基于云的关键技术模板.docx
《基于云的关键技术模板.docx》由会员分享,可在线阅读,更多相关《基于云的关键技术模板.docx(6页珍藏版)》请在冰豆网上搜索。
基于云的关键技术模板
1、AMX技术:
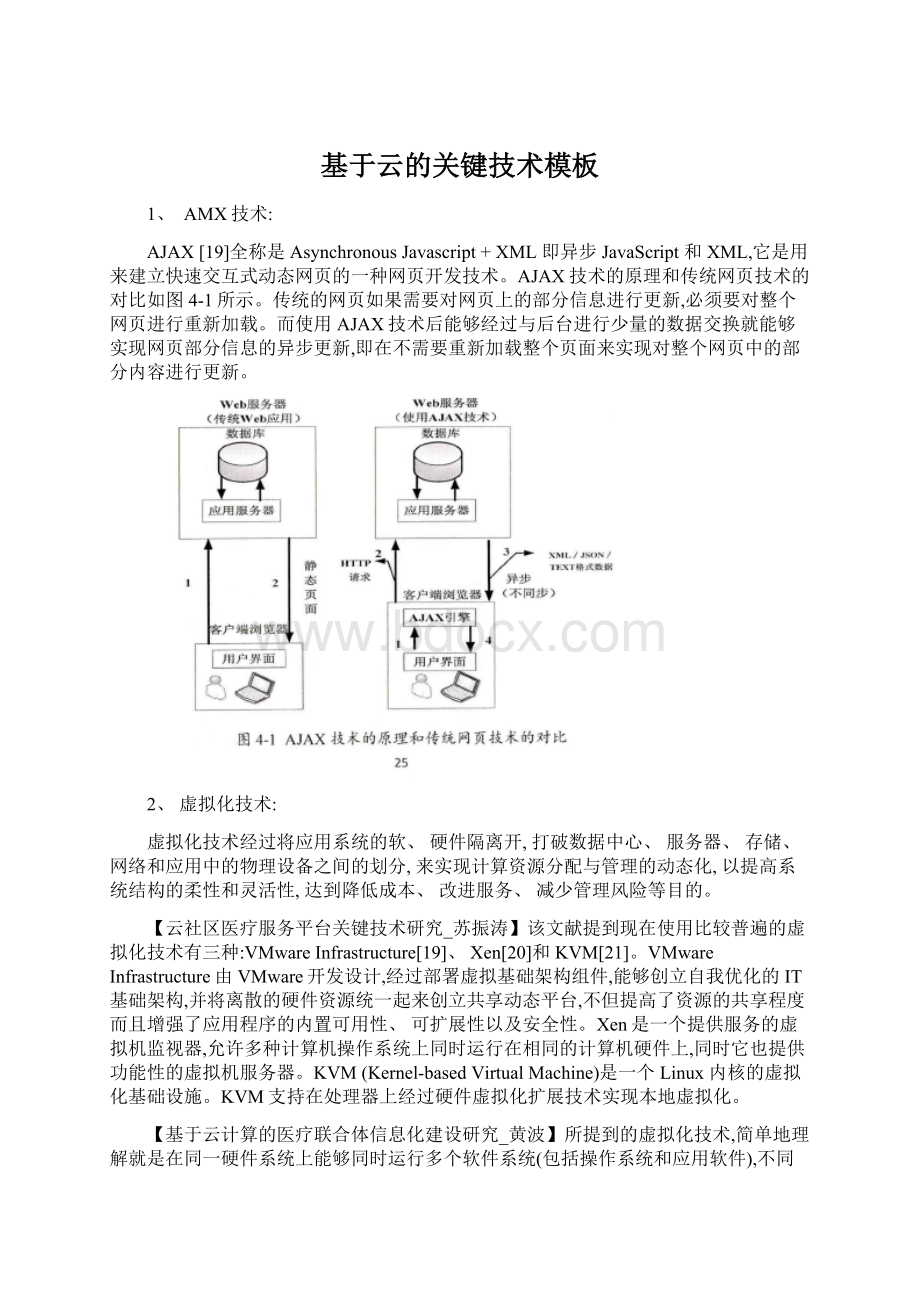
AJAX[19]全称是AsynchronousJavascript+XML即异步JavaScript和XML,它是用来建立快速交互式动态网页的一种网页开发技术。
AJAX技术的原理和传统网页技术的对比如图4-1所示。
传统的网页如果需要对网页上的部分信息进行更新,必须要对整个网页进行重新加载。
而使用AJAX技术后能够经过与后台进行少量的数据交换就能够实现网页部分信息的异步更新,即在不需要重新加载整个页面来实现对整个网页中的部分内容进行更新。
2、虚拟化技术:
虚拟化技术经过将应用系统的软、硬件隔离开,打破数据中心、服务器、存储、网络和应用中的物理设备之间的划分,来实现计算资源分配与管理的动态化,以提高系统结构的柔性和灵活性,达到降低成本、改进服务、减少管理风险等目的。
【云社区医疗服务平台关键技术研究_苏振涛】该文献提到现在使用比较普遍的虚拟化技术有三种:
VMwareInfrastructure[19]、Xen[20]和KVM[21]。
VMwareInfrastructure由VMware开发设计,经过部署虚拟基础架构组件,能够创立自我优化的IT基础架构,并将离散的硬件资源统一起来创立共享动态平台,不但提高了资源的共享程度而且增强了应用程序的内置可用性、可扩展性以及安全性。
Xen是一个提供服务的虚拟机监视器,允许多种计算机操作系统上同时运行在相同的计算机硬件上,同时它也提供功能性的虚拟机服务器。
KVM(Kernel-basedVirtualMachine)是一个Linux内核的虚拟化基础设施。
KVM支持在处理器上经过硬件虚拟化扩展技术实现本地虚拟化。
【基于云计算的医疗联合体信息化建设研究_黄波】所提到的虚拟化技术,简单地理解就是在同一硬件系统上能够同时运行多个软件系统(包括操作系统和应用软件),不同的软件系统由同一个调度器,即VirtualMachineMonitor(VMM,虚拟机监视器)来调度底层的硬件资源,从而实现多个系统对同一硬件资源的共享。
随着业界对服务器资源管理要求的提升,IT厂商(包括IBM、Orack、VMware、微软等)在此前只在支持单台服务器虚拟化的VMM的基础上增加了高一级的管理平台,使之能够同一管理多台物理服务器上的VMM,进而决定虚拟机的部署位置、实现虚拟机规模的缩放和在不同物理服务器之间迁移虚机等,构成了新的资源架构,并随着云计算的推进在最近几年获得了快速的发展。
3、存储与管理技术
(1)云计算的数据存储系统主要有Google GFS[18]和Hadoop开发团队开发的开源系统HDFS。
为保证高可用、高可靠和经济性,GFS和HDFS都采用分布式存储的方式来存储数据。
另外,云计算系统需要同时满足大量用户的需求,并行地为大量用户提供服务。
因此,云计算的数据存储技术必须具有高吞吐率和高传输率的特点。
云计算的数据存储技术未来的发展将集中在超大规模的数据存储、数据加密和安全性保证以及继续提高I/O速率等方面。
(2)存储技术
A、【基于云计算的区域医疗信息系统的构建研究_王惠品】中所提的HDFS存储技术是HadoopDistributedFileSystem分布式文件系统的缩写。
HDFS是Hadoop平台的基石。
设计之初主要适合于成本低廉的机器上,而且当系统出现故障时,系统具有自动纠错的能力,避免出现系统不可用的状态。
同时它适合存储规模大的数据集。
作为Hadoop平台的两大部件之一,其地位十分重要。
下面就HDFS的相关知识做进一步介绍。
HDFS是一个主从式架构,一般情况下,一个HDFS集群具有三个部分:
一个NameNode(元数据节点)、一个SecondaryNode(从元数据节点)和多个DataNode(数据节点)。
它的整体体系结构如图3-1所示:
NameNode是HDFS集群的中心服务节点,它在集群中具有重要的作用,
NameNode的主要功能包括:
①负责管理文件系统的命名空间,NameNode不需要实际存储数据,只保存相关信息;②记录和维护文件数据块在不同节点上的位置信息。
当系统启动后,存储文件数据的节点经过心跳的机制向NameNode汇报。
SecondaryNameNode的主要功能是将NameNode的命名空间镜像文件和修改日志合并,目的是控制日志文件不能过大,在合并的过程中,也将镜像文件也在从元数据节点中保存了一份,在当NameNode节点失效时,能够经过从元数据节点恢复数据。
可是由于SecondaryNameNode是周期性的合并,即使能恢复的元数据副本也不是最新版本,因此Hadoop集群依然存在着单点故障的问题,为了解决这个问题,能够根据实际数量的大小和业务的复杂度来设置多NameNode节点。
DataNode是HDFS中数据实际存放的地方,DataNode的任务:
定期向NameNode汇报节点存储的信息;满足用户经过元数据节点NameNode向DataNode发出读写数据块的操作。
在数据读取的过程中,NameNode即所谓的名称节点并不参与数据的实际传输Hadoop中的高可靠性保障之一就是HDFS的高可靠性,主要由以下核心机制来实现:
冗余副本:
一般情况下似乎是有浪费之嫌,然而在HDFS这种分布式存储系统中为了保障高可靠性,这种冗余是非常值得,优大于过。
这里的冗余主要是指数据块的备份或复制,是将服务器上的一个大文件,经过数据分块策略,分成很多小的文件数据块,然后将这些分割好的文件块存储在不同机架的不同子数据节点上,这些小的文件块并不只是存储在一份,而是有很多个副本。
数据容错:
为了保证数据容错功能,最笨拙的方式是将数据块的多副本存储。
容错,顾名思义,当存储在磁盘上的文件块损坏时,文件块的内容可能会出错,那么一旦错误发生了,HDFS会尝试用其它副本提供的相同文件块,同时更新损坏的文件块。
数据节点也会定时检查各自负责的文件块,跟踪和定位错误的位置。
为了更好的实现容错功能,HDFS中的数据副本的布局是能够动态选择,以供使用者掌控数据的布局。
HDFS采用副本冗余存储的策略能够很好的保障系统的安全性,同时也体现了负载均衡的效用。
心跳机制:
心跳机制也是HDFS的非常重要的一项技术。
它的工作过程如下:
①NameNode周期性从DataNode接收心跳信号以及blockreport(块报告)。
②NameNode根据块报告来验证元数据。
③没接收到心跳信号的子节点被认为宕机,系统不再给它分配I/O请求。
校验和:
在数据块刚幵始建立的时候系统会自动产生一个校验和,而且将它保存在在命名空间中作为一个隐藏文件。
一旦客户端获取数据,就会对数据块进行一个校验,而且检查校验和与文件建立的时候的校验和是否相同,从而判断数据库有没有损坏。
客户端在读取数据时,当发现当前数据块损坏时会自动去读取文件数据块的其它副本。
B、【基于云计算的医院信息技术平台的构建与研究_许敏】提出海量数据分布式存储技术。
数据存储核心技术指标主要包括存储容量、响应速度、可靠性、稳定性和可扩展性。
云计算平台服务对象数量众多、信息数据量庞大,因此必须具备较高的数据处理能力和存储能力。
分布式存储技术的核心思想是将数据分散存放在多台独立存储设备上,并经过冗余存储的方式来保证数据的安全性,采用这种动态可扩展的系统架构,不但提高了系统的可靠性、可用性、存取效率,还易于扩展满足存储空间几何式增长需求。
存储系统是云计算架构中最关键的部件之一,在系统性能和可扩展性方面起着重要的作用,当前可用的存储架构主要有直连式存储(DAS)、网络附加存储(NAS)、和存储区域网络(SAN)等。
直连式存储依赖服务器主机操作系统进行数据的10读写和存储维护管理,数据备份和恢复需要占用服务器主机资源(CPU、系统10等),其存储的数据量越大,备份和恢复的时间就越长,对服务器硬件的依赖性和影响就越大,而且不易扩展,很难满足云平台庞大信息系统对性能的要求。
网络附加存储和存储区域网络的基本原理是将数据存储与服务器分离,利用专门的硬件控制器进行集中管理,其本质是存储与计算的分离。
云计算的数据存储系统其实是一个具备在性能、伸缩性和可靠性上较大优势的分布式文件系统,能应对变化着的性能需求,能够根据业务的变化需求做到存储资源的动态随需响应,为数据提难了多级保护,为不同时区的用户提供全天候的高可用性
(3)HBase数据管理【基于云计算的区域医疗信息系统的构建研究_王惠品】
HBase在集群中完成管理数据的工作主要经过HRegion、HMaster、HClient三部分之间密切的配合。
HMaster:
由于HBase也是主从式的架构,因此需要一台主服务器,称之为HMaster,在一个分布式集群中一般只布置一台HMaster,由Zookeeper的领导选举算法来来保证唯一的Master是运行的。
在Zookeeper中保存着HMaster及备选的主服务器的地址信息,当出现主服务器瘫痪的情况时,为了不影响系统的可用性,系统经过领导选取的算法从备用服务器中选出新的合适的主服务器来代替瘫痪的主服务器,来保证总有一台Master是运行的,这一点很重要。
HMaster的功能主要有初始化HBase分布式集群,当主服务器启动后,从HDFS获取根域目录信息,如果没有成功获取到所需信息,HMaster将自己创立出根或者根域目录,另外主服务器还负责管理用户对Table的增、删、改、查数据操作,以及集群中域的分配,对于所有的域服务器的运行情况起到一个监控的作用等等。
HRegionServer:
域服务器是HBase中最核心的模块,用来管理一系列的域,主要负责处理用户的读写请求,向HDFS文件系统读写数据。
每个域由一台域服务器来管理,域服务器幵始工作:
第一步读取HDFS中该域的日志及存储文件;第二步管理一些HDFS文件上的存储操作;第三步客户端在成功获得域服务器的信息后,能够和域服务器交流,发送域读写请求。
HBaseClient:
HBase客户端经过HBase中的HMaster记录的域服务器信息,获取到根域的地址信息,然后连接根域所在的服务器,获取元域信息,经过元域信息,请求获取所在域的域服务器信息,然后经过定、位所在域服务器,发出读写的请求。
经过步步定位、寻址、发送请求,完成一系列的读写操作。
HBase分布式集群经过三大件:
主服务器、域服务器和客户端三部分实现复杂的大数据管理过程。
建立严格的层级制度呈树形结构往下层管理。
主服务器的主要任务是管理着分布式的集群中所有的域,监控域服务器的工作状态等,是HBase成功运行的保证;域服务器面向的是用户,负责处理用户发来的各种读写请求并完成向HDFS文件系统读写数据的过程等;客户端主要的目标是一步步寻址定位到所在的域服务器,然后发送读写请求。
数据的读写:
当客户端发出写入操作的请求时,服务器首先将请求交给HRegionServer来响应,HRegionServer定位到对应的Region,系统将客户端提交写入的数据存放在MemStore中,与此同时为了防止Master岩机导致的数据丢失,再在HLog文件中再写一份数据,当MemStore中存满了数据,将文件Flush成一个StoreFile文件。
当StoreFile文件增长到一之前设定好的值称之为阀值时,会触发服务器进行Compact合并文件的操作,将多个StoreFile合并为一个越来越大的StoreHle文件。
合并后的StoreFile文件越来越大,超过一个设定好的值时,触发服务器进行Split分裂操作,将当前的Region—分为二。
与此同时,将新Split分解出的两个子Region分配到对应的域服务器上分别管理,完成整个合并分解的操作。
这样经过Compact操作和Split操作分解了原来Region的压力,用户的写的数据只需要和Mem
 升级会员
升级会员 