Hadoop作业提交与执行分析王挺Word文档下载推荐.docx
《Hadoop作业提交与执行分析王挺Word文档下载推荐.docx》由会员分享,可在线阅读,更多相关《Hadoop作业提交与执行分析王挺Word文档下载推荐.docx(17页珍藏版)》请在冰豆网上搜索。
//是否载入默认资源
privatestaticfinalWeakHashMap<
Configuration,Object>
REGISTRY=newWeakHashMap<
//
privatePropertiesproperties;
//个人程序所需要的所有配置会以Properties的形式存储
privatePropertiesoverlay;
/*它也是一个Properties变量。
它对应于finalResources列表,也就是解析finalResources列表中设置的配置文件,配置项设置到overlay中。
这里,overlay比较关键的一点就是,如果overlay不为空属性配置,在创建一个Configuration实例的时候会检查overlay,不空就将其中的配置项加入到properties中.*/
privateClassLoaderclassLoader;
//类加载器
在这里所有客户端程序中配置的类的信息和其他运行信息,都会保存在这个类里。
2.2
JobClient.runJob()开始运行job并分解输入数据集
一个MapReduce的Job会通过JobClient类根据用户在JobConf类中定义的InputFormat实现类(通过getInputFormat()调用getClass()来得到)来将输入的数据集分解成一批小的数据集,每一个小数据集会对应创建一个MapTask来处理。
EagerTaskInitializationListener将调用JobInProcess.initTask根据InputSplit来创建map和reducetask,同时创建assistanttask,比如clean-uptask.
注:
InputFormat接口默认被FileInputFormat类实现,TextInputFormat类继承自FileInputFormat类。
FileInputFormat类里定义了一系列分解数据集的操作。
JobClient会使用缺省的TextInputFormat类调用TextInputFormat.getSplits()方法生成小数据集(通过InputFormat接口调用此方法),如果判断数据文件是isSplitable()的话,会将大的文件分解成小的FileSplit,当然只是记录文件在HDFS里的路径及偏移量和Split大小。
这些信息会统一打包到jobFile的jar中并存储在HDFS中,再将jobFile路径提交给JobTracker去调度和执行。
打包:
用户使用eclipse或者ant命令进行打包。
传输:
JobClient会使用copyRemoteFiles()方法拷贝文件到HDFS。
privatePathcopyRemoteFiles(FileSystemjtFs,PathparentDir,PathoriginalPath,JobConfjob,shortreplication)throwsIOException{
FileSystemremoteFs=null;
remoteFs=originalPath.getFileSystem(job);
if(compareFs(remoteFs,jtFs)){
returnoriginalPath;
}
PathnewPath=newPath(parentDir,originalPath.getName());
FileUtil.copy(remoteFs,originalPath,jtFs,newPath,false,job);
jtFs.setReplication(newPath,replication);
returnnewPath;
}
提交:
JobTracker实际获得的是Job对应的url.JobClient中,首先由Path实例化了一个submitJarFile,它包含了Jar文件的路径信息,然后调用configureCommandLineOptions()方法,此方法中使用了job.setJar()方法获得了一个路径的字符串形式。
2.3
JobClient.submitJob()提交job到JobTracker
jobFile的提交过程是通过RPC模块来实现的。
大致过程是,JobClient类中通过RPC实现的Proxy接口(提前创建好了RPC代理)调用JobTracker的submitJob()方法,而JobTracker必须实现JobSubmissionProtocol接口。
createRPCproxy返回了一个实现JobSubmissionProtocol接口的对象叫做jobSubmitClient,JobClient通过此对象调用submitJob方法(submitJob又调用了submitJobInternal方法)来提交job.
submitJobInternal方法利用RPC调用JobTracker.submitJob(),submitJob方法调用addjob(),把job添加到JobInProgress中。
privatesynchronizedJobStatusaddJob(JobIDjobId,JobInProgressjob){
totalSubmissions++;
synchronized(jobs){
synchronized(taskScheduler){
jobs.put(job.getProfile().getJobID(),job);
for(JobInProgressListenerlistener:
jobInProgressListeners){
try{
listener.jobAdded(job);
}catch(IOExceptionioe){
LOG.warn("
Failedtoaddandsoskippingthejob:
"
+job.getJobID()+"
.Exception:
+ioe);
myInstrumentation.submitJob(job.getJobConf(),jobId);
returnjob.getStatus();
JobTracker则根据获得的jobFile路径创建与job有关的一系列对象(即JobInProgress和TaskInProgress等)来调度并执行job。
JobTracker创建job成功后会给JobClient传回一个JobStatus对象用于记录job的状态信息,如执行时间、Map和Reduce任务完成的比例等。
JobClient会根据这个JobStatus对象创建一个NetworkedJob的RunningJob对象,用于定时从JobTracker获得执行过程的统计数据来监控并打印到用户的控制台。
submitJob内部通过JobSubmitter的SubmitJobInternal进行实质性的提交,即提交三个文件,job.jar,job.split,job.xml这三个文件位置由mapreduce系统路径mapred.system.dir属性决定,写完这三个文件之后,此方法使用RPC调用master节点的JobTracker.submitJob(job)方法。
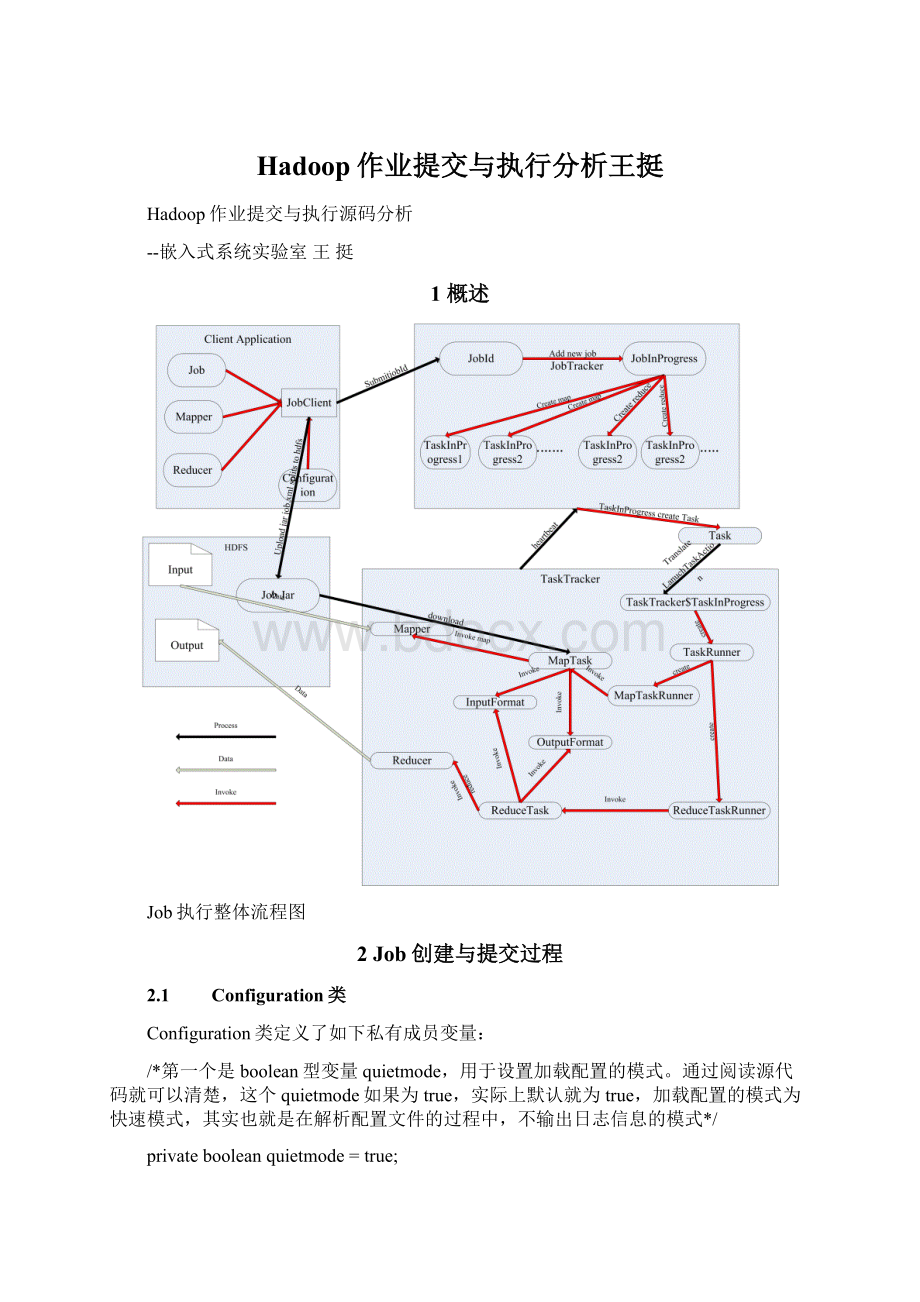
3Job执行过程
job统一由JobTracker来调度的,具体的Task分发给各个TaskTracker节点来执行。
3.1
JobTracker初始化Job和Task队列过程
启动JobTracker后它会初始化若干个服务以及若干个内部线程用来维护job的执行过程和结果。
首先,JobTracker会启动一个interTrackerServer,端口配置在Configuration中的"
mapred.job.tracker"
参数,缺省是绑定8012端口。
它有两个用途,一是用于接收和处理TaskTracker的heartbeat等请求,即必须实现InterTrackerProtocol接口及协议。
二是用于接收和处理JobClient的请求,如submitJob,killJob等,即必须实现JobSubmissionProtocol接口及协议。
其次,它会启动一个infoServer线程,运行StatusHttpServer,缺省监听50030端口。
是一个web服务,用于给用户提供web界面查询job执行状况的服务。
JobTracker还会启动多个线程,ExpireLaunchingTasks线程用于停止那些未在超时时间内报告进度的Tasks。
ExpireTrackers线程用于停止那些可能已经当掉的TaskTracker,即长时间未报告的TaskTracker将不会再分配新的Task。
RetireJobs线程用于清除那些已经完成很长时间还存在队列里的jobs。
JobInitThread线程用于初始化job,这在前面章节已经介绍。
TaskCommitQueue线程用于调度Task的那些所有与FileSystem操作相关的处理,并记录Task的状态等信息。
3.1.1
JobTracker.submitJob()收到请求
当JobTracker接收到新的job请求(即submitJob()函数被调用)后,会创建一个JobInProgress对象并通过它来管理和调度任务。
JobInProgressjob=newJobInProgress(jobId,this,this.conf);
JobInProgress在创建的时候会初始化一系列与任务有关的参数,如jobjar的位置(会把它从HDFS复制本地的文件系统中的临时目录里),Map和Reduce的数据,job的优先级别,以及记录统计报告的对象等。
publicJobInProgress(JobIDjobid,JobTrackerjobtracker,
JobConfdefault_conf,intrCount)throwsIOException{
this.restartCount=rCount;
this.jobId=jobid;
Stringurl="
http:
//"
+jobtracker.getJobTrackerMachine()+"
:
"
+jobtracker.getInfoPort()+"
/jobdetails.jsp?
jobid="
+jobid;
this.jobtracker=jobtracker;
this.status=newJobStatus(jobid,0.0f,0.0f,JobStatus.PREP);
this.startTime=System.currentTimeMillis();
status.setStartTime(startTime);
this.localFs=FileSystem.getLocal(default_conf);
JobConfdefault_job_conf=newJobConf(default_conf);
this.localJobFile=default_job_conf.getLocalPath(JobTracker.SUBDIR+"
/"
+jobid+"
.xml"
);
this.localJarFile=default_job_conf.getLocalPath(JobTracker.SUBDIR+"
+jobid+"
.jar"
PathjobDir=jobtracker.getSystemDirectoryForJob(jobId);
FileSystemfs=jobDir.getFileSystem(default_conf);
jobFile=newPath(jobDir,"
job.xml"
fs.copyToLocalFile(jobFile,localJobFile);
conf=newJobConf(localJobFile);
this.priority=conf.getJobPriority();
this.status.setJobPriority(this.priority);
this.profile=newJobProfile(conf.getUser(),jobid,jobFile.toString(),url,conf.getJobName(),conf.getQueueName());
StringjarFile=conf.getJar();
if(jarFile!
=null){
fs.copyToLocalFile(newPath(jarFile),localJarFile);
conf.setJar(localJarFile.toString());
this.numMapTasks=conf.getNumMapTasks();
this.numReduceTasks=conf.getNumReduceTasks();
this.taskCompletionEvents=newArrayList<
TaskCompletionEvent>
(numMapTasks+numReduceTasks+10);
this.mapFailuresPercent=conf.getMaxMapTaskFailuresPercent();
this.reduceFailuresPercent=conf.getMaxReduceTaskFailuresPercent();
MetricsContextmetricsContext=MetricsUtil.getContext("
mapred"
this.jobMetrics=MetricsUtil.createRecord(metricsContext,"
job"
this.jobMetrics.setTag("
user"
conf.getUser());
sessionId"
conf.getSessionId());
jobName"
conf.getJobName());
jobId"
jobid.toString());
hasSpeculativeMaps=conf.getMapSpeculativeExecution();
hasSpeculativeReduces=conf.getReduceSpeculativeExecution();
this.maxLevel=jobtracker.getNumTaskCacheLevels();
this.anyCacheLevel=this.maxLevel+1;
this.nonLocalMaps=newLinkedList<
TaskInProgress>
this.nonLocalRunningMaps=newLinkedHashSet<
this.runningMapCache=newIdentityHashMap<
Node,Set<
>
this.nonRunningReduces=newLinkedList<
this.runningReduces=newLinkedHashSet<
this.resourceEstimator=newResourceEstimator(this);
3.1.2
JobTracker.setJobPriority()设置优先级
JobInProgress创建后,首先将它加入到jobs队列里,分别用一个map成员变量jobs用来管理所有jobs对象,一个string变量priority用来维护jobs的执行优先级别。
之后JobTracker会调用resortPriority()函数,将jobs先按优先级别排序,再按提交时间排序,这样保证最高优先并且先提交的job会先执行。
publicsynchronizedvoidsetJobPriority(JobIDjobid,Stringpriority)throwsIOException{
JobInProgressjob=jobs.get(jobid);
if(null==job){
LOG.info("
setJobPriority():
JobId"
+jobid.toString()
+"
isnotavalidjob"
return;
checkAccess(job,QueueManager.QueueOperation.ADMINISTER_JOBS);
JobPrioritynewPriority=JobPriority.valueOf(priority);
setJobPriority(jobid,newPriority);
3.1.3
JobTracker.InitJob通知初始化线程
然后JobTracker会把此job加入到一个管理需要初始化的队列里,即一个list成员变量jobInitQueue里。
通过此成员变量调用notifyAll()函数,会唤起一个用于初始化job的线程InitJob来处理。
InitJob收到信号后即取出最靠前的job,即优先级别最高的job,调用JobInProgress的initTasks()函数执行真正的初始化工作。
publicvoidinitJob(JobInProgressjob){
Initonnulljobisnotvalid"
}
JobStatusprevStatus=(JobStatus)job.getStatus().clone();
Initializing"
+job.getJobID());
job.initTasks();
//Informthelistenersifthejobstatehaschanged
//Note:
thatthejobwillbeinPREPstate.
JobStatusnewStatus=(JobStatus)job.getStatus().clone();
if(prevStatus.getRunState()!
=newStatus.getRunState()){
JobStatusChangeEventevent=
newJobStatusChangeEvent(job,EventType.RUN_STATE_CHANGED,prevStatus,
newStatus);
synchronized(JobTracker.this){
updateJobInProgressListeners(event);
}catch(KillInterruptedExceptionkie){
//Ifjobwaskilledduringinitialization,jobstatewillbeKILLED
LOG.error("
Jobinitializationinterrupted:
\n"
+
StringUtils.stringifyException(kie));
killJob(job);
}catch(Throwablet){
//Ifthejobinitializationisfailed,jobstatewillbeFAILED
Jobinitializationfailed:
StringUtils.stringifyException(t));
failJob(job);
3.1.4
JobInProgress.initTasks()初始化TaskInProgress
Task的初始化过程稍复杂些,首先步骤JobInProgress会创建Map的监控对象。
在initTasks()函数里通过调用JobClient的readSplitFile()获得已分解的输入数据的RawSplit列表,然后根据这个列表创建对应数目的Map执行管理对象TaskInProgress。
在这个过程中,还会记录该RawSplit块对应的所有在HDFS里的blocks所在的DataNode节点的host,这个会在RawSplit创建时通过FileSplit的getLocations()函数获取,该函数会调用DistributedFileSystem的getFileCacheHints()获得(具体在HDFS模块中)。
当然如果是存储在本地文件系统中,即使用LocalFileSystem时当然只有一个location即“localhost”了。
其次JobInProgress会创建Reduce的监控对象,这个比较简单,根据JobConf里指定的Reduce
 升级会员
升级会员 