第四章 数据分析梅长林习题答案Word文档下载推荐.docx
《第四章 数据分析梅长林习题答案Word文档下载推荐.docx》由会员分享,可在线阅读,更多相关《第四章 数据分析梅长林习题答案Word文档下载推荐.docx(13页珍藏版)》请在冰豆网上搜索。
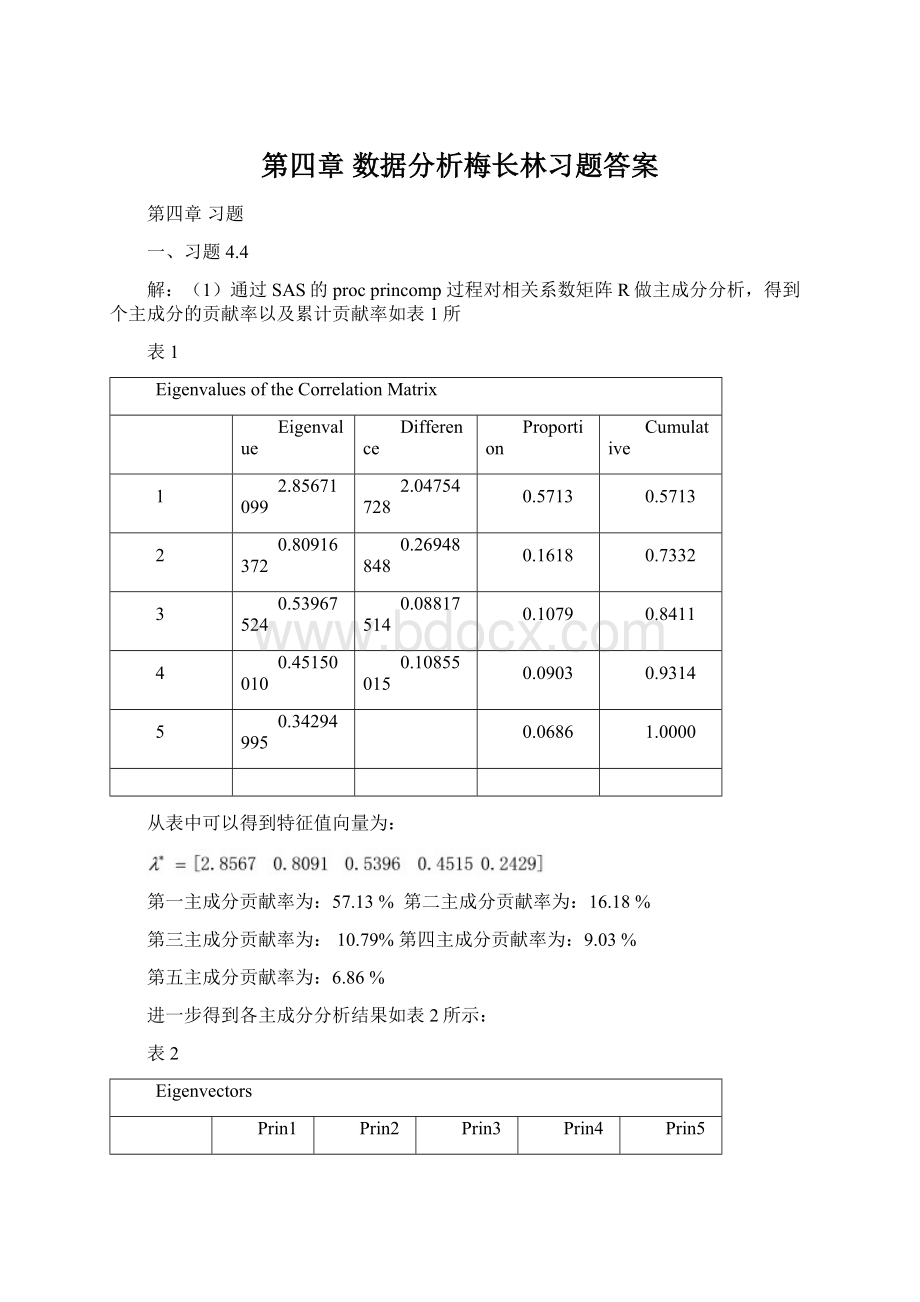
0.386635
-.451262
x2
0.457108
-.509305
0.178189
0.206474
0.676223
x3
0.470176
-.260448
0.335056
-.662445
-.400007
x4
0.421459
0.525665
0.540763
0.472006
-.175599
x5
0.421224
0.581970
-.435176
-.382439
0.385024
(2)由
(1)中得到的结果可知前两个主成分的累积贡献率为73.32%,得到第一主成分、第二主成分为:
由于
是五个标准化指标的加权和,由此第一主成分更能代表三种化工股票和两种石油股票周反弹率的综合作用效果,
越大表示各股票的综合周反弹率越大。
中关于三种化工股票的周反弹率系数为负,而关于两种石油的系数为正,它放映了两种石油周反弹率和三种化工股票周反弹率的对比,
的绝对值越大,表明两种石油周反弹率和三种化工股票周反弹率的差距越大。
二、习题4.5
(1)利用SAS的proccorr过程求得相关系数矩阵如表3:
表3
CorrelationMatrix
x6
x7
x8
0.3336
-.0545
-.0613
-.2894
0.1988
0.3487
0.3187
-.0229
0.3989
-.1563
0.7111
0.4136
0.8350
0.5333
0.4968
0.0328
-.1391
-.2584
0.6984
0.4679
-.1713
0.3128
0.2801
-.2083
-.0812
0.4168
0.7016
(2)从相关系数矩阵出发,通过procprincomp过程对其进行主成分分析,表4给出了各主成分的贡献率以及累积贡献率:
表4
3.09628829
0.72906522
0.3870
2.36722307
1.44723572
0.2959
0.6829
0.91998735
0.21406199
0.1150
0.7979
0.70592536
0.20748303
0.0882
0.8862
0.49844233
0.26855403
0.0623
0.9485
6
0.22988831
0.09911254
0.0287
0.9772
7
0.13077577
0.07930623
0.0163
0.9936
8
0.05146954
0.0064
38.70%第二主成分贡献率为:
29.59%
11.50%第四主成分贡献率为:
8.82%
6.23%第六主成分贡献率为:
2.87%
其中前两个主成分的累计贡献率为68.29%
(3)通过上面的计算得到各主成分,见表5:
表5
Prin6
Prin7
Prin8
0.249607
-.241238
0.693918
-.376770
0.502313
-.018418
-.036543
0.045052
0.519234
-.037607
-.071261
-.224871
-.424453
0.001760
-.282467
0.642950
-.018480
0.475439
0.577819
0.032379
-.510472
-.173344
0.381416
-.050854
0.254092
0.538081
-.021777
-.231066
0.010358
0.399113
-.471680
-.458432
0.021695
0.575449
-.048087
0.285368
0.516270
0.146109
0.159192
0.520977
0.492663
0.134676
-.145348
0.224222
0.177156
-.754966
-.081452
-.244442
0.317147
-.260682
0.286391
0.768116
-.090759
0.355165
-.130720
-.089297
0.509332
-.087081
-.271279
-.176990
0.026015
0.304720
0.708416
-.180821
由于是
八个标准化标值的加权值,因此它反映了平均消费数据的综合指标。
对于Y1,它反映了各省人均消费水平,除烟茶酒外,其他支出越高,其人均总体消费水平越高,而烟茶酒对其消费水平评价成反方向。
在Y2中人均粮食,人均副食品,人均燃料,人均非商品的系数为负;
人均烟茶酒、人居其他副食、人均衣着、人均日用品系数为正,说明Y2的绝对值越大,各省人均消费的在生活必需品与高档品差异越大。
根据第一主成分的得分对各个省份进行排序,见表6:
表6
Obs
location
广东
6.89591
16
宁夏
-0.43040
上海
3.24842
17
湖南
-0.51802
北京
1.79214
18
陕西
-0.61274
浙江
1.51507
19
云南
-0.66670
海南
1.40116
20
新疆
-0.81850
福建
1.15390
21
青海
-1.11335
广西
1.05651
22
安徽
-1.11496
天津
0.43543
23
甘肃
-1.18223
9
江苏
0.15329
24
内蒙古
-1.25819
10
辽宁
0.04520
25
贵州
-1.25934
11
西藏
-0.13324
26
吉林
-1.29370
12
四川
-0.13489
27
黑龙江
-1.32567
13
山东
-0.14112
28
河南
-1.48595
14
湖北
-0.17044
29
山西
-1.68448
15
河北
-0.39220
30
江西
-1.96091
三、习题4.6
(1)通过SAS的procprincomp过程计算得到样本协方差矩阵见表7:
表7
CovarianceMatrix
y1
y2
y3
97.3333333
17.8095238
12.0297619
58.7202381
22.3511905
61.5297619
74.5799320
14.2185374
3.3261054
61.6215986
-3.8558673
76.9693878
41.6675170
31.2185374
66.1092687
779.1539116
310.1594388
192.4234694
510.0799320
156.1857993
485.3324830
求得协方差矩阵的特征值以及各样本主成分的贡献率、累计贡献率结果如表8:
表8
EigenvaluesoftheCovarianceMatrix
1097.39817
699.40213
0.5423
397.99604
84.89703
0.1967
0.7390
313.09901
213.35419
0.1547
0.8938
99.74482
29.62682
0.0493
0.9431
70.11800
25.02504
0.0347
0.9777
45.09295
0.0223
从以上结果可看出前三个主成分贡献率已占89.38%,大于剩下三个成分的总和,已包含原始数据的大量信息,所以保留前三个主成分即可。
(2)通过SAS的procprincomp过程对其相关系数矩阵进行主成分分析,首先得到相关系数矩阵见表9:
表9
0.2090
0.1390
0.2132
0.1003
0.2831
0.1877
0.0138
0.3159
-.0203
0.1701
0.1576
0.3420
0.4920
0.3129
0.3139
求得协方差矩阵的特征值以及各样本主成分的贡献率、累计贡献率结果如表10:
表10
2.12157166
1.03736370
0.3536
1.08420796
0.08624620
0.1807
0.5343
0.99796176
0.12628298
0.1663
0.7006
0.87167877
0.29225146
0.1453
0.8459
0.57942731
0.23427477
0.0966
0.9425
0.34515254
0.0575
从以结果可看出前四个主成分贡献率已占84.59%且第四个主成分的贡献率都占到总信息量的的14.53%,与剩下两个成分的总和差不多,所以保留前四个主成分即可。
我认为基于协方差矩阵S的分析结果更合理。
因为由协方差矩阵
输出结果可以看出前三个主成分的贡献率就可达到89.38%大于相关系数矩阵R分析得到前四个主成分贡献率总和84.59%,且空腹和摄入食糖的测量数据量纲相等无需进行标准化数据,所以基于协方差矩阵S的分析结果更为合理。
四、习题4.8
(1)通过proccancorr过程求得以下结果:
表11
Canonical
Correlation
Adjusted
Approximate
Standard
Error
Squared
Eigenvalues
of
Inv(E)*H
=
CanRsq/(1-CanRsq)
0.397112
0.396910
0.008423
0.157698
0.1872
0.1819
0.9723
0.072889
.
0.009947
0.005313
0.0053
0.0277
两个特征值分别为
计算得到各典型变量系数见表下表:
StandardizedCanonicalCoefficientsfortheVARVariables
V1
V2
1.2478
0.3180
-1.0330
0.7687
StandardizedCanonicalCoefficientsfortheWITHVariables
W1
W2
1.1019
-0.0071
-0.4564
1.0030
所以有
第一对典型变量为:
第一对典型相关系数
;
第二对典型变量为:
第二对典型相关系数
(2)对典型变量进行显著性检验,结果见表12,其中P1=0.001<
0.05,P2=0.001<
0.05,故两对变量都显著相关。
表12
Test
H0:
The
canonical
correlations
in
the
current
row
and
all
that
follow
are
zero
Likelihood
Ratio
F
Value
Num
DF
Den
Pr
>
F
0.83782737
462.33
19992
<
.0001
0.99468712
53.40
9997
五、习题4.9
(1)首先计算得到协方差系数矩阵:
协方差矩阵,自由度=24
95.2933333
52.8683333
69.6616667
46.1116667
54.3600000
51.3116667
35.0533333
100.8066667
56.5400000
45.0233333
进而从协方差系数矩阵计算得到典型变量系数:
RawCanonicalCoefficientsfortheVARVariables
0.0565661954
-0.139971093
0.0707368313
0.1869496027
RawCanonicalCoefficientsfortheWITHVariables
0.0502425983
-0.176147939
0.0802223988
0.2620835635
(2)计算得到样本相关系数矩阵:
从相关系数矩阵出发,进行典型相关变量分析:
0.5522
-1.3664
0.5215
1.3784
0.5044
-1.7686
0.5383
1.7586
第一对典型相关系数为:
第二对典型相关系数为:
因为样本中测量的数据的量纲都是相同的,所以无论是从协方差系数矩阵还是相关系数矩阵进行典型相关分析,得到的结果是一样的。
对典型变量进行显著性检验,结果见表13:
表13
0.37716288
6.60
42
0.0003
0.99711204
0.06
0.8031
取显著水平为0.05,其中第一对典型变量的检验p值为0.003,小于0.05,所以第一对典型变量显著相关,而第二对典型变量的检验p值为0.8031,大于0.05,所以第二对典型变量不是显著相关。
 升级会员
升级会员 