指纹信息、还调用脚本探测了目标主机所在的工作组、主机名、系统时间、traceroute等相关的信息。
还有我个人使用NMAP对系统做扫描时,常喜欢用的一个组合是:
Nmap-sS-sV-Oxxx.xxx.xxx.xxx
其中-sS参数的作用是SYN扫描,-sV的作用是探测详细的服务版本信息,-O是探测系统指纹。
效果如下图:
另外,还有些情况,遇到目标系统或者网络对ICMP报文做了限制,而nmap默认情况下会先使用ping去探测目标主机是否存活,如果没有回应的话则不会继续进行端口扫描,遇到这样的情况,可以使用-Pn参数,不对目标主机进行ping检测。
可以使用-h参数查看nmap的详细帮助信息,里面有详细的参数介绍。
WEB指纹探测:
对于WEB站点的指纹探测,就是要得到目标所用的CMS版本、以及web容器的版本。
这里用一个web站点来举例,
假设拿到一个web站点,首先查看站点根目录下有没有robots.txt文件,一般CMS在这个文件里会留下一些信息,如下:
通过Disallow这一项中的路径,就可以判断出是wordpress的后台,这样就得到了该使用的CMS为wordpress,或者留意下部的信息,默认没被修改的情况下可能会留有powerdbywordpress/powerdbydiscuz等字样,这也是获取cms的一种思路。
现在我们知道了CMS为wordpress,那么就用wpscan来探测下该wordpress站点的版本以及使用的插件版本、主题版本等:
如上图所示(两图分别是两个不同的站点),默认不加参数会自动探测到wordpress的版本、插件版本、主题版本、还有web容器的版本信息等。
至于探测WEB容器的指纹信息方法就更多了,比如,随意提交一个错误页面,比如Apache、iis、nginx的默认的错误页面都是不同的,而且不同版本的错误页面也是不同的,如下:
可以看到版本为apache2
再用看一个iis的站点:
可以判断是IIS7.5的错误页面。
也可以用Nmap之类的扫描器对web服务器的版本进行探测,上一章讲过的nmap的-sV参数就可以达到这个目的。
1.2.4web敏感目录扫描
WEB目录扫描也就是通过一些保存着敏感路径的字典(如:
后台路径、在线编辑器路径、上传路径、备份文件等),对于一次渗透来说,对目录进行暴力猜解是前期阶段必不可少的一个步骤。
如果运气好扫到了备份文件之类的,也许会事半功倍。
dirb是一款WEB目录扫描工具,也被集成在kali渗透测试系统中,用法很简单,下面简单做个演示:
目标站点
需要大家平时多收集web敏感路径的字典。
也有爬虫工具,便于帮助渗透者了解目标web的大概结构,webscarab就是一款强大的web爬行工具,也可以做目录爆破用,还有很多其它功能,比如做xss测试等,java开发的gui界面用法非常简单,这里就简单做爬虫演示:
首先打开proxy选项卡中的listener选项卡配置代理端口,IP地址填127.0.0.1,点击start开启代理服务:
接着,打开浏览器,设置代理服务器为127.0.0.1端口为自己在webscarab中设置的端口
配置好代理后,在浏览器中访问目标,然后打开webscarab的spider选项卡,选择起始点的请求(目标站点),点击FecthTree就可以在messages选项卡中看到请求信息
在spider窗格中双击自己目标站点前的文件夹图标就可以查看爬到的目录以及文件
信息收集对于一次渗透来说是非常重要的,收集到的信息越多,渗透的成功几率就越大,前期收集到的这些信息对于以后的阶段有着非常重要的意义。
Writeby:
TaskKilL
Date:
2015/4/15
 升级会员
升级会员 