当前流行的商用芯片.docx
《当前流行的商用芯片.docx》由会员分享,可在线阅读,更多相关《当前流行的商用芯片.docx(10页珍藏版)》请在冰豆网上搜索。
当前流行的商用芯片
1AMDAthlon
LiketheIntelPentiumchip,ofwhichtheAMDAthlonisaclonewithrespecttoIntel'sx86InstructionSetArchitecture,itisfrequentlyusedinclusters.Thereforewediscussthisprocessorherealthoughitisnotusedpresentlyinintegratedparallelsystems.\\TheAthlonprocessorhasmanyfeaturesthatarealsopresentinmodernRISCprocessors:
itsupportsout-of-orderexecution,hasmultiplefloating-pointunits,andcanissueupto9instructionssimultaneously.AblockdiagramoftheprocessorisshowninFigure7
Figure7:
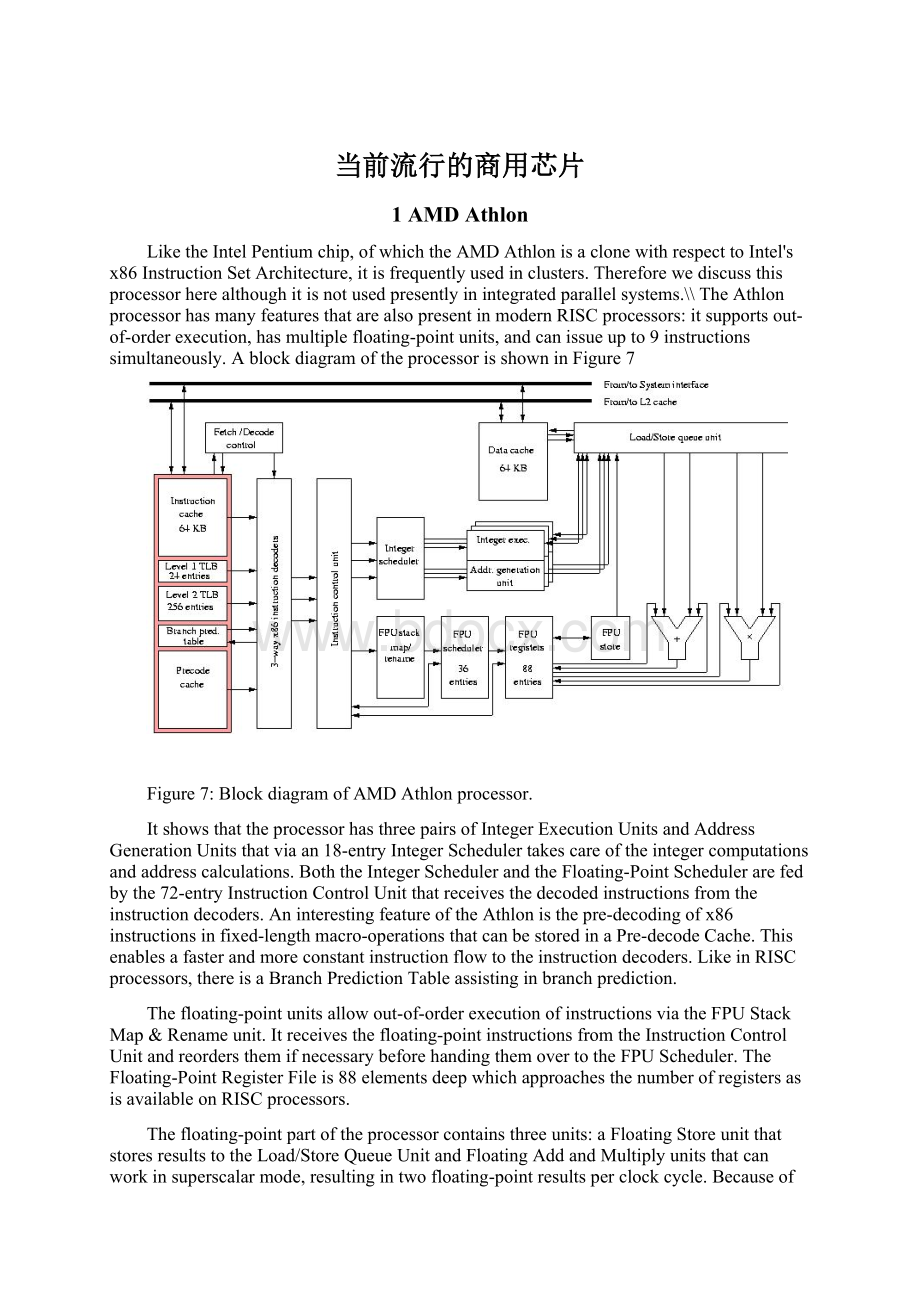
BlockdiagramofAMDAthlonprocessor.
ItshowsthattheprocessorhasthreepairsofIntegerExecutionUnitsandAddressGenerationUnitsthatviaan18-entryIntegerSchedulertakescareoftheintegercomputationsandaddresscalculations.BoththeIntegerSchedulerandtheFloating-PointSchedulerarefedbythe72-entryInstructionControlUnitthatreceivesthedecodedinstructionsfromtheinstructiondecoders.AninterestingfeatureoftheAthlonisthepre-decodingofx86instructionsinfixed-lengthmacro-operationsthatcanbestoredinaPre-decodeCache.Thisenablesafasterandmoreconstantinstructionflowtotheinstructiondecoders.LikeinRISCprocessors,thereisaBranchPredictionTableassistinginbranchprediction.
Thefloating-pointunitsallowout-of-orderexecutionofinstructionsviatheFPUStackMap&Renameunit.Itreceivesthefloating-pointinstructionsfromtheInstructionControlUnitandreordersthemifnecessarybeforehandingthemovertotheFPUScheduler.TheFloating-PointRegisterFileis88elementsdeepwhichapproachesthenumberofregistersasisavailableonRISCprocessors.
Thefloating-pointpartoftheprocessorcontainsthreeunits:
aFloatingStoreunitthatstoresresultstotheLoad/StoreQueueUnitandFloatingAddandMultiplyunitsthatcanworkinsuperscalarmode,resultingintwofloating-pointresultsperclockcycle.BecauseofthecompatibilitywithIntel'sPentiumIIIprocessors,thefloating-pointunitsalsoareabletoexecuteIntelMMXinstructionsandAMD'sown3DNow!
instructions.However,thereisthegeneralproblemthatsuchinstructionsarenotaccessiblefromhigherlevellanguages,likeFortran90orC(++).Bothinstructionsetsaremeantformassiveprocessingofvisualisationdataandonlyallowfor32-bitprecisiontobeused.ThesystembuscomplementingtheAthlonprocessorisalsofasterthanwhatisstandardlyavailableforIntelPIIIprocessors:
200MHzinsteadof133MHz.AMDclaimsthebusspeedcanbescaledtoover400MHz.
Withthecurrentclockfrequencyof1-1.33GHzofthecurrentprocessorstheAthlonisaninterestingalternativeformanyoftheRISCprocessorsthatareavailableatthismoment.
2IntelPentium4
AlthoughPentiumprocessorsarenotappliedinintegratedparallelsystemsthesedays,theyplayamajorroleintheclustercommunityasmostcomputenodesinBeowulfclustersareofthistype.Thereforewebrieflydiscussalsothistypeofprocessor.
Unfortunately,Intelonlyprovidesscantinformationonthisnewprocessor,notevenenoughtoputtogetherareliableblockdiagramoftheprocessor.Still,thereanumberofdistinctivefeatureswithrespecttotheearlierPentiumgenerations.Therearetwomainwaystoincreasetheperformanceofaprocessor:
byraisingtheclockfrequencyandbyincreasingthenumberofinstructionspercycle(IPC).Thesetwoapproachesaregenerallyinconflict:
whenonewantstoincreasetheIPCthechipwillbecomemorecomplicated.Thiswillhaveanegativeimpactontheclockfrequencybecausemoreworkhastobedoneandorganisedwithinthesameclockcycle.VeryseldomlychipdesignerssucceedinraisingbothclockfrequencyandIPCsimultaneously.AlsointhePentium4thiscouldnotbedone.Intelhaschosenforahighclockspeed(initiallyabout40%morethanthatofthePentiumIIIwiththesamefabricationtechnology)whiletheIPCdecreasedby10--20%.Thisstillgivesanetperformancegainevenifotherchangeswouldhavebeenmadetotheprocessor.Tosustaintheveryhighclockratethatthepresentprocessorshave,currently1.7GHz,averydeepinstructionpipelineisrequired.Theinstructionpipelinehasnolessthan20stages,doublethenumberofstagesinthatofthePentiumIII.Althoughthisfavoursahighclockrate,thepenaltyforapipelinemiss(e.g.,abranchmis-predict)ismuchheavierandthereforeIntelhasimprovedthebranchpredictionbyaincreasingthesizeoftheBranchTargetBufferfrom0.5to4KB.Inaddition,thePentium4hasanexecutiontracecachewhichholdspartlydecodedinstructionsofformerexecutiontracesthatcanbedrawnupon,thusforegoingtheinstructiondecodephasethatmightproduceholesintheinstructionpipeline.
Theprimarycacheisquitesmallbytoday'sstandards:
8KB.Thisisagaintoaccommodatethehighclockspee
 升级会员
升级会员 