主成分因子分析步骤文档格式.docx
《主成分因子分析步骤文档格式.docx》由会员分享,可在线阅读,更多相关《主成分因子分析步骤文档格式.docx(9页珍藏版)》请在冰豆网上搜索。
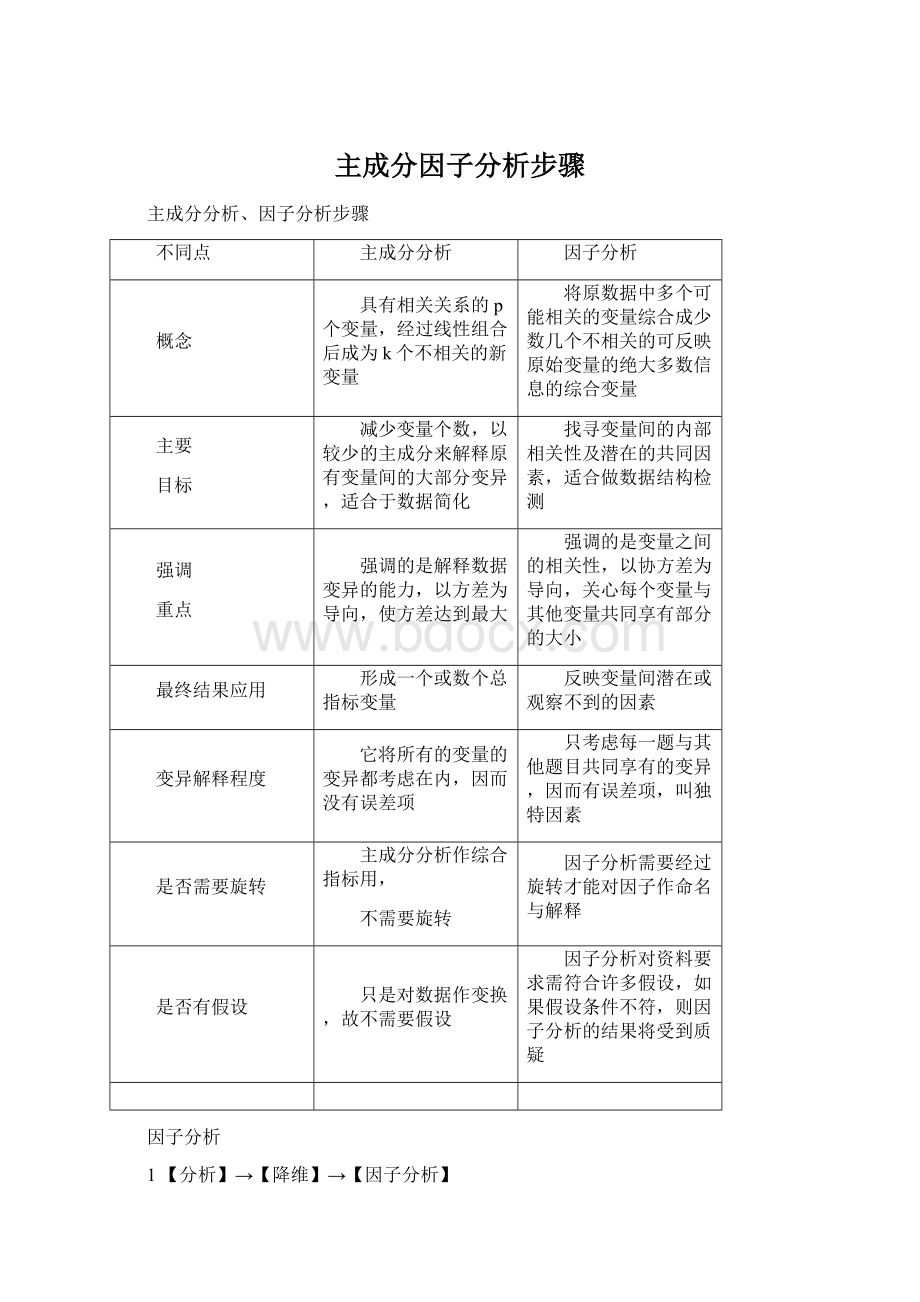
只是对数据作变换,故不需要假设
因子分析对资料要求需符合许多假设,如果假设条件不符,则因子分析的结果将受到质疑
1【分析】→【降维】→【因子分析】
(1)描述性统计量(Descriptives)对话框设置
KMO和Bartlett的球形度检验(检验多变量正态性和原始变量是否适合作因子分析)。
(2)因子抽取(Extraction)对话框设置
方法:
默认主成分法。
主成分分析一定要选主成分法
分析:
主成分分析:
相关性矩阵。
输出:
为旋转的因子图
抽取:
默认选1.
最大收敛性迭代次数:
默认25.
(3)因子旋转(Rotation)对话框设置
因子旋转的方法,常选择“最大方差法”。
“输出”框中的“旋转解”。
(4)因子得分(Scores)对话框设置
“保存为变量”,则可将新建立的因子得分储存至数据文件中,并产生新的变量名称。
(5)选项(Options)对话框设置
2结果分析
(1)KMO及Bartlett’s检验
KMO和Bartlett的检验
取样足够度的Kaiser-Meyer-Olkin度量。
.515
Bartlett的球形度检验
近似卡方
3.784
df
6
Sig.
.706
当KMO值愈大时,表示变量间的共同因子愈多,愈适合作因子分析。
根据Kaiser的观点,当KMO>0.9(很棒)、KMO>0.8(很好)、KMO>0.7(中等)、KMO>0.6(普通)、KMO>0.5(粗劣)、KMO<0.5(不能接受)。
(2)公因子方差
公因子方差
起始
撷取
卫生
1.000
.855
饭量
.846
等待时间
.819
味道
.919
亲切
.608
撷取方法:
主体元件分析。
Communalities(称共同度)表示公因子对各个变量能说明的程度,每个变量的初始公因子方差都为1,共同度越大,公因子对该变量说明的程度越大,也就是该变量对公因子的依赖程度越大。
共同度低说明在因子中的重要度低。
一般的基准是<
0.4就可以认为是比较低,这时变量在分析中去掉比较好。
(3)解释的总方差
说明的变异数总计
元件
各因子的特征值
因子贡献率
因子累积贡献率
总计
变异的%
累加%
1
2.451
49.024
2.042
40.843
2
1.595
31.899
80.923
2.004
40.079
3
.662
13.246
94.168
4
.191
3.823
97.992
5
.100
2.008
100.000
第二列:
各因子的统计值
第三列:
各因子特征值与全体特征值总和之比的百分比。
也称因子贡献率。
第四列:
累积百分比也称因子累积贡献率
第二列统计的值是各因子的特征值,即各因子能解释的方差,一般的,特征值在1以上就是重要的因子;
第三列%是各因子的特征值与所有因子的特征值总和的比,也称因子贡献率;
第四列是因子累计贡献率。
如因子1的特征值为2.451,因子2的特征值为1.595,因子3,4,5的特征值在1以下。
因子1的贡献率为49.0%,因子2的贡献率为31.899%,这两个因子贡献率累积达80.9%,即这两个因子可解释原有变量80.9%的信息,因而因子取二维比较显着。
至此已经将5个问项降维到两个因子,在数据文件中可以看到增加了2个变量,fac1_1、fac2_1,即为因子得分。
(4)成分矩阵与旋转成分矩阵
成分矩阵是未旋转前的因子矩阵,从该表中并无法清楚地看出每个变量到底应归属于哪个因子。
旋转后的因子矩阵,从该表中可清楚地看出每个变量到底应归属于哪个因子。
此表显示旋转后原始的所有变量与新生的2个公因子之间的相关程度。
一般的,因子负荷量的绝对值0.4以上,认为是显着的变量,超过0.5时可以说是非常重要的变量。
如味道与饭量关于因子1的负荷量高,所以聚成因子1,称为饮食因子;
等待时间、卫生、亲切关于因子2的负荷量高,所以聚成因子2,又可以称为服务因子。
(5)因子得分系数矩阵
元件评分系数矩阵
-.010
.447
.425
-.036
-.038
.424
.480
.059
-.316
-.371
转轴方法:
具有Kaiser正规化的最大变异法。
元件评分。
因子得分系数矩阵给出了因子与各变量的线性组合系数。
因子1的分数=-0.010*X1+0.425*X2-0.038*X3+0.408*X4-0.316*X5
因子2的分数=0.447*X1-0.036*X2+0.424*X3+0.059*X4-0.371*X5
(6)因子转换矩阵
元件转换矩阵
.723
-.691
.691
因子转换矩阵是主成分形式的系数。
(7)因子得分协方差矩阵
元件评分共变异数矩阵
.000
看各因子间的相关系数,若很小,则因子间基本是两两独立的,说明这样的分类是较合理的。
1【分析】——【降维】——【因子分析】
(1)设计分析的统计量
【相关性矩阵】中的“系数”:
会显示相关系数矩阵;
【KMO和Bartlett的球形度检验】:
检验原始变量是否适合作主成分分析。
【方法】里选取“主成分”。
【旋转】:
选取第一个选项“无”。
【得分】:
“保存为变量”
【方法】:
“回归”;
再选中“显示因子得分系数矩阵”。
(1)相关系数矩阵
相关性矩阵
食品
衣着
燃料
住房
交通和通讯
娱乐教育文化
相关
.692
.319
.760
.738
.556
-.081
.663
.902
.389
-.089
-.061
.267
.831
.387
.326
两两之间的相关系数大小的方阵。
通过相关系数可以看到各个变量之间的相关,进而了解各个变量之间的关系。
由表中可知许多变量之间直接的相关性比较强,证明他们存在信息上的重叠。
(2)KMO及Bartlett’s检验
KMO与Bartlett检定
Kaiser-Meyer-Olkin测量取样适当性。
.602
Bartlett的球形检定
大约卡方
62.216
15
显着性
(3)公因子方差
Communalities
.878
.825
.841
.810
.584
(4)解释的总方差:
起始特征值
撷取平方和载入
3.568
59.474
1.288
21.466
80.939
.600
10.001
90.941
.358
5.975
96.916
.142
2.372
99.288
.043
.712
(5)成分矩阵(因子载荷矩阵)
元件矩阵a
.255
.880
-.224
.093
.912
-.195
.925
-.252
.588
.488
a.撷取2个元件。
该矩阵并不是主成分1和主成分2的系数。
主成分系数的求法:
各自主成分载荷向量除以主成分方差的算数平方根。
则第1主成分的各个系数是向量(0.925,0.902,0.880,0.878,0.588,0.093)除以
后才得到的,即(0.490,0.478,0.466,0.465,0.311,0.049)才是主成分1的特征向量。
第1主成分的函数表达式:
Y1=0.490*Z交+0.478*Z食+0.466*Z衣+0.465*Z住+0.311*Z娱+0.049*Z燃
(6)因子得分
因子得分显示在SPSS的数据窗口里。
通过因子得分计算主成分得分。
(7)主成分得分
主成分的得分是相应的因子得分乘以相应方差的算数平方根。
即:
主成分1得分=因子1得分乘以3.568的算数平方根
主成分2得分=因子2得分乘以1.288的算数平方根
【转换】—【计算变量】
(8)综合得分及排序
综合得分是按照下列公式计算:
综合得分Y为:
【数据】——【排序个案】
 升级会员
升级会员 