模糊聚类分析方法文档格式.docx
《模糊聚类分析方法文档格式.docx》由会员分享,可在线阅读,更多相关《模糊聚类分析方法文档格式.docx(20页珍藏版)》请在冰豆网上搜索。
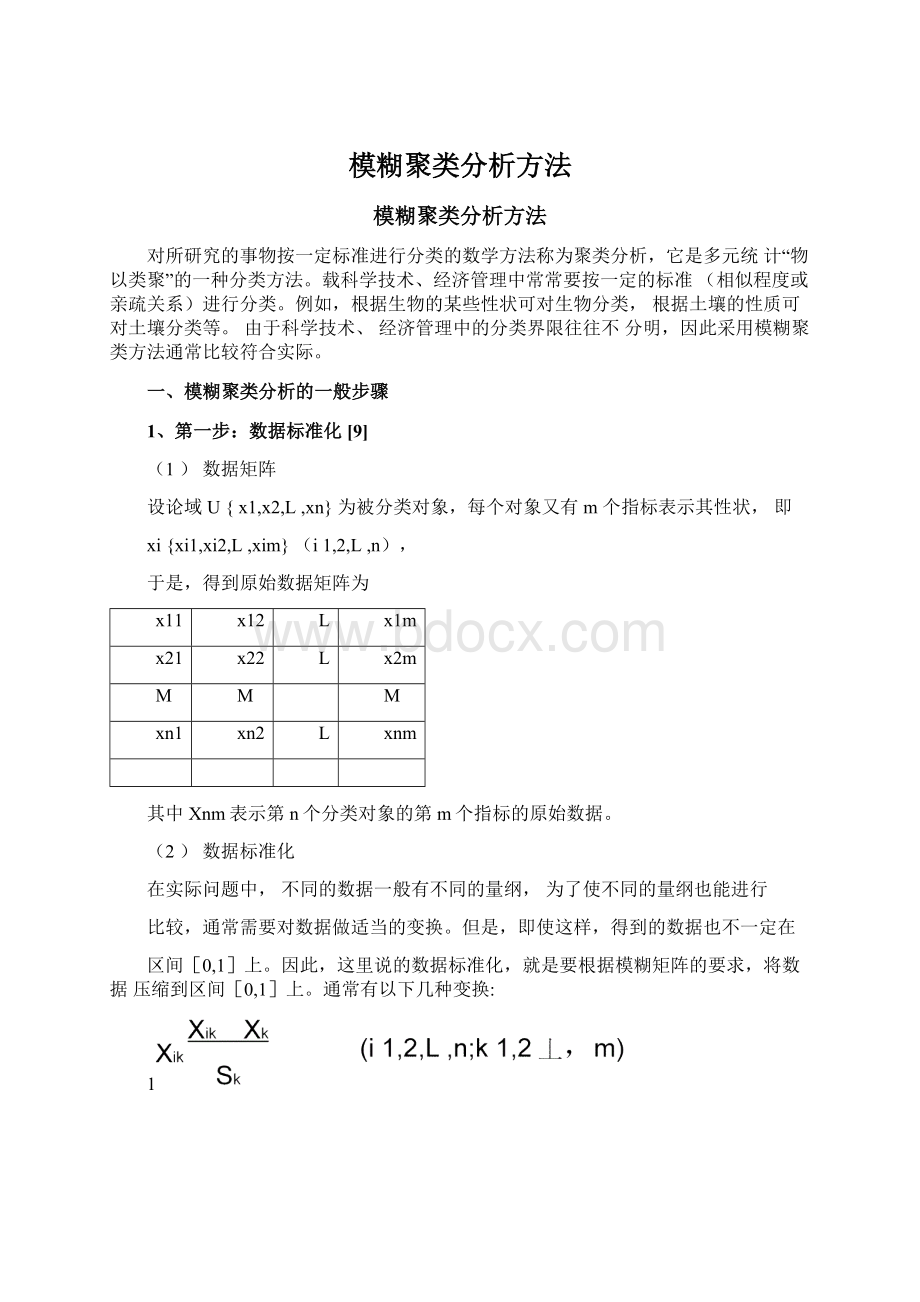
(Xik
k1
Xjk)
m0
(XikXjk)
③算术平均最小法
2(xik
4几何平均最小法
2(XikXjk)
rj
、,XikgXjk
k1'
以上3种方法中要求Xj0,否则也要做适当变换
⑤数量积法
1,ij,
1m~-■,
XikgXjk,iJ,
Mk1
其中
MHlajX(XkgXjk)。
|jk1
⑥相关系数法
m_
XkXiXjkk1
Xj
(Xk
Xi)2g.;
(XjkXj)2
-1m
XiXik,
mk1
1m
Xjk。
⑦指数相似系数法
—exp[
3(Xk
4叶
2
-],
Sk
-(Xik
ni1
Xik)2,
Xk
1n
Xik
k(1,2丄
m)。
(2)
距离法
①直接距离法
1cd(Xj,Xj),
其中c为适当选取的参数,使得or
1,d(x,Xj)表示他们之间的距离。
经常
用的距离有
•海明距离
d(Xi,Xj)
XikXjk。
•欧几里得距离
d(N,Xj)
•切比雪夫距离
d(Xi,Xj)k1XikXjk。
2倒数距离法
1,ij,rijM
j,ij,
d(Xi,Xj)其中M为适当选取的参数,使得0rij1。
3指数距离法
rijexp[d(xi,xj)]。
3、第三步:
聚类(求动态聚类图)
(1)基于模糊等价矩阵聚类方法
1传递闭包法
根据标定所得的模糊矩阵R还要将其改造称模糊等价矩阵R*。
用二次方法
求R的传递闭包,即t(R)=R*。
再让由大变小,就可形成动态聚类图。
②布尔矩阵法[10]
布尔矩阵法的理论依据是下面的定理:
定理2.2.1设R是U{为兀丄,焉}上的一个相似的布尔矩阵,则R具有传
递性(当R是等价布尔矩阵时)矩阵R在任一排列下的矩阵都没有形如
的特殊子矩阵。
布尔矩阵法的具体步骤如下:
1求模糊相似矩阵的截矩阵R.
2若R按定理2.2.1判定为等价的,则由R可得U在水平上的分类,
若R判定为不等价,则R在某一排列下有上述形式的特殊子矩阵,此时只要将其中特殊子矩阵的0一律改成1直到不再产生上述形式的子矩阵即可。
如此得到的R*为等价矩阵。
因此,由R*可得水平上的分类
(2)直接聚类法
所谓直接聚类法,是指在建立模糊相似矩阵之后,不去求传递闭包t(R),也
不用布尔矩阵法,而是直接从模糊相似矩阵出发求得聚类图。
其步骤如下:
①取11(最大值),对每个xi作相似类[xi]R,且
[xi]R={xj|rij1},
即将满足rij1的xi与xj放在一类,构成相似类。
相似类与等价类的不同之处是,不同的相似类可能有公共元素,即可出现
[xi]R{xi,xk},[xi]R{xj,xk},[xi][xj].此时只要将有公共元素的相似类合并,即可得11水平上的等价分类。
②取2为次大值,从R中直接找出相似度为2的元素对(xi,xj)(即rj2),将对应于i1的等价分类中人所在的类与Xj所在的类合并,将所有的这些情况合并后,即得到对应于2的等价分类。
3取3为第三大值,从R中直接找出相似度为3的元素对(Xi,Xj)(即rij3),将对应于2的等价分类中Xi所在的类与Xj所在的类合并,将所有的这些情况合并后,即得到对应于3的等价分类。
4以此类推,直到合并到U成为一类为止。
二、最佳阈值的确定
在模糊聚类分析中对于各个不同的[0,1],可得到不同的分类,许多实际
问题需要选择某个阈值,确定样本的一个具体分类,这就提出了如何确定阈值的问题。
一般有以下两个方法:
1按实际需要,在动态聚类图中,调整的值以得到适当的分类,而不需要事先准确地估计好样本应分成几类。
当然,也可由具有丰富经验的专家结合专业知识确定阈值,从而得出在水平上的等价分类
2用F统计量确定最佳值。
[11]
设论域U{Xi,X2,L,Xn}为样本空间(样本总数为n),而每个样本Xi有m个
特征:
Xi{xM,Xi2,L,Xm},(i1,2,L,n)。
于是得到原始数据矩阵,如下表所示,
\n
其中Xk—Xik(k1,2,L,m),X称为总体样本的中心向量。
nii
样
本
指
标
k
X
Xii
X12
X1k
X1m
为
X21
X22
X2k
X2m
Xi1
Xi2
Xim
Xi
Xn1
Xn2
Xnk
X八nm
(X1
X2
Xm)
设对应于
值的分类数为r,第j类的样本数为nj,第j类的样本记为:
X;
j),X2j),L,第j类的聚类中心为向量X⑴伐⑴XT丄,腐),其中Xk⑴为第
k个特征的平均值,即
□j
Xkj)—X(kj),(k1,2,L,m),
①i1
作F统计量
r.■
njX(j)x(r1)
Fj1/
rnj:
,
I(j)_(j)|/、
|xiX|,(nr)
j1i1/
为x⑴与x间的距离,x/j)x⑴为第j类中第i个样本X⑴与其中心x(j)间的距离。
称为F统计量,它是遵从自由度为r1,nr的F分布。
它的分子表征类与类之间的距离,分母表征类内样本间的距离。
因此,F值越大,说明类与类之间的距离越大;
类与类间的差异越大,分类就越好。
基于模糊聚类分析的多属性
决策方法的实际应用
聚类分析是将事物根据一定的特征,并按某种特定要求或规律分类的方法。
由于聚类分析的对象必定是尚未分类的群体,而且现实的分类问题往往带有模糊性,对带有模糊特征的事物进行聚类分析,分类过程中不是仅仅考虑事物之间有无关系,而是考虑事物之间关系的深浅程度,显然用模糊数学的方法处理更为自然,因此称为模糊聚类分析。
第一节雨量站问题
一、问题的提出
某地区设置有11个雨量站,其分布图见图1,10年来各雨量站所测得的年
降雨量列入表1中。
现因经费问题,希望撤销几个雨量站,问撤销那些雨量站,
而不会太多的减少降雨信息?
表1各雨量站10年间测得的降雨量
年序号
X1
X3
X4
X5
X6
X7
X8
X9
X10
X11
276
324
159
413
292
258
311
303
175
243
320
251
287
349
344
310
454
285
451
402
307
470
3
192
433
290
563
479
502
221
220
411
232
4
246
281
267
273
315
327
352
5
291
388
330
410
603
6
466
158
224
178
164
203
240
278
350
7
432
401
361
381
301
199
421
8
453
365
357
452
384
420
482
228
360
316
252
9
271
308
283
201
179
430
342
185
10
406
235
520
442
358
343
282
371
二、问题的分析
应该撤销那些雨量站,涉及雨量站的分布,地形,地貌,人员,设备等众多
因素。
我们仅考虑尽可能地减少降雨信息问题。
一个自然的想法是就10年来各
雨量站所获得的降雨信息之间的相似性,对全部雨量站进行分类,撤去“同类”
(所获降雨信息十分相似)的雨量站中“多余”的站。
问题求解假设为使问题简化,特作如下假设
1每个观测站具有同等规模及仪器设备;
2每个观测站的经费开支均等;
具有相同的被裁可能性。
分析:
对上述撤销观测站的问题用基于模糊等价矩阵的模糊聚类方法进行分析,原始数据如上。
三、问题的解决
求解步骤:
1、数据的收集
原始数据如表1所示。
2、建立模糊相似矩阵
利用相关系数法,构造模糊相似关系矩阵(r)11ii,其中
n
I(XikXi)||(XjkXj)|
r..=―
ijn—n_2
[(x.kX.)2(XjkXj)2]2
k1k1
取i2,j1,
代入公式得3=0.839,由于运算量巨大用C语言编程计算出
其余数值,得模糊相似关系矩阵(r)1111,具体程序如下
#include<
stdio.h>
#include<
math.h>
doubler[11][11];
doublex[11];
voidmain()
{inti,j,k;
doublefenzi=0,fenmu1=0,fenmu2=0,fenmu=0;
intyear[10][11]={276,324,159,413,292,258,311,303,175,243,320,
251,287,349,344,310,454,285,451,402,307,470,
192,433,290,563,479,502,221,220,320,411,232,
246,232,243,281,267,310,273,315,285,327,352,
291,311,502,388,330,410,352,267,603,290,292,
466,158,224,178,164,203,502,320,240,278,350,
258,327,432,401,361,381,301,413,402,199,421,
453,365,357,452,384,420,482,228,360,316,252,
158,271,410,308,283,410,201,179,430,342,185,
324,406,235,520,442,520,358,343,251,282,371};
for(i=0;
i<
11;
i++)
{for(k=0;
k<
10;
k++)
{x[i]=x[i]+year[k][i];
}
x[i]=x[i]/10;
for(i=0;
{for(j=0;
j<
j++)
{fenzi=fenzi+fabs((year[k][i]-x[i])*(year[k][j]-x[j]));
fenmu1=fenmu1+(year[k][i]-x[i])*(year[k][i]-x[i]);
fenmu2=fenmu2+(year[k][j]-x[j])*(year[k][j]-x[j]);
fenmu=sqrt(fenmu1)*sqrt(fenmu2);
r[i][j]=fenzi/fenmu;
fenmu=fenmu1=fenmu2=fenzi=0;
}}
{for(j=0;
{printf("
%6.3f"
r[i][j]);
printf("
\n"
);
getchar();
得到模糊相似矩阵R
1.0000.8390.5280.8440.8280.7020.9950.6710.4310.5730.712
0.8391.0000.5420.9960.9890.8990.8550.5100.4750.6170.572
0.5280.5421.0000.5620.5850.6970.5710.5510.9620.6420.568
0.8440.9960.5621.0000.9920.9080.8610.5420.4990.6390.607
0.8280.9890.5850.9921.0000.9220.8430.5260.5120.6860.584
0.7020.8990.6970.9080.9221.0000.7260.4550.6670.5960.511
0.9950.8550.5710.8610.8430.7261.0000.6760.4890.5870.719
0.6710.5100.5510.5420.5260.4550.6761.0000.4670.6780.994
0.4310.4750.9620.4990.5120.6670.4890.4671.0000.4870.485
0.5730.6170.6420.6390.6860.5960.5870.6780.4871.0000.688
0.7120.5720.5680.6070.5840.5110.7190.9940.4850.6881.000
对这个模糊相似矩阵用平方法作传递闭包运算,求R2R4:
R4即
4*t(R)R4R*。
3、聚类
注:
R是对称矩阵,故只写出它的下三角矩阵
取=0.996,则
111
11
*
R0.9961
X2,X4,X5在置信水平为0.996的阈值下相似度为1,故X2,X4,X5同属一类,所以此时可以将观测站分为9类{X2,X4,乂5},{捲},{X3},{X6},{X7},{X8},{X9},
{X10},{X11}。
降低置信水平,对不同的作同样分析,得到:
=0.995时,可分为8类,即{X2,X4,X5,X6},{X1},{X3},{X7},{X8},{Xg},{Xio},{Xn}o
=0.994时,可分为7类{X2,X4,X5,X6},{Xi,X7},{X3},{xs},{X9},{xio},{xii}。
=0.962时,可分为6类{X2,X4,X5,X6},{Xi,X7},{X3,X9},仁},{皿冨心}。
=0.7i9时,可分为5类{X2,X4,X5,X6},{xi,X7},{X3,X9},{X8,Xii},{xi。
}。
第二节成绩评价问题
一、问题的提出
某高中高二有7个班级,学生成绩的好与差,没有明确的评定界限,并且班级间成绩好坏的表现具有一定的模糊不确定性。
二、问题的分析
解决上述问题可运用模糊聚类分析方法。
现以7个班级某次其中考试的四门主课成绩为依据,对7个班级成绩好坏的相关程度分类。
设7个班级组成一个分类集合:
X(x「X2,L,X7)分别代表1班到7班。
每个班级成绩均是四门基础课(语文、数学、英语、综合)作为四项统计指标,即有Xj{Xi1,Xi2,Xi3,Xi4}这里Xj表示为第i个班级的第j门基础课指标(i1,2,L,7;
j1,2,L,4)。
这四项成绩指标为:
语文平均成绩XM,数学平均成
绩Xi2,英语平均成绩Xi3,综合平均成绩Xi4。
各班级成绩指标值见表1。
表17个班4门基础课的成绩指标
班
级
4班
2班
3班
㊁班
6班
了班
62.03
62.48
78.52
72.12
74.18
73.95
66.83
59.47
63.70
72.38
73.28
67.07
68.32
76.04
68.17
61.04
75.17
77.68
67274
70.09
76.87
72.45
74.65
70.77
70.43
6073
73.18
1、数据标准化[12]
采用极差变换Xjx,
(1)
XmaxXmin
式中Xij是第ii个班级第j门基础课平均成绩的原始数据,Xmax和Xmin分别为不同
班级的同一门基础课平均成绩的最大值和最小值。
Xj为第i个班级第j门基础课
平均成绩指标的标准化数值。
当XijXmin时,X0,当XijXmax时,X1。
表2平均成绩指标值的标准化数值
班级
5班
7班
0*0273
0.6119
0.7368
0.7229
02911
0.2553
0.7791
0.8385
0.4587
0.5341
04285
0.&
492
0.3966
0.5439
0.9513
X典
0.6605
0.4012
0.3488
0.0864
0.7731
2、用最大最小法建立相似矩阵
计算模糊相似矩阵R,根据标准化数值建立各班级之间四门基础课成绩指标
的相似关系矩阵,采用最大最小法来计算rj:
其中rj[0,1],(i1,2,L,7j1,2,3,4)是表示第i个班级与第j个班级在四门基础课成绩指标上的相似程度的量。
取i2,j1,r21=0,其余运算量可以通过
MATLAB编程运算,程序如下:
[13]
clcclearall
meanp=[0
0.027310.61190.73680.72290.2911;
00.25530.77910.83850.45870.53411;
指标值的标准化数值
Ca=[0;
0;
0];
%初始化比较的数据
Cb=[0;
mina=[0];
maxa=[0];
fori=1:
forj=1:
form=1:
Ca=meanp(m,i);
Cb=meanp(m,j);
mina(1,m)=min(Ca,Cb);
%计算任意两横的最小值
maxa(1,m)=max(Ca,Cb);
%计算任意两横的最大值
end
R(i,j)=sum(mina)/sum(maxa);
%计算rij,即相似程度的量
R%显示相似矩阵
0.21
0.33
0.30
0.27
0.36
0.15
0.14
0.08
0.10
0.09
0.77
0.52
0.60
0.42
得相似矩阵:
R0.33
0.53
0.61
0.43
0.69
0.68
0.73
3、改造相似关系为等价关系进行聚类分析
R进行
矩阵R满足自反性和对称性,但不具有传递性,为求等价矩阵,
改造,只需求其传递闭包。
由平方法可得
RoRR20.36
 升级会员
升级会员 