数据仓库多维数据模型的设计讲课稿Word格式文档下载.docx
《数据仓库多维数据模型的设计讲课稿Word格式文档下载.docx》由会员分享,可在线阅读,更多相关《数据仓库多维数据模型的设计讲课稿Word格式文档下载.docx(12页珍藏版)》请在冰豆网上搜索。
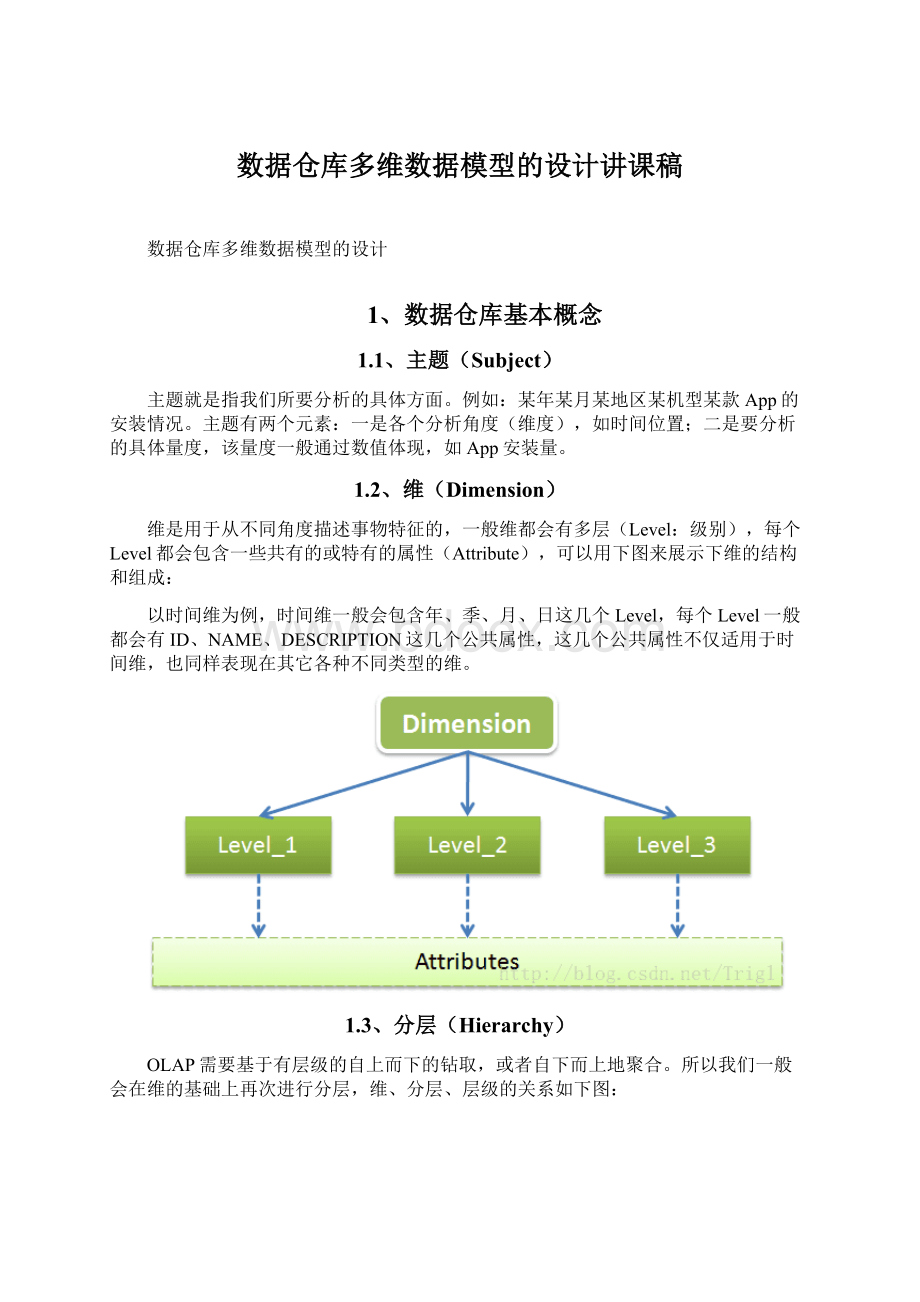
1.6、事实表和维表
事实表是用来记录分析的内容的全量信息的,包含了每个事件的具体要素,以及具体发生的事情。
事实表中存储数字型ID以及度量信息。
维表则是对事实表中事件的要素的描述信息,就是你观察该事务的角度,是从哪个角度去观察这个内容的。
事实表和维表通过ID相关联,如图所示:
1.7、星形/雪花形/事实星座
这三者就是数据仓库多维数据模型建模的模式
上图所示就是一个标准的星形模型。
雪花形就是在维度下面又细分出维度,这样切分是为了使表结构更加规范化。
雪花模式可以减少冗余,但是减少的那点空间和事实表的容量相比实在是微不足道,而且多个表联结操作会降低性能,所以一般不用雪花模式设计数据仓库。
事实星座模式就是星形模式的集合,包含星形模式,也就包含多个事实表。
1.8、企业级数据仓库/数据集市
企业级数据仓库:
突出大而全,不论是细致数据和聚合数据它全都有,设计时使用事实星座模式
数据集市:
可以看做是企业级数据仓库的一个子集,它是针对某一方面的数据设计的数据仓库,例如为公司的支付业务设计一个单独的数据集市。
由于数据集市没有进行企业级的设计和规划,所以长期来看,它本身的集成将会极其复杂。
其数据来源有两种,一种是直接从原生数据源得到,另一种是从企业数据仓库得到。
设计时使用星形模型
2、数据仓库设计步骤
2.1、确定主题
主题与业务密切相关,所以设计数仓之前应当充分了解业务有哪些方面的需求,据此确定主题。
2.2、确定量度
在确定了主题以后,我们将考虑要分析的技术指标,诸如年销售额之类。
量度是要统计的指标,必须事先选择恰当,基于不同的量度将直接产生不同的决策结果。
2.3、确定数据粒度
考虑到量度的聚合程度不同,我们将采用“最小粒度原则”,即将量度的粒度设置到最小。
例如如果知道某些数据细分到天就好了,那么设置其粒度到天;
但是如果不确定的话,就将粒度设置为最小,即毫秒级别的。
2.4、确定维度
设计各个维度的主键、层次、层级,尽量减少冗余。
2.5、创建事实表
事实表中将存在维度代理键和各量度,而不应该存在描述性信息,即符合“瘦高原则”,即要求事实表数据条数尽量多(粒度最小),而描述性信息尽量少。
3、数据仓库-全量表
全量表:
保存用户所有的数据(包括新增与历史数据)
增量表:
只保留当前新增的数据
快照表:
按日分区,记录截止数据日期的全量数据
切片表:
切片表根据基础表,往往只反映某一个维度的相应数据。
其表结构与基础表结构相同,但数据往往只有某一维度,或者某一个事实条件的数据
3.1、更新插入算法
更新插入(主表)算法适用于保留最新状态表的处理。
案例:
银行账户余额表,全表表大约8000万,非结息日每日变动100万,结息日变动2000万。
非结息日:
它是指根据主键(或指定字段)进行数据对比,如果增量表存在记录,则更新原全量表,否则插入数据。
ETL更新的优化?
Merge?
结息日:
新建空表,它是指根据主键(或指定字段)进行数据对比,首先插入原全量表与增量表无法匹配的非变更数据,再次插入可以匹配的增量表数据,最后补齐增量表与全量表无法匹配的增量数据。
3.2、直接追加算法
直接追加算法是指增量数据直接追加到目标表中,此算法适合流水、交易、事件、话单等增量且不修改的数据。
由于历史信息表数据量过于庞大,往往在数据库设计中将引入分区表的逻辑来处理,具体实现逻辑自查。
3.3、全量历史表算法
拉链表。
4、数据仓库-拉链表
拉链表:
数据仓库设计中表存储数据的方式而定义的,顾名思义,所谓拉链,就是记录历史。
记录一个事物从开始,一直到当前状态的所有变化的信息。
我们先看一个示例,这就是一张拉链表,存储的是用户的最基本信息以及每条记录的生命周期。
我们可以使用这张表拿到最新的当天的最新数据以及之前的历史数据。
在数据仓库的数据模型设计过程中,经常会遇到下面这种表的设计:
1、有一些表的数据量很大,比如一张用户表,大约10亿条记录,50个字段,这种表,即使使用ORC压缩,单张表的存储也会超过100G(在HDFS使用双备份或者三备份的话就更大一些)。
2、表中的部分字段会被update更新操作,如用户联系方式,产品的描述信息,订单的状态等等。
3、需要查看某一个时间点或者时间段的历史快照信息,比如,查看某一个订单在历史某一个时间点的状态。
4、表中的记录变化的比例和频率不是很大,比如,总共有10亿的用户,每天新增和发生变化的有200万左右,变化的比例占的很小。
那么对于这种表我该如何设计呢?
下面有几种方案可选:
方案一:
每天只留最新的一份(比如我们每天用Sqoop抽取最新的一份全量数据到Hive中)。
方案二:
每天保留一份全量的切片数据。
方案三:
使用拉链表。
4.1、为什么使用拉链表
现在我们对前面提到的三种进行逐个的分析。
方案一
这种方案就不用多说了,实现起来很简单,每天drop掉前一天的数据,重新抽一份最新的。
优点很明显,节省空间,一些普通的使用也很方便,不用在选择表的时候加一个时间分区什么的。
缺点同样明显,没有历史数据,先翻翻旧账只能通过其它方式,比如从流水表里面抽。
方案二
每天一份全量的切片是一种比较稳妥的方案,而且历史数据也在。
缺点就是存储空间占用量太大了,如果对这边表每天都保留一份全量,那么每次全量中会保存很多不变的信息,对存储是极大的浪费。
当然我们也可以做一些取舍,比如只保留近一个月的数据?
但是,需求是无耻的,数据的生命周期不是我们能完全左右的。
拉链表在使用上基本兼顾了我们的需求。
首先它在空间上做了一个取舍,虽说不像方案一那样占用量那么小,但是它每日的增量可能只有方案二的千分之一甚至是万分之一。
其实它能满足方案二所能满足的需求,既能获取最新的数据,也能添加筛选条件也获取历史的数据。
所以我们还是很有必要来使用拉链表的。
4.2、拉链表的实现
下面我们来举个栗子详细看一下拉链表。
我们先看一下在Mysql关系型数据库里的user表中信息变化。
在2017-01-01这一天表中的数据是:
在2017-01-02这一天表中的数据是,用户002和004资料进行了修改,005是新增用户:
在2017-01-03这一天表中的数据是,用户004和005资料进行了修改,006是新增用户:
如果在数据仓库中设计成历史拉链表保存该表,则会有下面这样一张表,这是最新一天(即2017-01-03)的数据:
说明
t_start_date表示该条记录的生命周期开始时间,t_end_date表示该条记录的生命周期结束时间。
t_end_date=‘9999-12-31’表示该条记录目前处于有效状态。
如果查询当前所有有效的记录,则select*fromuserwheret_end_date=‘9999-12-31’。
如果查询2017-01-02的历史快照,则selectfromuserwheret_start_date<
=‘2017-01-02’andt_end_date>
=‘2017-01-02’。
(*此处要好好理解,是拉链表比较重要的一块。
**)
4.3、拉链表在Hive中的实现
在现在的大数据场景下,大部分的公司都会选择以Hdfs和Hive为主的数据仓库架构。
目前的Hdfs版本来讲,其文件系统中的文件是不能做改变的,也就是说Hive的表智能进行删除和添加操作,而不能进行update。
基于这个前提,我们来实现拉链表。
还是以上面的用户表为例,我们要实现用户的拉链表。
在实现它之前,我们需要先确定一下我们有哪些数据源可以用。
我们需要一张ODS层的用户全量表。
至少需要用它来初始化。
每日的用户更新表。
而且我们要确定拉链表的时间粒度,比如说拉链表每天只取一个状态,也就是说如果一天有3个状态变更,我们只取最后一个状态,这种天粒度的表其实已经能解决大部分的问题了。
ods层的user表
现在我们来看一下我们ods层的用户资料切片表的结构:
CREATE
EXTERNAL
TABLE
ods.user
(
user_num
STRING
COMMENT
'
用户编号'
mobile
手机号码'
reg_date
注册日期'
用户资料表'
PARTITIONED
BY
(dt
string)
ROW
FORMAT
DELIMITED
FIELDS
TERMINATED
\t'
LINES
\n'
STORED
AS
ORC
LOCATION
/ods/user'
;
)
ods层的user_update表
然后我们还需要一张用户每日更新表,前面已经分析过该如果得到这张表,现在我们假设它已经存在。
ods.user_update
每日用户资料更新表'
/ods/user_update'
拉链表
现在我们创建一张拉链表:
dws.user_his
t_start_date
t_end_date
用户资料拉链表'
/dws/user_his'
实现sql语句
然后初始化的sql就不写了,其实就相当于是拿一天的ods层用户表过来就行,我们写一下每日的更新语句。
现在我们假设我们已经已经初始化了2017-01-01的日期,然后需要更新2017-01-02那一天的数据,我们有了下面的Sql。
然后把两个日期设置为变量就可以了。
INSERT
OVERWRITE
SELECT
*
FROM
A.user_num,
A.mobile,
A.reg_date,
A.t_start_time,
CASE
WHEN
A.t_end_time
=
9999-12-31'
AND
B.user_num
IS
NOT
NULL
THEN
2017-01-01'
ELSE
END
t_end_time
A
LEFT
JOIN
B
ON
A.user_num
UNION
C.user_num,
C.mobile,
C.reg_date,
2017-01-02'
t_start_time,
C
T
好了,我们分析了拉链表的原理、设计思路、并且在Hive环境下实现了一份拉链表,下面对拉链表做一些小的补充。
拉链表和流水表
流水表存放的是一个用户的变更记录,比如在一张流水表中,一天的数据中,会存放一个用户的每条修改记录,但是在拉链表中只有一条记录。
这是拉链表设计时需要注意的一个粒度问题。
我们当然也可以设置的粒度更小一些,一般按天就足够。
查询性能
拉链表当然也会遇到查询性能的问题,比如说我们存放了5年的拉链数据,那么这张表势必会比较大,当查询的时候性能就比较低了,个人认为两个思路来解决:
在一些查询引擎中,我们对start_date和end_date做索引,这样能提高不少性能。
保留部分历史数据,比如说我们一张表里面存放全量的拉链表数据,然后再对外暴露一张只提供近3个月数据的拉链表。
使用拉链表的时候可以不加t_end_date,即失效日期,但是加上之后,能优化很多查询。
可以加上当前行状态标识,能快速定位到当前状态。
在拉链表的设计中可以加一些内容,因为我们每天保存一个状态,如果我们在这个状态里面加一个字段,比如如当天修改次数,那么拉链表的作用就会更大。
5、对私数据仓库实战
数据仓库主题,客户资产等级。
何为客户资产等级,根据客户的纯资产的月均总额、贷款余额的总额、信用卡近一年消费额的总额,分别按照规则制定,计算出分别的等级,取三者的最高等级,用于定义客户在我行的资产等级。
分别为:
私行、财富、理财、普通。
源事实表:
存款账户表、基金账户、理财账户、客户信息表、汇率表、信用卡交易表、贷款余额表。
 升级会员
升级会员 