基于卷积神经网络的图像检测Word下载.docx
《基于卷积神经网络的图像检测Word下载.docx》由会员分享,可在线阅读,更多相关《基于卷积神经网络的图像检测Word下载.docx(16页珍藏版)》请在冰豆网上搜索。
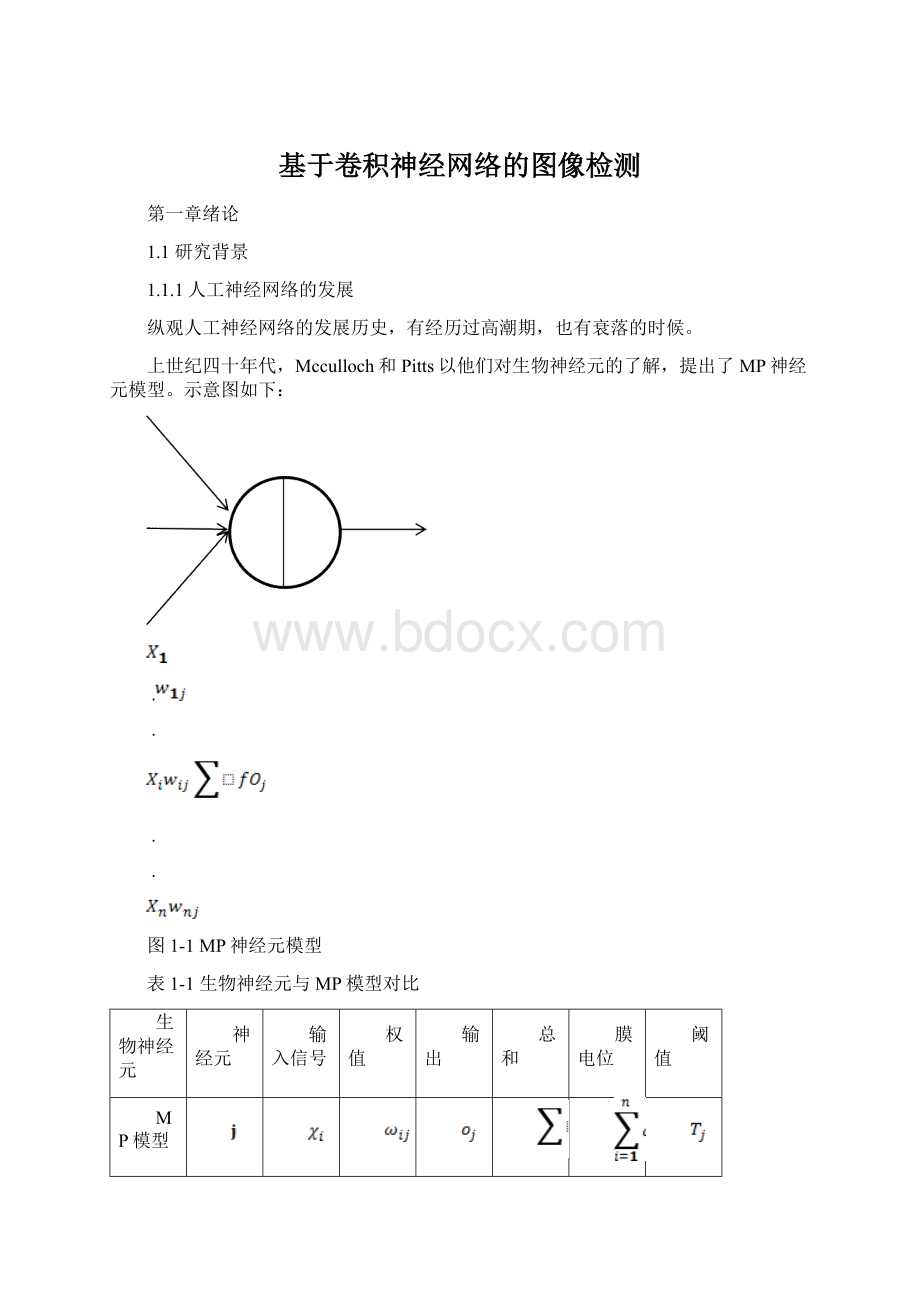
到了七十年代,哈佛博士生PaulWerbos提出了著名的反向传播算法(back—propagating),反响不大。
但后来这一算法又被自然杂志的一篇文章所提起,其激励传播、权重更新等一系列创新性的理论使得人工神经网络有重焕生机。
八十年代,Hopfield神经网络模型出现,该模型对反向传播算法进行了更具体的实现。
从BP算法中得到启发,对此神经网络采用负反馈流程来提高其网络稳定性;
对权重更新设计了诸如外积法、伪逆法、正交设计法等一系列方法。
为带反馈的人工神经网络模型算法提供了重要的公式和理论基础。
随后,connectionism网络模型与并行计算的出现,使得人工神经网络的负反馈算法日趋成熟,但是由于负反馈网络模型所采用BP算法对隐含层数目过多问题有着局部最优和过拟合的缺点,人工神经网络的发展也是受到了根本性的限制。
自此关于人工神经网络的研究出现了第二次发展低潮。
1.1.2DeepLearning对于人工神经网络的推动
然而,在人工神经网络的第二次发展低潮期间,很多研究人员并没有放弃人工神经网络的研究。
终于,在2006年的自然科学杂志上,深度学习(DeepLearning)被提出,这篇文章关于人工神经网络的这一最新研究成果。
这篇文章表明多隐含层的人工神经网络对于特征抽取具有更好的效率,并且识别效果更好;
然后对每一层都初始化的话,就能减少训练的难易度。
传统意义上的多层神经网络是只有输入层、隐藏层、输出层。
其中隐藏层的层数根据需要而定,没有明确的理论推导来说明到底多少层合适。
而深度学习中最著名的卷积神经网络CNN,在原来多层神经网络的基础上,加入了特征学习部分,这部分是模仿人脑对信号处理上的分级的。
具体操作就是在原来的全连接的层前面加入了部分连接的卷积层与降维层,而且加入的是一个层级。
输入层-卷积层-降采样层-卷积层-降采样层--....--隐藏层-输出层简单来说,原来多层神经网络做的步骤是:
特征映射到值。
特征是人工挑选。
深度学习做的步骤是信号->
特征->
值。
特征是由网络自己选择。
因此,深度学习,就是构建一个具有多隐含层的人工神经网络模型,通过加入如卷积层和降采样层,逐层初始化从而得到有关数据集的更本质的特征,来提高分类的准确性。
深度学习和传统的浅层学习的主要区别在模型的深浅,这直接关系到对于图像特征的深层处理过程,与图像检测的准确性直接挂钩。
目前,常见的深度学习算法包括:
受限波尔兹曼机(RestrictedBoltzmannMachine,RBN),信念神经网络(DBN),卷积网络(ConvolutionalNetwork),堆栈式自动编码器(StackedAuto-encoders)。
1.1.3卷积神经网络的研究现状
2006年,卷积神经网络(CNN)出现。
它继承了深度学习的基本思想,采用多个隐含层的神经网络模型,并运用了许多的分类数据集进行训练和测试,在当时得到了世界最好的成绩,但由计算机于硬件水平有限,计算运行速度遇到瓶颈,使得CNN应对大型图像数据处理上乏力。
后来,随着2012年的10月ImageNet问题的解决,CNN进入到了全面发展的时代,出现了一大批学者的研究成果,如人脸识别方法研究[5]、遥感图像分类方法研究[6]等。
目前,基于CNN的手写字符识别已经正式商用,随着时间的推移,将会有更多的模型和算法被开发,卷积神经网络必将会在图像检测领域大放异彩。
CNN主要有三个典型特征,分别是:
局部感受野、权值共享和降采样。
这三个特征都
对于图形特征来说,在所有位置,它的规律都是一样的。
所以可以采用局部的特征,然后集合起来形成全局的特征,这就是局部感受野的概念。
以前所采用的全连接方式来获取图像的全部特征来说,连接数实在过大,运算量非常巨大,科技水平无法达到这种高度,现在有了局部感受域,同一幅图像,只要选取几个区域就行了,然后合并起来的到全局特征,这样就大大减少了连接数目,运算量大幅降低,计算负荷也下降,神经网络也越灵活。
上文中,在这些局部特征中,他们与上一层之间的每一个连接是需要附加权值来进行输入的,这些连接中,每个链接的权值如果是任意的,这也将会带来给计算量。
假如有1000个局部特征连接点,则将会有1000个权值,到下一层的计算量将会是1000x1000=1000000个,如果采用卷机神经网络的权值共享理论,即所有的连接点都采用同一个权值,计算量将会是1000x1=1000个,计算量减少了整整1000倍!
所以,权值共享极大的减少了神经网络计算量,降低了复杂度,使得训练和测试过程变得简单起来。
在图像特征提取后的神经网络深层处理中,通过降采样,可以降低上一层的网络的分辨率,也减少了计算量,但是其本身的特性可以不受影响,这推动了神经网络的简单化。
总之,CNN的基本思想是把局部感受野、权值共享和下采样这三种方法结合了起来,从而实现了特征的提取和分类统一在一起,并对识别对象的位移变化、尺度变化、形变变化具有不变性。
1.1.4图像识别技术的发展及研究现状
图像识别,是指发现对观察到的图像进行特征分析,在用计算机对分析进行处理,从而实现对图像内容的分类识别。
其中,手写数字识别和人脸识别是现今比较成熟的。
手写数字识别可以被用于民族文字识别、电脑阅卷等等,人脸识别则在视频安保监控、“刷脸”支付等等有重要功能。
目前,图像识别系统主要由图像分割,特征提取和分类器组成[7]。
图像分割有三种方法:
(1)基于阈值的分割法。
这是最常用图像分割技术,阈值一般是采用图像的灰度值。
不同的灰度值在广域里面可以表现出图像的不同特征,基于灰度值的分割就可以图像的不同特征分割开来。
(2)基于区域的分割法。
有一种基本方式是分开合并。
分开合并为先划分不同的区域特征,再把不同区域特征合并为全局图像的所有特征,由区域特征实现对图像的分割。
这种方法具有很强的鲁棒性。
(3)基于边缘的分割法。
不同图像区域的边缘的灰度值是不同的,这就可以把边缘像素灰度值连起来,形成一块块的闭合区域,完成对图像的区域分割。
常用的图像特征有颜色特征、纹理特征、形状特征、空间关系特征,可以用它们来完成图像的特征提取。
1、颜色特征。
顾名思义,就是通过颜色来提图像特征。
对颜色也有特定的不同分类方法,常见的是RGB和HSV。
颜色特征匹配方法:
直方图相交法、距离法、中心距法、参考颜色表法、累加颜色直方图法等。
2、纹理特征。
图像像素点与其邻域的像素点的不同可以表示出图像的局部特征表现的变化,这就是纹理。
所以,可以用全局纹理的特征来表现全局图像的特征。
常见的方法有:
LBP方法(Localbinarypatterns)和灰度共生矩阵。
3、形状特征。
图像的内容会包含许多的形状特性,比如轮廓特征和区域特征。
这些特性构成了图像的形状特征,可以利用它们来进行图像的特征提取。
常用的方法有:
边界特征法、傅里叶形状描述符法、几何参数法等。
4、空间关系特征。
空间关系是指图像特征区域之间在空间上如上下、左右和前后的联系。
这一特征也包更高级的如旋转、对称、尺度变换的关系,通过对其特征联系的分析,就可以提取全局的图像特征。
基于模型的姿态估计方法和基于学习的姿态估计方法。
上文中,图像经过了分割和特征提取后,还需要根据图像的特征对图像进行分类。
图像分类中,其方法可分为三类:
无监督式的和监督式的。
无监督式的分类器就是通过以集群理论的基础,“物以类聚”,多的归为一类,少的归为另一类,常见的有k均值聚类、层次聚类和模糊k均值聚类。
监督式的分类器是需要大量的训练样本去训练网络,找出数据当中的各个特点,然后自主分类。
其中包括了参数型和非参数型。
参数型的常用方法有最小距离法、最大似然法等等。
非参数型包括最近邻方法、人工神经网络等。
由于图像识别网络需要巨大的样本去训练、测试,所以我们需要大量的工作和算法,本文采用的卷积神经网络是基于CNN网络架构而建立的,共有两个图像检测应用,对于图像检测领域的发展也是贡献了一份力量。
1.2研究内容及意义
本文主要研究两个方面:
1、手写数字识别,将以卷积神经网络模型为基础,通过对该模型的MATLAB实现,简化参数和结构,构建一种简单的卷积神经网络结构模型,实现MNIST手写数字数据集的图像检测。
2、人脸识别,将构建一种简单的卷积神经网络结构模型,并将其应用到ORL人脸数据库识别上,构建卷积神经网络的结构,进行训练和测试。
本文将研究卷积神经网络在手写数字识别和人脸识别的方法和构造过程,并用MATLAB实现训练和测试的过程,得到了可观的结果,证明了卷积神经网络可以作为一种可行的通用图像检测技术应用到不同的识别任务当中。
1.3本文主要工作
利用卷积神经网络实现对MNIST手写字符数据集的MATLAB检测和ORL人脸数据集的MATLAB检测,并对这两种检测结构进行测试
本文第一章为绪论。
概括了人工神经网络的发展、深度学习的对人工神经网络的推动、卷积神经网络的研究现状和图像识别技术的发展及研究现状,说明了研究内容及意义和主要工作
第二章首先阐述了神经网络的一般结构,然后重点介绍了卷积神经网络的原理结构,包括局部感受野、参数共享和降采样。
第三章主要介绍了卷积神经网络的MATLAB实现。
涉及七个子程序,后文将对这七个子程序一一解释。
第四章提出了基于卷积神经网络的MNIST手写字符数据集识别方法,并将其应用于MATLAB中,进行了训练和测试,得到了可观的结果。
第五章是基于简单CNN的ORL人脸数据库识别方法,并予以MATLAB实现,对其进行训练和测试,得到了可观的结果。
第六章为全文的总结与展望。
第二章卷积神经网络的结构及算法
这得从神经网络的一般结构讲起:
2.1神经网络的一般结构
神经网络单元结构如下:
图2-1神经网络单元结构
对应的计算公式如下:
当向其中间加上一个或多个层次结构时,就形成了神经网络。
LayerL3
LayerL1LayerL2
图2-2含有一个隐含层的神经网络单元结构
其对应的计算公式如下:
由此,可以推广到2个、3个、4个等等含有多个隐含层的神经网络模型。
由上图可知,在图像处理中,如果用像素的向量来表示一张图像,比如一个500×
500像素的图像,可以表示为一个250000的向量。
就有500x500x250000=6.25x10^10个连接,也就是说有6.25x10^10个权值参数,这对于现在的计算机来说这简直是一个天文数字,基本上是没办法训练的。
所以要想利用神经网络来实现图像识别,减少参数成为了重中之重,而卷积神经网络做到了,下面就看看它是怎么做到的。
2.2卷积神经网络的特点
2.2.1局部感受野
对于卷积神经网络来说,有两种方法可以大幅度减少参数的数目,第一种方法称为局部感受野。
全连接方式(左)与局部连接方式(右)的图像对比:
图2-3全连接与局部连接的对比
2.2权值共享
还有一个方法就是权值共享。
在上面的局部连接中,他们与上一层之间的每一个连接是需要附加权值来进行输入的,这些连接中,每个链接的权值如果是任意的,这也将会带来给计算量。
局部连接方式(左)与卷积神经网络连接方式(右)的图像对比:
图2-4局部连接与卷积神经网络连接的对比
2.3降采样
第三章卷积神经网络的MATLAB实现
对于卷积神经网络的MATLAB实现,本文采用的是一个的深度学习的MATLAB包——deepLearnToolbox-master,该MATLAB包的作者是RasmusBergPalm。
(rasmusbergpalm@)里面包含了卷积神经网络的主要代码为:
test_example_CNN;
cnnsetup.m;
cnntrain.m;
cnnff.m;
cnnbp.m;
cnnapplygrads.m;
cnntest.m
各程序调用关系:
cnnsetup.mcnnff.m
test_example_CNNcnntrain.mcnnbp.m
cnntest.mcnnapplygrads.m
图3-2各程序调用关系
3.1CNN的初始化:
cnnsetup.m就是CNN初始化的过程,它主要设置学习特征的卷积核权值、偏置等等
ifstrcmp(net.layers{l}.type,'
s'
),如果是降采样层;
降采样层是没有卷积核的,只是一个降采样的操作,mapsize=mapsize/net.layers{l}.scale,即将上一层得到的featuremap的长宽变为上一层卷积层featuremap的一半;
net.layers{l}.b{j}=0;
将偏置初始化0,
ifstrcmp(net.layers{l}.type,'
c'
),如果是卷积层,则计算出卷积核的输入输出连接数fan_in和fan_out,由它们初始化卷积核权值为[-1,1]的随机数,net.layers
{l}.k{i}{j}=(rand(net.layers{l}.kernelsize)-0.5)*2*sqrt(6/(fan_in+fan_out));
并初始化偏置为0,net.layers{l}.b{j}=0;
3.2CNN训练过程
先把60000个训练数据分成1200批(batch),每个batch为50个训练图像数据。
再randprem(),随机打乱序列,计算这50个训练样本与实际值的误差,更新到模型中。
在批训练过程中:
Cnnff.m前向传播阶段,Cnnbp.m计算误差并完成反向传播过程,Cnnapplygrads.m完成权重修改,更新模型的功能。
cnnff.m是完成前向传播过程:
),如果是卷积层,由算法得到featuremap层(第一个featuremap层为50x24x24,第二个为50x8x8)结果。
elseifstrcmp(net.layers{l
}.type,'
),如果是降采样层,就是简单的将featuremap的像素大小减为原来的1/4,从而减小与下一层的连接数,但是其特征没有改变。
然后,把最后一层得到的结果全连接成为一个192*50的特征向量;
net.o=sigm(net.ffW*net.fv+repmat(net.ffb,1,size(net.fv,2))),通过sigmoid(W*X+b)归一化,得到网络的最终输出值net.o,注意是同时计算了batchsize(50)个样本的输出值。
cnnbp.m计算误差并完成反向传播过程。
如果本层是卷积层,先从它的后一层即降采样层把误差传过来,采用从后往前均摊的方式传播误差,上层误差内摊2倍,再除以4。
如果本层是降采样层,先把它的后一层即卷积层把误差传过来,这里的误差传播实际是用卷积的反向过程,即反卷积。
cnnapplygrads.m该子函数程序就是对cnnbp.m中权值和偏置的修改,完成模型功能更新。
先更新卷积层的权重和偏置,再更新全连接层的权重和偏置。
3.3测试过程。
cnntest.m就是输入测试数据,验证测试样本的准确率
net=cnnff(net,x);
%前向传播得到输出
[~,h]=max(net.o);
%找到最大的输出对应的标签
[~,a]=max(y);
%找到最大的期望输出对应的索引
bad=find(h~=a);
%找到他们不相同的个数,也就是错误的次数
er=numel(bad)/size(y,2);
%计算错误率
第四章卷积神经网络的手写数字识别
3.1MNIST手写数字数据集
MNIST手写数字数据集来自于Google实验室的CorinnaCortes和纽约大学柯朗研究所的YannLeCun之手,训练库有60,000张来自于大约250个不同个体的手写数字图像,测试库有10,000张。
MNIST数据集中都是用灰度矩阵来表示图像的,图像像素大小为28x28,且都经过了尺寸标准化和中心化[8]。
3.2应用于MNIST手写数字数据集检测的CNN
有了上面的子程序,接下来就是部署test_example_CNN主程序:
加载MNIST手写数字数据集并初始化:
loadmnist_uint8;
train_x=double(reshape(train_x'
28,28,60000))/255;
%训练集变成60000张28*28的图片大小28*28*60000,像素点归一化到[0,1]
test_x=double(reshape(test_x'
28,28,10000))/255;
%对测试集进行相同操作
接下来设置CNN主要结构:
cnn.layers={
struct('
type'
'
i'
)%inputlayer
outputmaps'
6,'
kernelsize'
5)%convolutionlayer
scale'
2)%subsamplinglayer
12,'
2)%subsamplinglayer
};
也就是说CNN的结构为5层,一个输入层、两个卷积层和两个降采样层,实验将会对28x28的输入图像与学习特征的6个5x5的卷积核卷积得到6个24x24的featureMap1,再通过降采样1得到6个12x12的subFeatureMap1,在由第三层的卷积2得到12个8x8的featureMap2,再降采样2得到12个4x4的subFeatureMap2的,再展开,在尾部单层感知机中全连接得到结果。
其网络结构图形为:
6*featureMap16*subfeatureMap112*featureMap212*subfeatureMap2196全连接10
8x84x4展开1
24x2412x122
8x84x4…
8x84x4展开16
24x2412x1217
8x84x432
24x2412x12
8x84x4
28x288x84x4
24x2412x12
input8x84x4
8x84x4
24x2412x128x84x4
8x84x4192
卷积1降采样1卷积2降采样2单层感知机
训练过程就是将单层感知机的10个输出(0-9),
3.3MATLAB运行结果
如上图,该图为训练时的net.rl参数变化图。
本参数实为代价函数,也就是误差值,目的是为了指出真实值y与拟合值h之间的距离,然后这是它的最小均方根误差,可以看到,60000个训练数据,50个数据一个的batchsize,所以一次迭代为1200次,上图为10次迭代的结果,曲线在12000时,误差值已经非常小了,这说明训练实验得到了比较好的结果。
下面的是测试时的错误率:
[~,h]=max(net.o);
[~,a]=max(y);
bad=find(h~=a);
er=numel(bad)/size(y,2);
10000/50=200,此时的错误率为:
0.3524这是一次迭代的结果,
第五章卷积神经网络在人脸识别上的应用
人脸识别利用计算机是指将人脸的特征信息提取出来并且通过对这些信息的处理来实现对人脸的分类识别。
目前有很多人员领域在研究人脸识别,但是人脸数据采集是一个很大的问题。
因此,很多研究人员就创建了一个个的人脸数据库来方便研究。
4.1ORL人脸数据库
由剑桥大学AT&
T实验室创建的ORL人脸数据是一个人们的比较全面的数据库,该库由大约40个来自全世界各个不同的地方的人的面部图像组成,每个人录有10张图像资源,这些图像资源甚至还包括了面部表情的变化,所以这对于实验数据的随机性有所保证。
为了方便本实验进行训练和测试,将对原始图像进行归一化处理以适配本文所采用的卷积神经网络结构,并且每个个体中,把前5幅作为训练样本,后5幅为测试的样本,即200个训练数据,剩下200个作为测试数据。
4.2应用于ORL人脸数据库的CNN结构
有上面MNIST字符集检测的启发,ORL人脸数据库的训练测试过程与其差不多,故这里不再累赘,但还是有一些不同的:
1、test_example
 升级会员
升级会员 