Oracle数据库备份和恢复操作手册.doc
《Oracle数据库备份和恢复操作手册.doc》由会员分享,可在线阅读,更多相关《Oracle数据库备份和恢复操作手册.doc(13页珍藏版)》请在冰豆网上搜索。
1ORACLE数据库数据备份和恢复操作手册
1.1.ORACLE参数设置
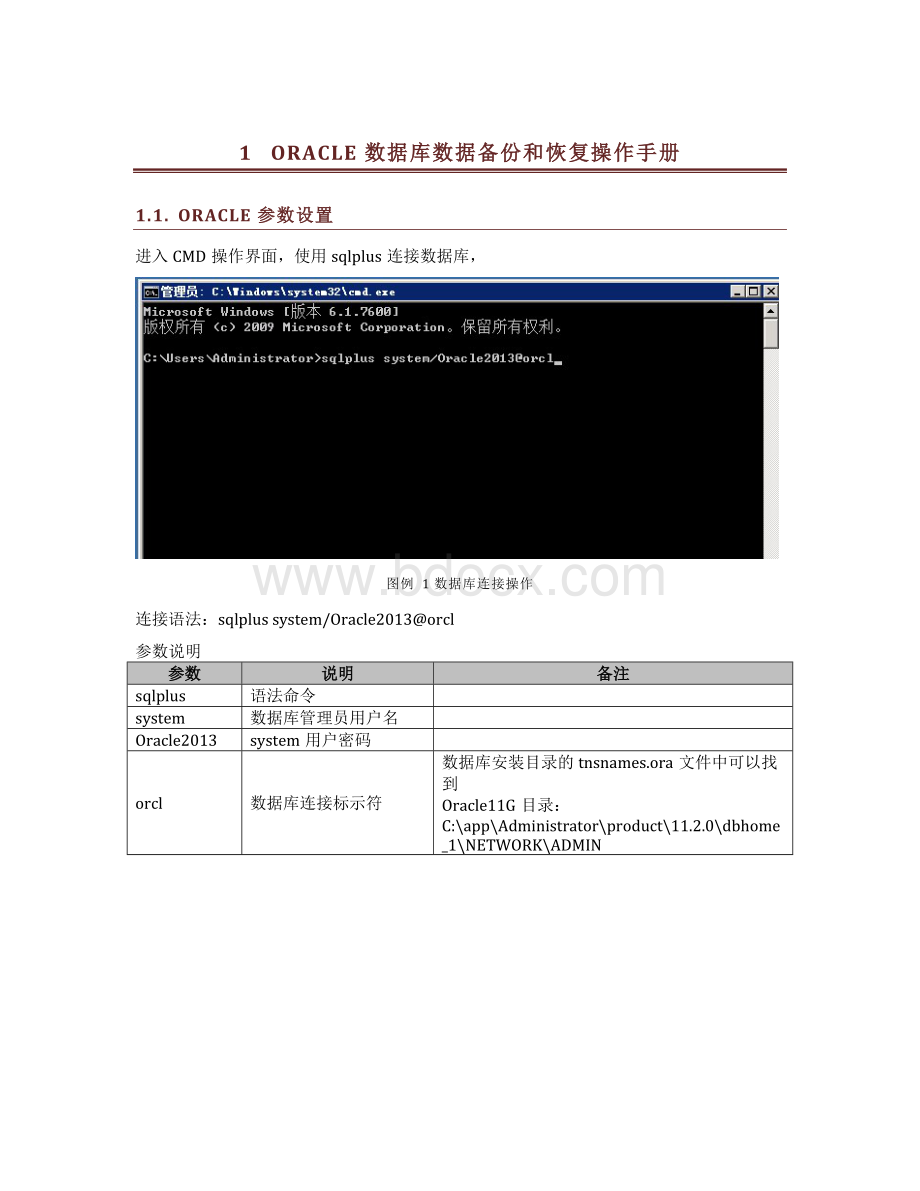
进入CMD操作界面,使用sqlplus连接数据库,
图例1数据库连接操作
连接语法:
sqlplussystem/Oracle2013@orcl
参数说明
参数
说明
备注
sqlplus
语法命令
system
数据库管理员用户名
Oracle2013
system用户密码
orcl
数据库连接标示符
数据库安装目录的tnsnames.ora文件中可以找到
Oracle11G目录:
C:
\app\Administrator\product\11.2.0\dbhome_1\NETWORK\ADMIN
图例2成功连接数据库
环境变量设置(在Sqlplus中执行)
createorreplacedirectoryas‘c:
\tmpdir’;
参数说明
参数
说明
备注
dir_name
路径名称
c:
\tmpdir
文件路径
也可以是另外的随意目录,用单引号括起来。
图例3环境变量设置
1.2.数据备份
备份脚本:
expdpsystem/Oracle2013@orcldirectory=file_pathdumpfile=ARADMIN.datlogfile=ARADMIN.logschemas=ARADMIN
参数说明
参数
说明
备注
expdp
语法命令
system
数据库管理员用户名
Oracle2013
system用户密码
orcl
数据库连接标示符
数据库安装目录的tnsnames.ora文件中可以找到
Oracle11G目录:
C:
\app\Administrator\product\11.2.0\dbhome_1\NETWORK\ADMIN
directory
文件目录名称
导出数据库文件的存放目录
dumpfile
数据库文件名称
导出数据库文件的文件名
logfile
数据库日志文件名称
导出数据库的日志文件名称
schemas
数据库用户
操作:
图例4数据库备份操作
成功导出。
图例5成功导出
1.3.数据恢复
1.3.1.删除ARADMIN用户
1.连接数据库
sqlplussystem/Oracle2013@orcl
图例6连接数据库
2.删除目标数据库中的ARADMIN用户
dropuserARADMINcascade;
图例7成功删除目标数据库中的ARADMIN用户
1.3.2.重新创建ARADMIN用户
1.连接数据库
sqlplussystem/Oracle2013@orcl
图例8连接数据库
2.创建ARADMIN用户
createuserARAdminidentifiedbyAR#Admin#defaulttablespaceARSYSTEMtemporarytablespaceARTMPSPCquotaunlimitedonarsystem;
图例9创建ARADMIN用户
3.赋予数据库权限
grantaltersession,createcluster,createdatabaselink,createsequence,createsession,createsynonym,createtable,createview,createprocedure,createtrigger,queryrewritetoARAdmin;
图例10赋予数据库权限
1.3.3.数据库导入
导入命令:
impdpsystem/Oracle2013@orcldirectory=file_pathdumpfile=ARADMIN20130606.DATlogfile=ARADMIN20130614.logschemas=ARADMIN
图例11数据库导入
导入完成
1.4.EXP/IMP与EXPDP/IMPDP对比
1.0.1运行位置不同
1.0.2EXP/IMP不同模式原理:
exp/imp默认会是传统路径,这种模式下,是用SELECT加数据查询出来,然后写入buffercache,在将这些记录写入evaluatebuffer.最后传到Export客户端,在写入dump文件。
直接路径模式下,数据直接从硬盘读取,然后写入PGA,格式就是export的格式,不需要转换,数据再直接传到export客户端,写入dump文件.这种模式没有经过evaluationbuffer。
少了一个过程,导出速度提高也是很明显.
1.0.3EXPDP/IMPDP不同模式原理:
expdp/impdp默认就是使用直接路径的,所以expdp要比exp快。
NetworkLink这种模式很方便,但是速度是最慢的,因为它是通过insert,select+dblink来实现的。
速度慢也由此可见了。
1.0.4网络和磁盘影响
expdp/impdp是服务端程序,影响它速度的只有磁盘IO。
exp/imp可以在服务端,也可以在客户端。
所以,它受限于网络和磁盘。
1.0.5功能上的区别
更换表空间,用exp/imp的时候,要想更改表所在的表空间,需要手工去处理一下,如altertablexxxmovetablespace_new之类的操作。
用impdp只要用remap_tablespace='tabspace_old':
'tablespace_new'
-----------------------------------
当指定一些表的时候,使用exp/imp时,tables的用法是
tables=('table1','table2','table3')。
expdp/impdp用法是tables='table1','table2','table3'
-----------------------------------
是否要导出数据行
exp(ROWS=Y导出数据行,ROWS=N不导出数据行)
expdpcontent(ALL:
对象+导出数据行,DATA_ONLY:
只导出对象,
METADATA_ONLY:
只导出数据的记录)
======================================================================
1.0.6使用中的优化事项
EXP
和DIRECT=Y配合使用的是RECORDLENGTH参数,它定义了ExportI/O缓冲的大小,作用类似于常规路径导出使用的BUFFER参数。
建议设置RECORDLENGTH参数为最大I/O缓冲,即65535(64kb)。
其用法如下:
如:
expuserid=system/managerfull=ydirect=yrecordlength=65535
file=exp_full.dmplog=exp_full.log
--直接路径不能使用在tablespace-mode
--直接路径不支持query参数,query只能在conventionalpath模式下使用。
--buffer选项只对conventionalpathexp有效。
对于直接路径没有影响。
对
直接路径,应该设置RECORDLENGTH参数。
--对于直接路径下,RECORDLENGTH参数建议设成64k(65535)。
这个值对
性能提高比较大
----------------------------------------------------------------------
IMP
OracleImport进程需要花比Export进程数倍的时间将数据导入数据库。
某些关键时刻,导入是为了应对数据库的紧急故障恢复。
为了减少宕机时间,加快导入速度显得至关重要
(1)避免I/O竞争
Import是一个I/O密集的操作,避免I/O竞争可以加快导入速度。
如果可能,不要在系统高峰的时间导入数据,不要在导入数据时运行job等可能竞争系统资源的操作。
(2)增加排序区
OracleImport进程先导入数据再创建索引,不论INDEXES值设为YES或者NO,主键的索引是一定会创建的。
创建索引的时候需要用到排序区,在内存大小不足的时候,使用临时表空间进行磁盘排序,由于磁盘排序效率和内存排序效率相差好几个数量级。
增加排序区可以大大提高创建索引的效率,从而加快导入速度。
(3)调整BUFFER选项
Imp参数BUFFER定义了每一次读取导出文件的数据量,设的越大,就越减少Import进程读取数据的次数,从而提高导入效率。
BUFFER的大小取决于系统应用、数据库规模,通常来说,设为百兆就足够了。
其用法如下:
impuser/pwdfromuser=user1touser=user2file=/tmp/imp_db_pipe1commit=y
feedback=10000buffer=10240000
(4)使用COMMIT=Y选项
COMMIT=Y表示每个数据缓冲满了之后提交一次,而不是导完一张表提交一次。
这样会大大减少对系统回滚段等资源的消耗,对顺利完成导入是有益的。
(5)使用INDEXES=N选项
前面谈到增加排序区时,说明Imp进程会先导入数据再创建索引。
导入过程中建立用户定义的索引,特别是表上有多个索引或者数据表特别庞大时,需要耗费大量时间。
某些情况下,需要以最快的时间导入数据,而索引允许后建,我们就可以使用INDEXES=N只导入数据不创建索引,从而加快导入速度。
我们可以用INDEXFILE选项生成创建索引的DLL脚本,再手工创建索引。
我们也可以用如下的方法导入两次,
第一次导入数据,第二次导入索引。
其用法如下:
impuser/pwdfromuser=user1touser=user2file=/tmp/imp_db_pipe1commit=y
feedback=10000buffer=10240000ignore=yrows=yindexes=n
-----------------------------------
impuser/pwdfromuser=user1touser=user2file=/tmp/imp_index_pipe1commit=y
feedback=10000buffer=10240000ignore=yrows=nindexes=y
(6)增加LARGE_POOL_SIZE
如果在init.ora中配置了MTS_SERVICE,MTS_DISPATCHERS等参数,tnsnames.ora中又没有(SERVER=DEDICATED)
的配置,那么数据库就使用了共享服务器模式。
在MTS模式下,Exp/Imp操作会用到LARGE_POOL,建议调整LARGE_POOL_SIZE到150M。
检查数据库是否在MTS模式下:
SQL>selectdistinctserverfromv$session;
如果返回值出现none或shared,说明启用了MTS
---------------------------------------------
 升级会员
升级会员 