Spark机器学习Word文件下载.docx
《Spark机器学习Word文件下载.docx》由会员分享,可在线阅读,更多相关《Spark机器学习Word文件下载.docx(31页珍藏版)》请在冰豆网上搜索。
●
就是前面给出的预测函数
就是前面给出的Cost函数
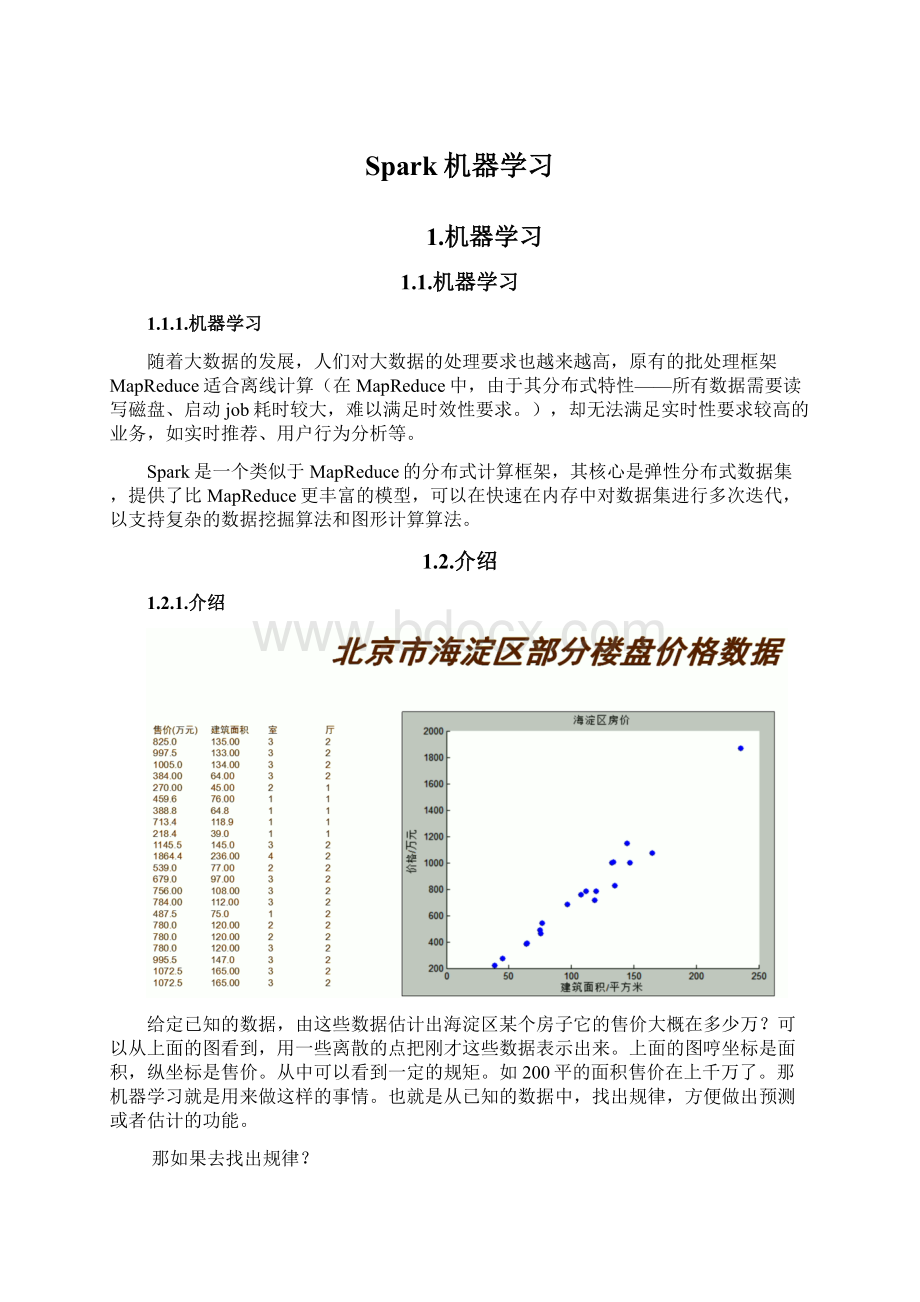
●x是features特征
x0h(x)运行的结果,假定都是1,x1就是样本的数据。
当然我们要考虑的不只是一个点,要考虑所有点,所有有多条,
减去真实的房价
预测值-真实值,然后平方,最后求和
求和完了求平均。
22就是我们的样本数量。
上面计算完,是不就剩下θ0和θ1了。
那我们针对每一组θ0和θ1来计算它的运算结果。
不断改变θ0和θ1的值,看哪个结果最小。
怎么看呢,笨办法也是最有效的办法,就是不断尝试改变θ0和θ1。
如θ0和θ1都是0先试一遍计算的结果是多少,然后θ0改成1,看刚才结果谁小。
如果是小当然好,如果是大,就把这组结果排除,再试下一组。
反正不断的尝试θ0和θ1,让计算的结果最小。
上面这套规则,以及样本数据就称之为模型。
不断尝试改变θ0和θ1的值来求最合适的θ的过程称之为训练模型。
1.2.5.向量化
经过我们讲解,看似很复杂的数学公司,其实也不过带几个参数就可以计算出来,但这样编程还是有些太麻烦。
我们将它转化下,它将用到数学中的向量和乘法。
把x0和x1先变成线性代数中的矩阵,也就相当于java中的数组。
m行样本数,n列特征数(有几列就是看有多少个特征,x0是常量,x1就是建筑面积)将所有的房价抽取成y。
像[x0,x1]的我们称为矩阵,只有一维的y称为向量。
把θ0和θ1也各自抽取成一个矩阵。
这样表示起来也更清晰些,最后编程运算也方便。
java也提供了很多这样的函数,方便矩阵和向量的运算。
这样就将上面的过程表示为一个公式:
●X就是x0和x1的矩阵
●θ就是θ0和θ1的向量
●y就是房价的向量
●最终平方,sum求和,除以2乘样本数
一般数学上大写的是表示矩阵,小写的表示向量。
矩阵*向量时的规则要求:
矩阵的列数=向量的行数,如上面的矩阵有2列,向量的个数有2个。
最后的结果成为一个向量。
加减时,它们的维度都要一样。
上面的结果成为一列,房价是一列,这样才可以加减。
1.3.Octave开源分析工具
1.3.1.介绍
Octave是一个旨在提供与Matlab语法兼容的开放源代码科学计算及数值分析的工具,是Matlab商业软件的一个强有力的竞争产品。
Octave比较小,安装程序只有几十兆;
而Matlab非常庞大,最新版的安装程序大约8G,即使只安装最基本的系统,至少也要几百兆以上。
Matlab之所以那么庞大,是因为有大量的面向各种应用领域的工具箱,Octave无法相比的。
安装完Octave提供两个方式,一种图形化界面GUI,一种命令行CLI。
1.3.2.如何定义矩阵和向量
规则:
用分号分割行,用逗号或者空格分隔列
定义一个矩阵
>
x=[1,2;
3,4]
x=
12
34
定义一个向量
x=[1;
2;
3]
y=
1
2
3
技巧:
不想回显结果在行尾加个分号,结果是相同的。
如果想看X是什么,敲入X就回显。
1.4.常用的函数
1.4.1.ones都是1的矩阵
ones(3,4)
ans=
1111
1.4.2.zeros都是0的矩阵
zeros(3,4)
0000
1.4.3.产生数列
1:
2:
100#规则:
起始值:
步长:
结束值
100#1到100之间的奇数
0:
100#0到100之间的偶数
-100:
10:
100#-100到100之间
q=[1,0.2,2]#产生1到2之间,步长为0.2
注意:
写不写两边的[]都可以
1.4.4.rand随机数矩阵
rand(3,4)产生0到1的随机数
ans=
0.8973130.3792220.6745360.272163
0.8936210.2848860.7295410.479639
0.2671960.0954350.8678660.800308
1.4.5.*矩阵转置
r=rand(3,4)
r’#单撇就代表转置,将之前m*n的矩阵转换为n*m的矩阵
r=rand(3,4)
r=
0.4123140.8106880.7539330.607234
0.7668880.8880160.0177030.380165
0.1070940.5715710.2349390.030356
r'
0.4123140.7668880.107094
0.8106880.8880160.571571
0.7539330.0177030.234939
0.6072340.3801650.030356
1.4.6.获取矩阵行数和列数
size(r)#得到矩阵大小
34
size(r,1)#得到矩阵的行数
ans=3
size(r,2)#得到矩阵的列数
ans=4
y=[1,2,3,4,5]
y=
12345
length(y)#向量的长度
ans=5
1.4.7.读取外部文本文件形成矩阵
文件是按tab键分割,load函数可以自动识别。
也支持逗号和空格分隔。
cdc:
#进入c盘
cdtxt#进入目录
ls#列出当前目录下文件
F=load("
prices.txt"
)#也可以直接指定路径c:
/prices/txt
文件内容多,它会出现这个提示,f向后翻页,d先前翻页,q退出
1.4.8.求矩阵子集
F(:
:
)#所有行,所有列
1)#所有行,第一列
2)#所有行,第二列
2:
4)#所有行,第二列到第四列,总共三列
F(3,:
)#第三行,所有列
F(1:
10,1:
2)#1到10行,1到2列注意:
下标从1开始
现有矩阵和信的矩阵合并
例子1:
x=[1,2,3]
y=[4,5,6]
[x,y]
结果:
1,2,3,4,5,6
y=[4;
5;
6]
14
25
36
x=[1,2,3]
y=[4;
error:
horizontaldimensionsmismatch(1x3vs3x1)
例子2:
c:
/prices.txt"
)读取prices.txt文件,有22行数据
C=ones(22,1)定义一个22行1列的向量C,其值都为1
D=F(:
2)获取房屋面积列,第二列
E=[C,D]将两个向量和在一起,前提行数必须相同,这里都是22行
1.5.集合的运算
1.5.1.矩阵相加
x=[1;
x+y
5
7
9
1.5.2.矩阵相减
x-y
-3
1.5.3.矩阵相乘
要求:
坐边为m*n,右边为n*1的矩阵,结果为m*1的矩阵。
第一个的列数=第二个的行数
x=[12;
34;
56]
y=[2;
4]
x*y
过程:
x中行的元素*对应y列中元素,一行的结果相加
1*2+2*4
3*2+4*4
4*2+4*6
10
22
34
实际之前讲的预测函数就是矩阵相乘的每一行的结果
A=[θo,θ1;
θo,θ1;
θo,θ1]三行数据
B=[Xo;
X1]
第一行:
θo*Xo+θ1*X1
第二行:
第三行:
1.5.4.矩阵每个元素求平方
y=[1;
y.^2#平方
y.^3#立方
注:
在otcave中.代表应用于每个元素之上
1.5.5.矩阵求和
y=[11;
22;
33]
sum(y)
66
sum(y.^2)平方后求和
1414
1.6.房价预测案例
1.6.1.计算预测
X是矩阵,θ是向量,y是向量;
^2就是求平方,在sum求和,最后在除以2倍的m行数,求平均值。
如果使用octave去机器学习,这些公司数学家已经提供,你不需要懂这个公式是什么,你只要明白这种向量格式,然后往里一套就可以了。
会运算就可以,你是要编程,不是要做数学家,要去弄明白公式怎么来的。
只要会套公式就可以。
分析拆解过程:
A=load("
)
ones(22,1)x0
A(:
2)x1取prices.txt中的第二列,房屋面积
[ones(22,1),A(:
2)]X的矩阵,m行,2列
[0;
6]θ0=0,θ1=6,随便指定的预测值
执行过程:
A=load("
);
X=[ones(22,1),A(:
2)];
h=X*[0;
6];
预测值的向量,矩阵相乘结果是22行,1列
y=A(:
1);
真实房价
sum(h-y).^2/(2*22)计算误差值
代码:
sum(h-y).^2/(2*22)
不断的重复上面的过程,不断的改变θ的值
θ1=6,计算结果92498,θ1=7,计算结果5221,θ1=8,计算结果101290
7];
可以看到结果差异巨大,那θ0和θ1可以有无穷组合,那问题就变成怎么找一个θ0,θ1的误差数最小?
1.6.2.调用公式
那我们就要解决如何利用算法得到θ0θ1的值,之前所学的COST函数就发挥作用了。
Z返回值=函数名(参数)
z0就是θ0,给个范围-100~100
z1就是θ1,给个范围-100~100
X就是之前的矩阵
y就是之前的向量
functionZ=costFunction(z0,z1,X,y)
Z=zeros(length(z0),length(z1));
//初始0的集合
m=length(y);
//样本个数
//通过两层循环不断的尝试θ0和θ1的组合
fori=1:
length(z0)
forj=1:
length(z1)
//运算公式,构建了100*100的组合都放在Z(i,j)中
Z(i,j)=sum((X*[z0(i);
z1(j)]-y).^2)/(2*m);
end
end
Z=Z'
;
//单撇矩阵转置
end
octave对中文支持不好,所以源码中不要出现中文
保存成文件放在磁盘上,注意文件名和函数名相同,后缀必须为m。
costFunction.m。
检查代码是否正确,可以先直接到文件所在目录,然后只敲入函数名。
如果语法正确就会提示缺失参数。
调用:
z0=[-200:
300];
//由-200开始,步长为10,到300结束
z1=[2:
0.2:
12];
//由2到12,步长为0.2
J=costFunction(z0,z1,X,y)
执行结果:
这么多结果,如果找到最小的误差呢?
z=costFunction()
这有非常多的结果,怎么看呢?
octave中可以很方便的把它画成图。
x0,x1两个自变量y因变量。
这有3个动态的值,很容易就画成立体图。
plot3(J)//生成3D的图,速度比较慢,稍加等待
1.6.3.梯度下降
如果同时变化θ0和θ1,问题变得复杂,不妨固定其中一个,变化另一个。
比如说,先让θ0=0
z0=zeros(1,51);
J=costFunction(z0,z1,X,y);
plot(z1,J(:
1))
z0都为0了,所以展示时可以看二维的更加直观,忽略z0的值,所以只取J结果集中的第一列。
变成了二维的比三维看着简单多了,可还是老问题,如何求最小值值呢?
求最小值有很多方法,其中一个方法就是梯度下降方法。
这里我们不去探讨数学的问题,也无需弄懂它的推导过程,我们只需记住结论就可以。
我们要找到每次应该减少多少呢?
下次的θ1就应该是
可以乘以一个常量α,来调整下降的速率,这个在机器学习中称为学习速率。
α不能太大。
可能就一下跳过最小值了。
太小也不行,找到最小值的速度就会变慢。
这种找到最小值的方法,就称为梯度下降法,非常形象。
除了这种方法,还可以使用解方程的方式,两种各有优缺点。
解方程的方法,当数据量少的时候,速度快。
解方程就无需α了。
单用梯度下降法就适用数据量特别大的时候。
编程时梯度下降法更加方便。
用java解方程很麻烦。
1.6.4.代码实现
伪代码:
循环很多次,不断的改变θ1,观察J(θ1)的值如果值3000,然后继续循环,还是3000,继续循环,还是3000,不变化了。
就可以认为找到最小值了。
function[z,J_his]=descentFunction(z,X,y,a,iters)
J_his=zeros(iters,1);
%样本数
n=length(z);
t=zeros(n,1);
foriter=1:
iters
fori=1:
n
%变化率
t(i)=(a/m)*(X*z-y)'
*X(:
i);
end;
z(i)=z(i)-t(i);
J_his(iter)=sum((X*z-y).^2)/(2*m);
function[z,J_his]
定义了两个返回值,J_his就是costFunction的结果。
descentFunction(z,X,y,a,iters)
z就是θ,初始值,多少无所谓。
X还是之前的矩阵,y还是之前的向量,a就是学习速率α,决定了计算的速度,α越大循环的次数就越小,α太小就会造成运算速度太慢,太大就可能造成跳过最小值。
iters就代表循环次数,循环多少次去求解。
t(i)=(a/m)*(X*z-y)'
t就代表变化量,X*z就是h预测函数。
因为两边的维度的对上,得跟后面的维度对上,所以做了个转置。
z(i)=z(i)-t(i);
上次的z(i)再减去t(i)变化率,就得到下一次的θ值。
J_his(iter)=sum((X*z-y).^2)/(2*m);
在套入costFunction,看它的结果是不是跟上次结果相比不在变化了。
只要不在变化或者变化微小。
这时我就找到最小值了。
这个算法大家大致明白它的含义,会应用就可以。
因为在spark中它已经替我们实现了。
执行代码:
a=0.0001%事先测试好,这个值比较好
iters=1%循环一次
[z,J]=descentFunction(z,X,y,a,iters)
可以看到J不断在减小,那什么时候是头呢?
观察J的变化越来越微乎其微了,只小数点后发生变化。
1.7.Spark中机器学习
1.7.1.Vector向量
首先要解决怎么把原始数据包装成向量,这些向量其实也是RDD封装实现,在把这些向量分布到集群上然后做运算。
创建向量就要用到Vector。
Vector.dense()创建稠密向量
Vector.dense([1,2,3]);
就创建了123的向量。
在spark中向量都是横着放的。
123,而Octave中是纵的。
什么叫稠密向量呢?
每个元素都要给定。
相对稀疏向量,稀疏向量只给定向量元素不为0的值。
为0的值默认就不给它。
导包
importorg.apache.spark.mllib.regression.LabeledPoint
importorg.apache.spark.mllib.linalg.Vectors
算法
基于线性回归思想解决线性回归的算法SGD
importorg.apache.spark.mllib.regression.LinearRegressionModel
importorg.apache.spark.mllib.regression.LinearRegressionWithSGD
scala>
Vector.dense([1,2,3])
res0:
org.apache.spark.mllib.linalg.Vector=[1.0,2.0,3.0]
稀疏向量用的比较少,它主要为了节约空间。
Vector.sparse(5,Array(0,1),Array(2,3))
第一个参数是元素个数,第二个参数是非零的坐标,第三个参数是非零的值
res2:
org.apache.spark.mllib.linalg.Vector=(5,[0,1],[2.0,3.0])
1.7.2.LabeledPoint
只有先把数据转变成LabeledPoint才能使用spark提供的函数。
结构:
LabledPoint
labley
featruesx1,x2,x3……
定义:
LabeledPoint必须先有有个Vector。
valv=Vector.dense([1,2,3]);
valy=4
vall=LabeledPoint(y,v)
l:
org.apache.spark.mllib.regression.LabeledPoint=(4.0,[1.0,2.0,3.0])
数据:
prices.data
825.0135.0032
997.5133.0032
1005.0134.0032
……
第一列就是y,后面三列就是一个Vector。
valrdd=sc.textFile("
file:
///root/prcies.data"
rdd.first//获取到第一条记录
res6:
String=825.01135.0032
目的就是先要把文本数据变成LabledPoint,它才能进行下一步运算。
valrdd2=rdd.map{x=>
x.split("
\\t"
)}
res7:
Array[String]=Array(825.0,1,135.00,3,2)
valrdd3=rdd2.map{x=>
LabledPoint(x(0).toDouble,Vectors.dense(x
(1).toDouble,x
(2).toDouble))}
rdd3.first
rdd3:
org.apache.spark.mllib.regession.LabledPoint=(825.0,[1.0,135.0])
1.0就相当于θ0,135.0就相当于θ1
1.7.3.train训练
接着把原始数据,将这个RDD做训练,求θ,把任务交给LinearRegressionWithSGD这个函数就行了。
中间这个函数会计算梯度下降,去求那些方程。
就调用train方法,去训练模型,从而解出θ的值。
参数:
数据、迭代次数、学习速率
valmodel=LinearRegressionWithSGD.train(rdd3,1000,0.0001)
它得到的结果就叫一个模型,这个结果就包括了θ的值。
这
 升级会员
升级会员 